Reprenons la série sur la finance comportementale avec un autre type d’effet calendaire un peu plus original.
Le(s) papier(s) d’origine
Revenons ici sur une anomalie un peu plus exotique et surtout détectée plus récemment. Il s’agit de la tendance qu’aurait les rendements journaliers des actions à évoluer en fonction du cycle lunaire. Il y aurait ainsi des rendements en moyenne plus faibles autour de la pleine lune et en moyenne plus élevés autour de la nouvelle lune. Cette anomalie calendaire a été pour la première fois mise en avant par sur le marché états-unien Dichev and Janes (2001) et par Yuan et al. (2006) sur un grand nombre de marchés au travers le monde (et même à partir d’un indice d’indices pondéré et non pondéré). L’idée derrière cette anomalie est que le cycle lunaire affecterait l’humeur des investisseurs. En période de pleine lune, ils auraient à être moins optimistes (plus fréquemment dépressif) ce qui affecterait négativement leur évaluation des perspectives titres qu’ils négocient. Ce mécanisme générerait alors des rendements moins importants en moyenne sur cette période du cycle lunaire que lors de la nouvelle lune.
Depuis, cette anomalie a été principalement analysée en compléments d’autres qualifiées d’exotiques (taches solaires, résultats sportifs…). Globalement, les études récentes sur ce pool montrent qu’elles on tendance à s’effacer dès lors que l’incertitude devient importante notamment suite à un choc sur les marchés (Kim and Shamsuddin (2023)) .
Chargeons les packages et les données
Commençons par les packages. Ici, nous utiliserons le tidyquant et lunar, pour extraire les données, le tidyverse, pour les manipulations, la syntaxe et les graphes, patchwork et ggtext, en compléments pour leur mise en forme.
#Manipulation de données et graph
library(tidyverse)
# mise en forme de graphe
library(patchwork)
library(ggtext)
# chargement des données
library(tidyquant)
library(lunar)Commençons par extraire les données concernant l’indice Standard and Poor 500. Pour cela, mobilisons la fonction tq_get() du package tidyquant. Indiquons simplement le ticker de l’indice, ^GSPC, et les dates bornant la période d’extraction, ici du 1er janvier 2010 au 31 décembre 2025.
# Récupération des données du S&P 500
df_sp500 <- tq_get("^GSPC",from = "2010-01-01", to = "2025-12-31")
head(df_sp500)## # A tibble: 6 × 8
## symbol date open high low close volume adjusted
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 ^GSPC 2010-01-04 1117. 1134. 1117. 1133. 3991400000 1133.
## 2 ^GSPC 2010-01-05 1133. 1137. 1130. 1137. 2491020000 1137.
## 3 ^GSPC 2010-01-06 1136. 1139. 1134. 1137. 4972660000 1137.
## 4 ^GSPC 2010-01-07 1136. 1142. 1131. 1142. 5270680000 1142.
## 5 ^GSPC 2010-01-08 1141. 1145. 1136. 1145. 4389590000 1145.
## 6 ^GSPC 2010-01-11 1146. 1150. 1142. 1147. 4255780000 1147.L’extraction nous donne bien trop d’informations par rapport à ce que nous avons réellement besoin. Limitons la base à la date et aux cours ajustés.
df_sp500<-df_sp500 %>%
select(date,adjusted) %>%
rename(SP500=adjusted)
head(df_sp500)## # A tibble: 6 × 2
## date SP500
## <date> <dbl>
## 1 2010-01-04 1133.
## 2 2010-01-05 1137.
## 3 2010-01-06 1137.
## 4 2010-01-07 1142.
## 5 2010-01-08 1145.
## 6 2010-01-11 1147.Passons maintenant aux données concernant les phases lunaires. Pour cela, nous utiliserons la fonction lunar.phase() du package lunar. Celle-ci donne pour un jour désigné la phase du cycle lunaire exprimée en radians (pour rappel une mesure d’angle exprimée en base \(\pi\) et pour laquelle ouverture maximum, 360°, est \(2.\pi\)).
df_lune<-data.frame(date=df_sp500$date,
lunar_rad=lunar.phase(df_sp500$date,shift = 0))
head(df_lune)## date lunar_rad
## 1 2010-01-04 3.965492
## 2 2010-01-05 4.178261
## 3 2010-01-06 4.391029
## 4 2010-01-07 4.603798
## 5 2010-01-08 4.816567
## 6 2010-01-11 5.454873Maintenant que nous avons l’ensemble des données nous pouvons les fusionner avant de les retravailler afin de les opèrationnaliser pour les besoins de notre étude. Pour cela, utilisons la fonction left_join() du tidyverse et retenons la date comme variable de croisement (dans la mesure où il s’agit de la seule commune aux deux data frame, elle serait choisie par défaut).
df<-left_join(df_sp500,df_lune,by=join_by(date))
head(df)## # A tibble: 6 × 3
## date SP500 lunar_rad
## <date> <dbl> <dbl>
## 1 2010-01-04 1133. 3.97
## 2 2010-01-05 1137. 4.18
## 3 2010-01-06 1137. 4.39
## 4 2010-01-07 1142. 4.60
## 5 2010-01-08 1145. 4.82
## 6 2010-01-11 1147. 5.45Dans la mesure où nous n’avons plus besoin des deux data frame de base supprimons-les.
rm(df_lune,df_sp500)Traitement des données
Passons maintenant à la mise en forme des données pour l’analyse. En effet, nous ne travaillerons pas directement à partir des valeurs de l’indice et des arcs d’angle de la lune.
Commençons par calculer les rendements journaliers de l’indice. Optons pour les rendements continues. Veillons également à ne garder que les informations utiles. Une fois le rendement calculé la valeur de l’indice ne sert plus à rien, supprimons-la. Par ailleurs, la première ligne produit une non valeur (NA), supprimons-la également.
df<-df %>%
mutate(ret=log(SP500/lag(SP500))*100, .after=date) %>%
select(-SP500) %>%
filter(!is.na(ret))
head(df)## # A tibble: 6 × 3
## date ret lunar_rad
## <date> <dbl> <dbl>
## 1 2010-01-05 0.311 4.18
## 2 2010-01-06 0.0545 4.39
## 3 2010-01-07 0.399 4.60
## 4 2010-01-08 0.288 4.82
## 5 2010-01-11 0.175 5.45
## 6 2010-01-12 -0.943 5.67Travaillons maintenant sur les phases de la lune. Commençons par identifier chaque jour de cotation comme un jour du mois lunaire (synodique). Pour rappel, le mois lunaire compte en moyenne 29,53 jours. Nous attribuerons donc un chiffre allant de 1 à 30 à chaque jour de cotation en fonction de sa position dans le cycle mesurée grâce à notre variable lunar_rad.
duree_mois_lunaire <- 29.53059
df_<-df %>% mutate(
# passer sur une échelle en jours
jour_lunaire_continu = (lunar_rad / (2 * pi)) * duree_mois_lunaire +1,
# On arrondit à l'entier inférieur pour avoir des "classes" de jours
# (Jour 1, Jour 2...)
jour_lunaire = floor(jour_lunaire_continu))
rm(duree_mois_lunaire)La pleine lune intervient au milieu du mois lunaire, autrement dit au jour 15. Marquons les jours correspondant et, dans la foulée, identifions les fenêtres sur lesquels l’effet de la pleine lune devrait se faire ressentir. A l’image de ce qu’a proposé Yuan et al. (2006), nous considérons deux fenêtres centrées sur le jour de pleine lune, une de 7 jours (du jour 12 au jour 18) et une de 15 jours (du jour 8 au jour 22).
df_ <- df_ %>% mutate(
full_moon_d=jour_lunaire==15,
dummy_lune_7 = ifelse(jour_lunaire >= 12 & jour_lunaire <= 18, 1, 0),
dummy_lune_15 = ifelse(jour_lunaire >= 8 & jour_lunaire <= 22, 1, 0))
head(df_)## # A tibble: 6 × 8
## date ret lunar_rad jour_lunaire_continu jour_lunaire full_moon_d
## <date> <dbl> <dbl> <dbl> <dbl> <lgl>
## 1 2010-01-05 0.311 4.18 20.6 20 FALSE
## 2 2010-01-06 0.0545 4.39 21.6 21 FALSE
## 3 2010-01-07 0.399 4.60 22.6 22 FALSE
## 4 2010-01-08 0.288 4.82 23.6 23 FALSE
## 5 2010-01-11 0.175 5.45 26.6 26 FALSE
## 6 2010-01-12 -0.943 5.67 27.6 27 FALSE
## # ℹ 2 more variables: dummy_lune_7 <dbl>, dummy_lune_15 <dbl>Yuan et al. (2006) mobilisent, en plus de ces fenêtres discrètes autour de la pleine lune, une mesure continue de la proximité à cette dernière basée sur un approche trigonométrique. On a alors : \(cos(\frac{2.\pi.d_t}{29.53})\).
Décomposons cette mesure pour mieux la comprendre. Commençons par la partie centrale le ration \(\frac{d_t}{29,53}\) qui représente la position du jour dans le cycle lunaire (qui compte 29,53 jours) exprimée en pourcentages. Elle est alors multipliée par \(2.\pi\) qui correspond à un tour complet exprimé en radiant (100% d’un cycle). Le passage au cosinus permet de fixer les bornes des distances entre -1 et 1 en prenant en compte la nature cyclique de l’évolution. Le cosinus d’un angle de 0 est 1. Il correspond à la nouvelle lune. Celui d’un angle de 180° (\(\pi\)) est -1, et il correspond à la pleine lune. Au delà de 180°, le cosinus revient vers 1 qui correspond à la prochaine nouvelle lune. Dans le papier, les auteurs reprennent les mesures telle qu’elle est et postule un lien négatif entre les rendements et la proximité à la pleine lune tendre vers -1. Pour rapprocher la mesure de l’effet de la pleine lune, nous la passons par le signe opposé (-) et postulons un lien positif.
La forme fonctionnelle prise par cette mesure est clairement non linaire ce qui lui permet de prendre en compte la courbure de l’orbite. En complément, ajoutons une mesure de distance linaire établie sur la base de la valeur absolue de la différence entre le jour considéré et celui de la pleine lune (le 15ème). Cette mesure a le défaut de ne pas être exprimée dans la même unité que la mesure d’origine. Ajoutons une version de celle-ci normée pour être comprise entre - 1 et 1. Pour ce faire, commençons par diviser l’écart en valeur absolue au jour de plein lune par le jour de pleine lune. Cela permet d’avoir la mesure comprise entre 0 et 1 (0 si on est le jour de la pleine lune et 1 si on est à la nouvelle lune). Celle-ci est alors multipliée par 2 et enlevée à 1.
MaX<-max(df_$jour_lunaire_continu)
df_<-df_ %>%
mutate(prox_pl_lune=-cos(2 * pi * jour_lunaire_continu / MaX),
prox_pl_lune_lin=-abs(jour_lunaire-15),
prox_pl_lune_lin_norm =1- 2*(abs(df_$jour_lunaire_continu-(MaX/2))/(MaX/2)))
rm(MaX)Pour bien comprendre les différences entre la mesure de proximité à la pleine lune non linéaire à la Yuan et al. (2006) et notre version linéaire, présentons-les dans le même repère. Indiquons de même sur le repère les zones correspondant aux fenêtres définies précédemment (7 jours autour de la pleine lune en violet, 15 jours autour en saumon).
tibble(jour_synodique = seq(0, 29.53, by = 0.1)) %>%
mutate(proximite_lune = -cos(2 * pi * jour_synodique / 29.53),
prox_pl_lune_lin_norm = 1-2*(abs(jour_synodique-14.765)/(14.765))) %>%
ggplot( aes(x = jour_synodique)) +
annotate("rect", xmin = 12, xmax = 18, ymin = -Inf, ymax = Inf, fill = 'blue', alpha=0.5)+
annotate("rect", xmin = 8, xmax = 22, ymin = -Inf, ymax = Inf, fill = 'pink', alpha=0.5)+
geom_line(aes(y = proximite_lune),color = "#2c3e50", linewidth = 1.2) +
geom_line(aes(y=prox_pl_lune_lin_norm),color="red", linewidth = 1.2)+
geom_vline(xintercept = 14.76, linetype = "dashed", color = "darkblue",
linewidth = 0.8) +
geom_hline(yintercept = 0, linetype = "dotted", color = "grey50") +
scale_x_continuous(breaks = c(0, 7.4, 14.76, 22.1, 29.53),
labels = c("0\n(Nouvelle Lune)", "7.4\n(Premier Quartier)","14.76\n(Pleine Lune)", "22.1\n(Dernier Quartier)", "29.53\n(Nouvelle Lune)")) +
labs(title = "Comportement de la variable de proximité lunaire continue",
subtitle = 'Spécification fonctionnelle:<br>[**-cos(2 * pi * Jour_lunaire / 29.53)**]{style="color:#2c3e50;"}
<br>[**1 - 2 * abs(Jour_lunaire / 14.765)**]{style="color:#e74c3c;"}',
x = "Phase du cycle synodique (en jours)",
y = "Valeur de la variable (Pression / Proximité)") +
coord_cartesian(xlim=c())+ theme_minimal() +
theme(
plot.title = element_text(face = "bold", size = 14,hjust=0.5),
plot.subtitle = element_markdown(face = "italic", size = 12,hjust=0.5),
axis.text.x = element_text(size = 9, vjust = 0.5))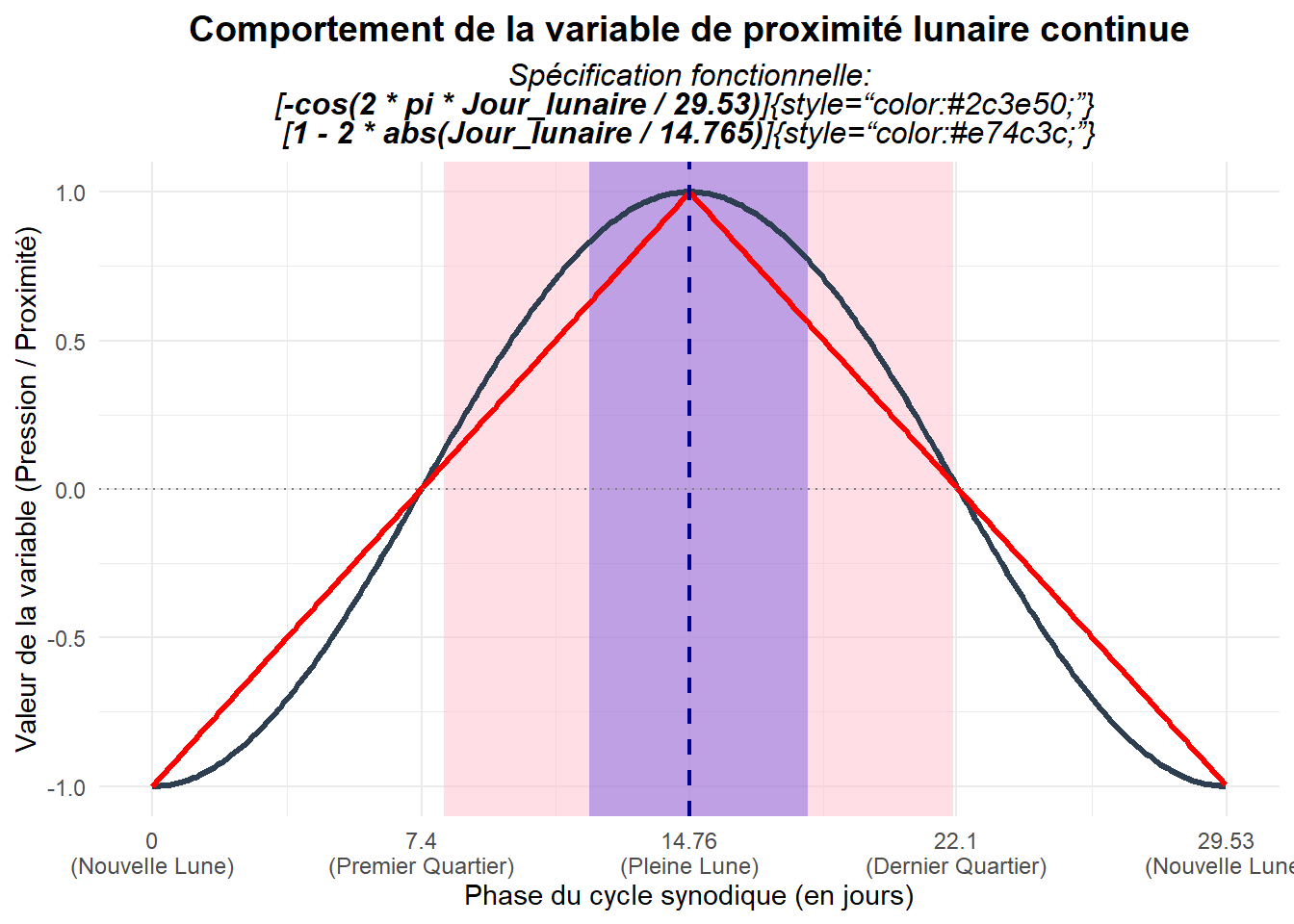
On voit nettement la différence de progression des deux courbes. Pour la courbe établie sur une base trigonométrique, on a à la fois un aplatissement à proximité des extrémités suivi d’une pente plus importante et d’un nouvel aplatissement à proximité de la pleine lune. Par ailleurs, on peut noter que les courbes se rejoignent aux extrémités mais aussi aux points marquant du cycle lunaire le premier quartier, la pleine lune et le dernier quartier.
Tests statistiques
Maintenant que nos données sont en forme, procédons à leur analyse.
Statistiques descriptives et représentations graphiques
Commençons pas un examen rapide des rendements sur la période. Regardons comment ceux-ci se distribuent jour par jour sur le mois lunaire. Commençons par établir une série de statistiques générales concernant cette distribution : moyenne et médiane (tendance centrale); écart-type (dispersion); skewness (asymétrie) et kurtosis (aplatissement).
df_g1<-df_ %>%
summarise(moy=mean(ret),
mediane=median(ret),
et=sd(ret),
sk=moments::skewness(ret),
kurt=moments::kurtosis(ret),
.by=jour_lunaire) %>%
arrange(jour_lunaire)
head(df_g1)## # A tibble: 6 × 6
## jour_lunaire moy mediane et sk kurt
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 0.0536 0.106 1.27 2.16 20.1
## 2 2 0.0825 0.0878 0.773 -0.946 6.06
## 3 3 0.0371 -0.0180 0.967 1.63 13.4
## 4 4 -0.115 0.00609 1.08 -0.641 5.42
## 5 5 -0.0550 0.00718 1.09 -0.382 5.08
## 6 6 -0.108 -0.0320 1.10 -1.35 7.59La première chose que l’on peut noter est le décalage systématique entre les rendements moyens et les rendements médians. Visualisons la chose.
g1<-df_g1 %>% ggplot(aes(x=jour_lunaire,y=moy)) +
annotate("rect",xmin = 12, xmax = 18, ymin = -Inf, ymax = Inf,
fill = 'blue',alpha=0.5)+
annotate("rect", xmin = 8, xmax = 22, ymin = -Inf, ymax =Inf, fill = 'pink', alpha=0.5)+
geom_hline(yintercept=0,linetype="dashed")+
geom_hline(yintercept=mean(df_$ret),,color="red",linetype="dashed")+
annotate("text",label="échantillon total",y=0.055,x=28,color='red',size=2)+
geom_vline(xintercept=15,color="darkblue",linetype="dashed")+
geom_line() +
geom_point() +
labs(title="Moyenne")+
scale_x_continuous(breaks=1:30)+
scale_y_continuous(labels=scales::label_percent(scale=1))+
coord_cartesian(expand=FALSE,xlim=c(0,31),ylim=c(-0.13,0.27))+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5,face="bold"),
axis.title = element_blank(),
axis.text.x = element_text(size=5),
axis.ticks = element_line(color='black'),
axis.line = element_line(color="black"),
panel.grid = element_blank())
g2<-df_g1 %>%
ggplot(aes(x=jour_lunaire,y=mediane)) +
annotate("rect", xmin = 12, xmax = 18, ymin = -Inf, ymax = Inf,
fill = 'blue', alpha=0.5)+
annotate("rect", xmin = 8, xmax = 22, ymin = -Inf, ymax = Inf,
fill = 'pink', alpha=0.5)+
geom_hline(yintercept=0,linetype="dashed")+
geom_hline(yintercept=median(df_$ret),color="red",linetype="dashed")+
annotate("text",label="échantillon total",y=0.06,x=28,color='red',size=2)+
geom_vline(xintercept=15,color="darkblue",linetype="dashed")+
geom_line() +
geom_point() +
labs(title="Médiane")+
scale_x_continuous(breaks=1:30)+
scale_y_continuous(labels=scales::label_percent(scale=1))+
coord_cartesian(expand=FALSE,xlim=c(0,31),ylim=c(-0.13,0.27))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face="bold"),
axis.title = element_blank(), axis.text.x = element_text(size=5),
axis.ticks = element_line(color='black'), axis.text.y =element_blank(),
axis.line = element_line(color="black"), panel.grid = element_blank())
g1+g2+plot_annotation( title = 'Rendements journaliers pour chaque jours du mois lunaire')&
theme(plot.title = element_text(hjust=0.5,face='bold'))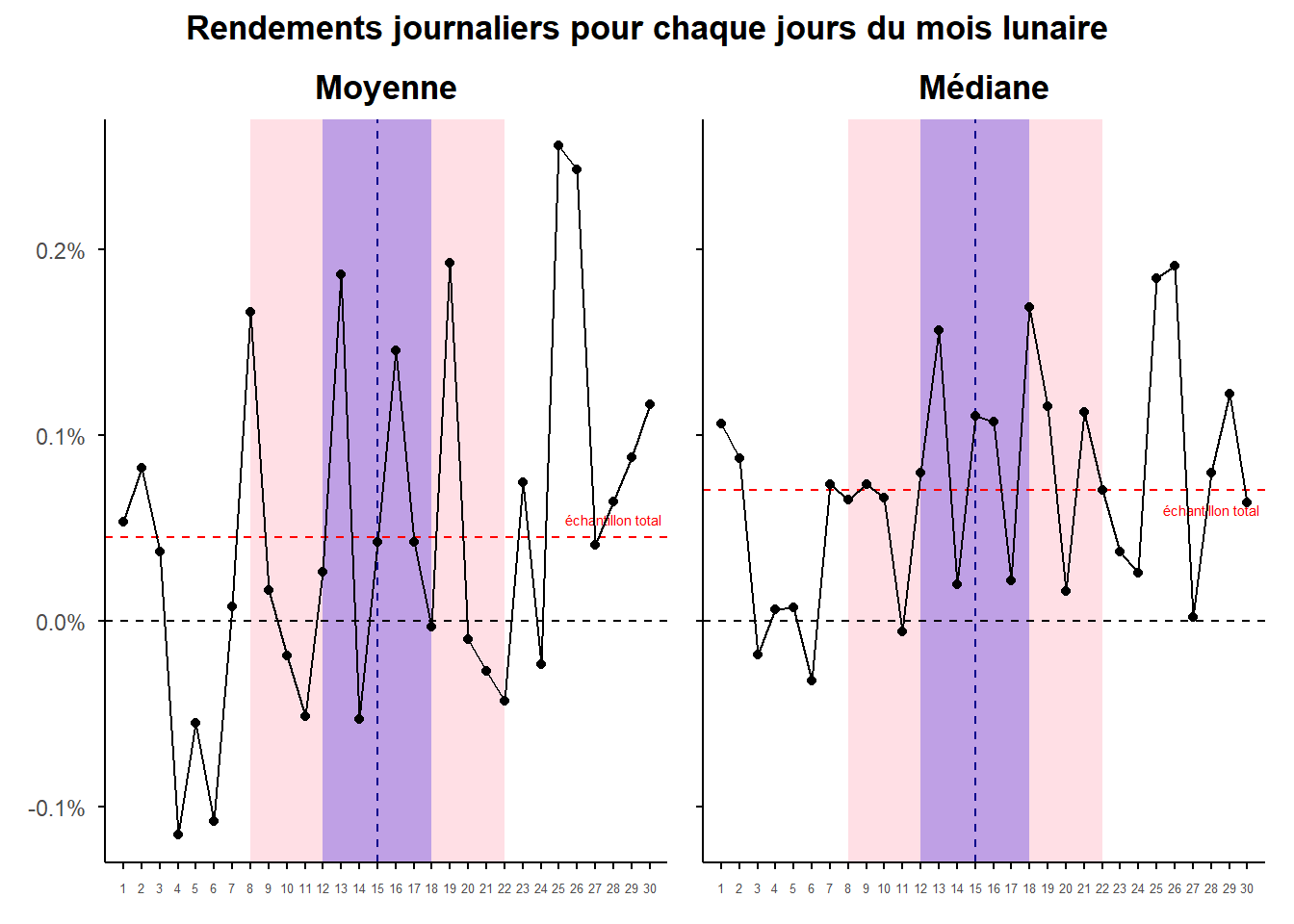
On constate que globalement les séries ont des formes très similaires à la différence prés que les moyennes apparaissent amplifier les mouvements de la courbes des médianes. L’ensemble est caractéristique de la présence de skewness non nulles et de Kurtosis élevées, autrement-dit d’asymétries dans la distribution des rendements générées notamment par la présence de valeurs extrêmes. Il s’agit de constats assez classiques lorsque l’on traite de rendements journaliers. Ceux-ci présentent généralement une asymétrie (une Skewness négative). La moyenne des rendements de la série 0,045% alors que leur médiane est de 0,07%. La moyenne est tirée en arrière par des évènements extrêmes négatifs. La présence de ces évènements extrêmes est confirmé par la Kurtosis qui est bien supérieure à ce que l’on trouve pour une loi normale (3). Elles est de 16,5. Voyons cela plus précisément via un graphe.
g1<-df_g1 %>%
ggplot(aes(x=jour_lunaire,y=sk)) +
annotate("rect", xmin = 12, xmax = 18, ymin = -Inf, ymax = Inf,
fill = 'blue',alpha=0.5)+
annotate("rect", xmin = 8, xmax = 22, ymin = -Inf, ymax = Inf,
fill = 'pink', alpha=0.5)+
geom_hline(yintercept=df_$ret %>%
moments::skewness(),
color="red",linetype="dashed")+
geom_vline(xintercept=15,color="darkblue",linetype="dashed")+
geom_line() + geom_point() + annotate("text",label="échantillon total",y=-1,x=28,color='red',size=2)+
labs(title="Skewness")+
scale_x_continuous(breaks=1:30)+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face="bold"),
axis.title = element_blank(),
axis.text.x = element_text(size=5), axis.line = element_line(color="black"), axis.ticks = element_line(color='black'),
panel.grid = element_blank())
g2<-df_g1 %>%
ggplot(aes(x=jour_lunaire,y=kurt)) +
annotate("rect", xmin = 12, xmax = 18, ymin = -Inf, ymax = Inf, fill = 'blue',alpha=0.5)+
annotate("rect", xmin = 8, xmax = 22, ymin = -Inf, ymax = Inf, fill = 'pink', alpha=0.5)+
geom_hline(yintercept=df_$ret %>% moments::kurtosis(), color="red",linetype="dashed")+
geom_hline(yintercept=3,linetype="dashed")+
geom_vline(xintercept=15,color="darkblue",linetype="dashed")+
geom_line() + geom_point() + annotate("text",label="échantillon total",y=16,x=28,color='red',size=2)+
annotate("text",label="3 (la kurtosis\n d'une loi normale)", y=2,x=3,size=1)+
labs(title="Kurtosis")+
scale_x_continuous(breaks=1:30)+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5,face="bold"), axis.title = element_blank(), axis.text.x = element_text(size=5),
axis.line = element_line(color="black"), axis.ticks = element_line(color='black'), panel.grid = element_blank())
g1+g2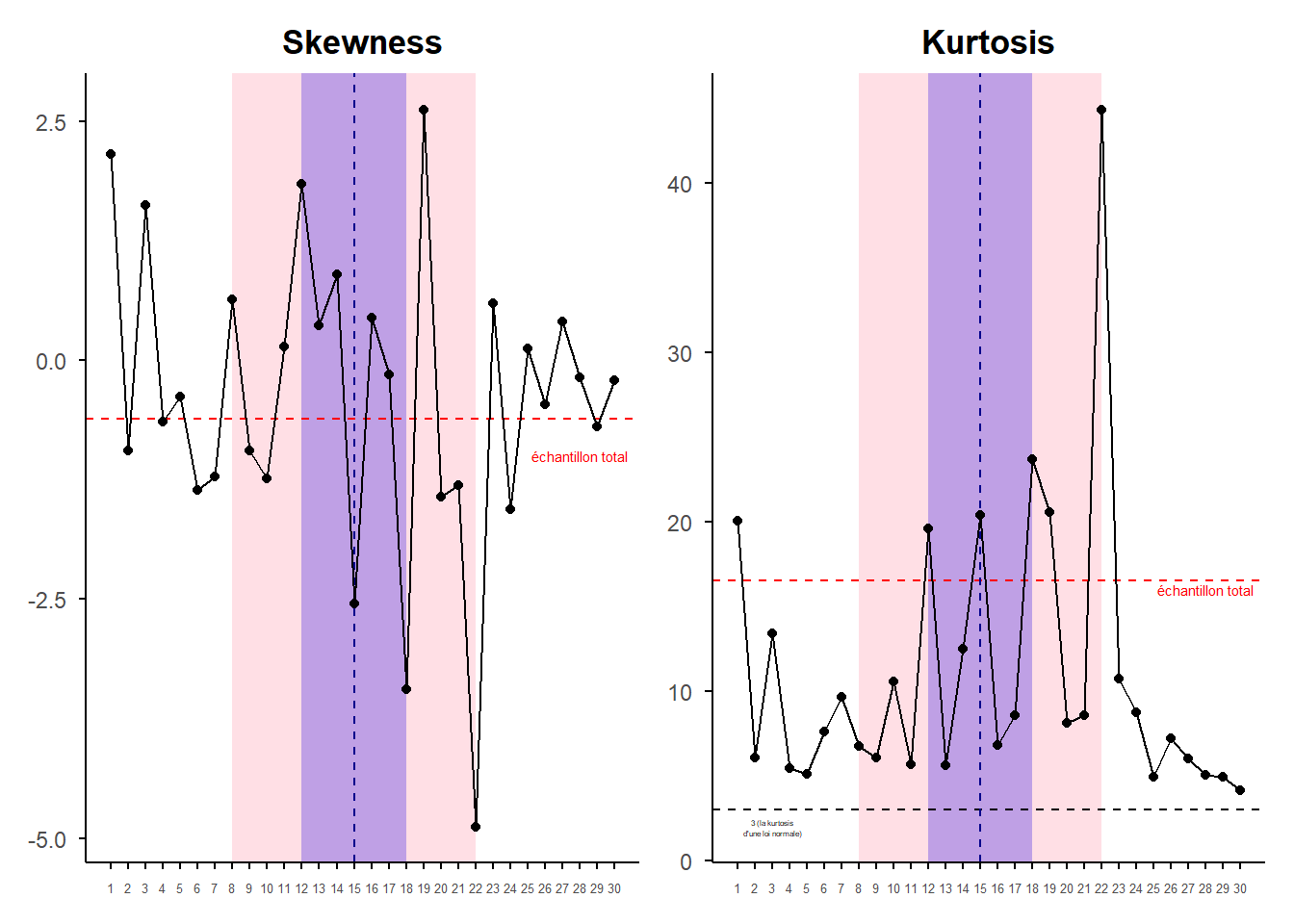
Il ressort nettement que la normalité des rendements quel que soit le jour lunaire considérée (proche ou éloigné de la pleine lune) doit être rejeté. La skewness est toujours différente de 0 et la Kurtosis de 3 qui sont les valeurs types des lois normales. Le comportement des rendements est structurellement leptokurtique indépendamment des phases de la lune.
Par ailleurs, on voit que certains jours connaissent des situations extrêmes vis à vis de ces statistiques est que ces jours sont inclus dans la fenêtre dédier à marquer la proximité à la pleine lune. Tous les jours dans les fenêtres ne sont pas affectés mais certains sont particulièrement marquant. C’est le cas du jours 22 qui marque la limite de la fenêtre large (15 jours autour de la pleine lune). Il présente la skewness la plus petit -4,78 et la kurtosis les plus grandes 44,35. Il semble bien qu’un ou plusieurs évènements importants aux conséquences fortement négatives sur les rendements boursiers soient intervenus un 22ème jour du mois lunaire.
Il y a donc des valeurs extrêmes et elles semblent se trouver plus fréquemment dans la fenêtre de 15 jours autour de la date de la pleine lune. Mais, qu’en est-il de la variabilité habituelle des rendement est-elle affectée par le cycle lunaire. Voyons cela à partir du graphe reprenant l’écart-type des rendements pour chaque jour du cycle.
df_g1 %>%
ggplot(aes(x=jour_lunaire,y=et)) +
annotate("rect", xmin = 12, xmax = 18, ymin = -Inf, ymax = Inf, fill = 'blue', alpha=0.5)+
annotate("rect", xmin = 8, xmax = 22, ymin = -Inf, ymax = Inf, fill = 'pink', alpha=0.5)+
geom_hline(yintercept=df_$ret %>% sd(),color="red",linetype="dashed")+
geom_vline(xintercept=15,color="darkblue",linetype="dashed")+
geom_line() +
geom_point() +
annotate("text",label="échantillon total",y=1.11,x=28,color='red')+
labs(title="Ecart-type des Rendements pour chaque jours du mois lunaire")+
scale_x_continuous(breaks=1:30)+
scale_y_continuous(labels=scales::label_percent(scale=1))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face="bold"),
axis.title = element_blank(), axis.line = element_line(color="black"),
axis.ticks = element_line(color='black'),
panel.grid = element_blank())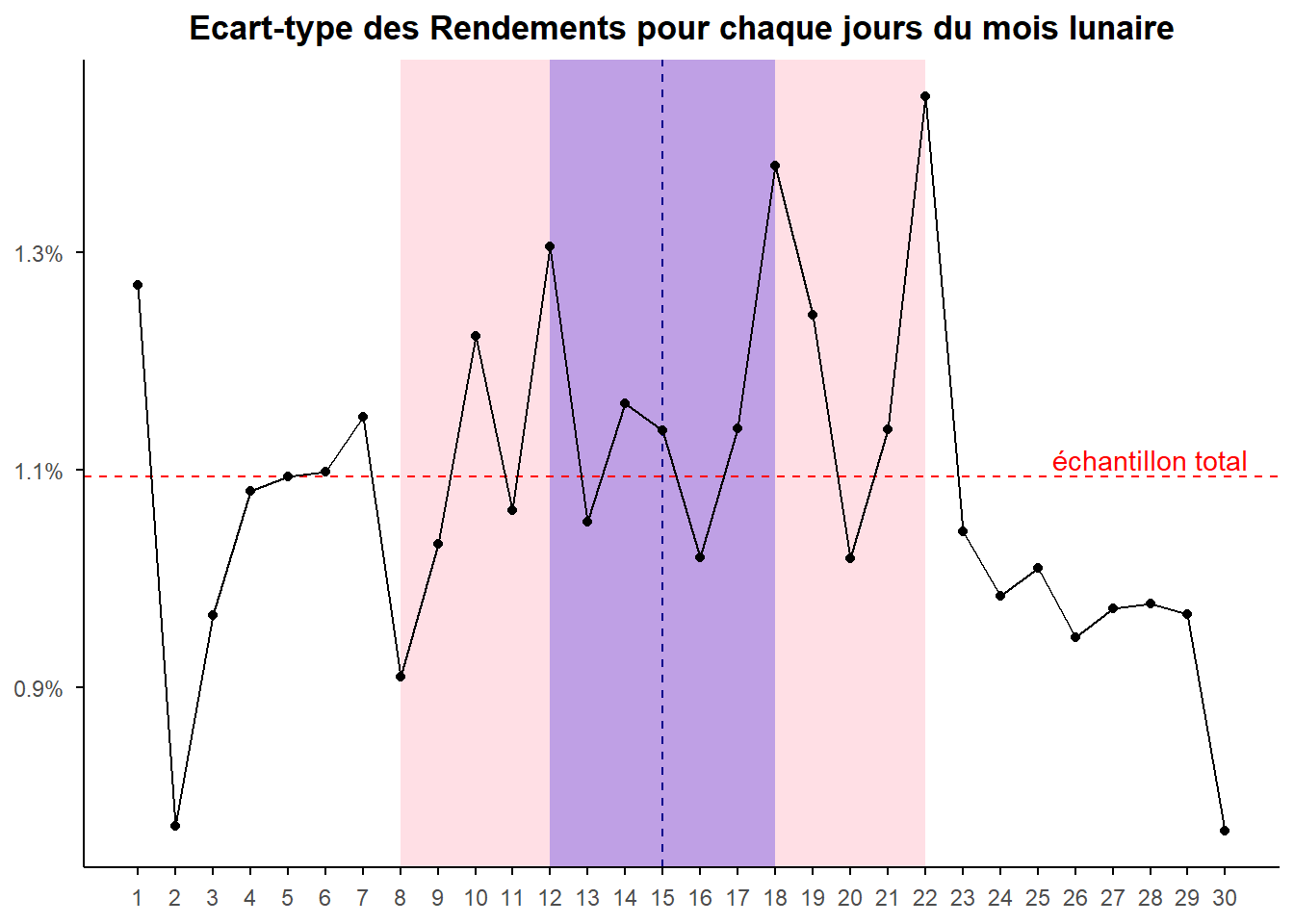
Il apparaît que les piques de volatilité (les plus hauts écart-types) se concentre sur les fenêtres dessinant la proximité à la pleine lune. On pourrait donc penser que, si l’effet de cette dernière n’est pas net concernant le niveau des rendements, il serait plus clair vis à vis de leur variabilité. Néanmoins, comme nous l’avons vue notamment avec le jour 22, nous sommes en présence de valeurs extrêmes qui pourraient affecter le diagnostique. La variabilité pourrait n’être que poussée par ces valeurs extrêmes qui apparaissent plus fréquemment lorsque l’on est prés de la pleine lune (à voir…).
Décomposer, comme nous l’avons fait, chaque élément descriptif de la distribution des rendements (tendance centrale, écart-type, asymétrie et queues épaisses) peut paraître fastidieux. Une autre possibilité est de présenter plus directement ces distributions et leur forme via des graphes de type boîtes à moustaches (boxplot). Faisons-le.
df_%>%
ggplot(aes(x=as.factor(jour_lunaire),y=ret)) +
annotate("rect", xmin = 12, xmax = 18, ymin = -Inf, ymax = Inf, fill = 'blue', alpha=0.5)+
annotate("rect", xmin = 8, xmax = 22, ymin = -Inf, ymax = Inf, fill = 'pink', alpha=0.5)+
geom_vline(xintercept=15,color="darkblue",linetype="dashed")+
geom_boxplot() +
stat_summary(fun = mean, geom = "point", shape = 20,size = 2.5, color = "red", fill = "red") +
labs(title="Rendements pour chaque jours du mois lunaire")+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face="bold"), axis.title = element_blank(),
axis.line = element_line(color="black"),
axis.ticks = element_line(color='black'),
panel.grid = element_blank())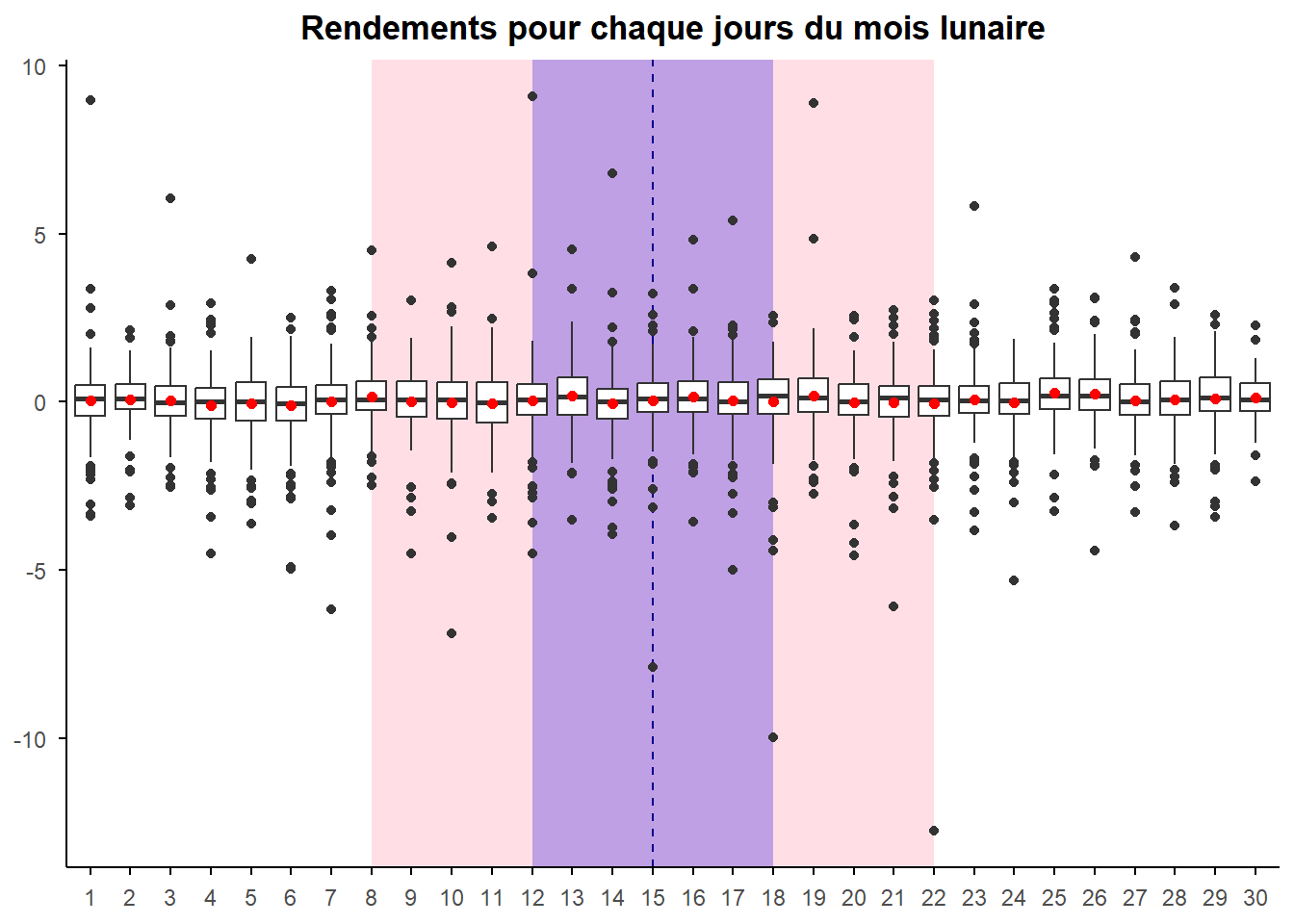
Nous avons marqué les moyennes par un point rouge. Celui permet de bien voir le décalage avec la médiane et de mettre en avant la skewness des distributions. La moyenne est très souvent ici plus basse que la médiane ce qui est la marque d’une skewness négative. Par ailleurs, on voit bien comment cette dernière est influencée par les valeurs extrêmes (les outliers) présentées en noir. Le cas du jour 22 est particulièrement marquant. On peut également noter que les valeurs les plus extrêmes se trouvent dans les fenêtres caractérisant la proximité à la plein lune.
Notre analyse ne s’arrête pas à juger de l’influence de la lune sur les rendements boursiers à partir de mesures discrètes de la proximité du jour de cotation à la pleine lune, ce que nous avons fait via les fenêtres de couleurs dans les graphes précédents. Nous avons également établis des mesures continues de l’intensité potentielle de l’effet du cycle lunaire via la proximité à la pleine lune. Pour avoir un aperçu du lien entre ces mesures et les rendements journaliers, présentons les sous la forme de nuages de points (un nuage par mesure).
g1<-df_ %>%
ggplot(aes(x=prox_pl_lune,y=ret))+
geom_point(size=0.75)+
geom_smooth(method = "lm", color = "red", se = FALSE)+
labs(x="proximité à la pleine lune",y="rendements journaliers")+
coord_cartesian(expand=FALSE,xlim=c(-1.025,1.025),ylim=c(-14,10))+
theme_minimal()+
theme(
axis.line = element_line(color="black"),
axis.ticks = element_line(color='black'),
panel.grid = element_blank())
g2<-df_ %>%
ggplot(aes(x=prox_pl_lune_lin_norm,y=ret))+
annotate("text", x = -0.85, y = -10, label = "Nouvelle Lune", fontface = "italic", color = "gray40") +
annotate("text", x = 0.85, y = -10, label = "Pleine Lune", fontface = "italic", color = "darkblue")+
geom_point(size=0.75)+ geom_smooth(method = "lm", color = "red", se = FALSE)+
labs(x="proximité linéaire à la pleine lune",
y="rendements journaliers")+
coord_cartesian(expand=FALSE,xlim=c(-1.025,1.025),ylim=c(-14,10))+
theme_minimal()+
theme(
axis.line = element_line(color="black"),
axis.ticks = element_line(color='black'),
panel.grid = element_blank())
g1/g2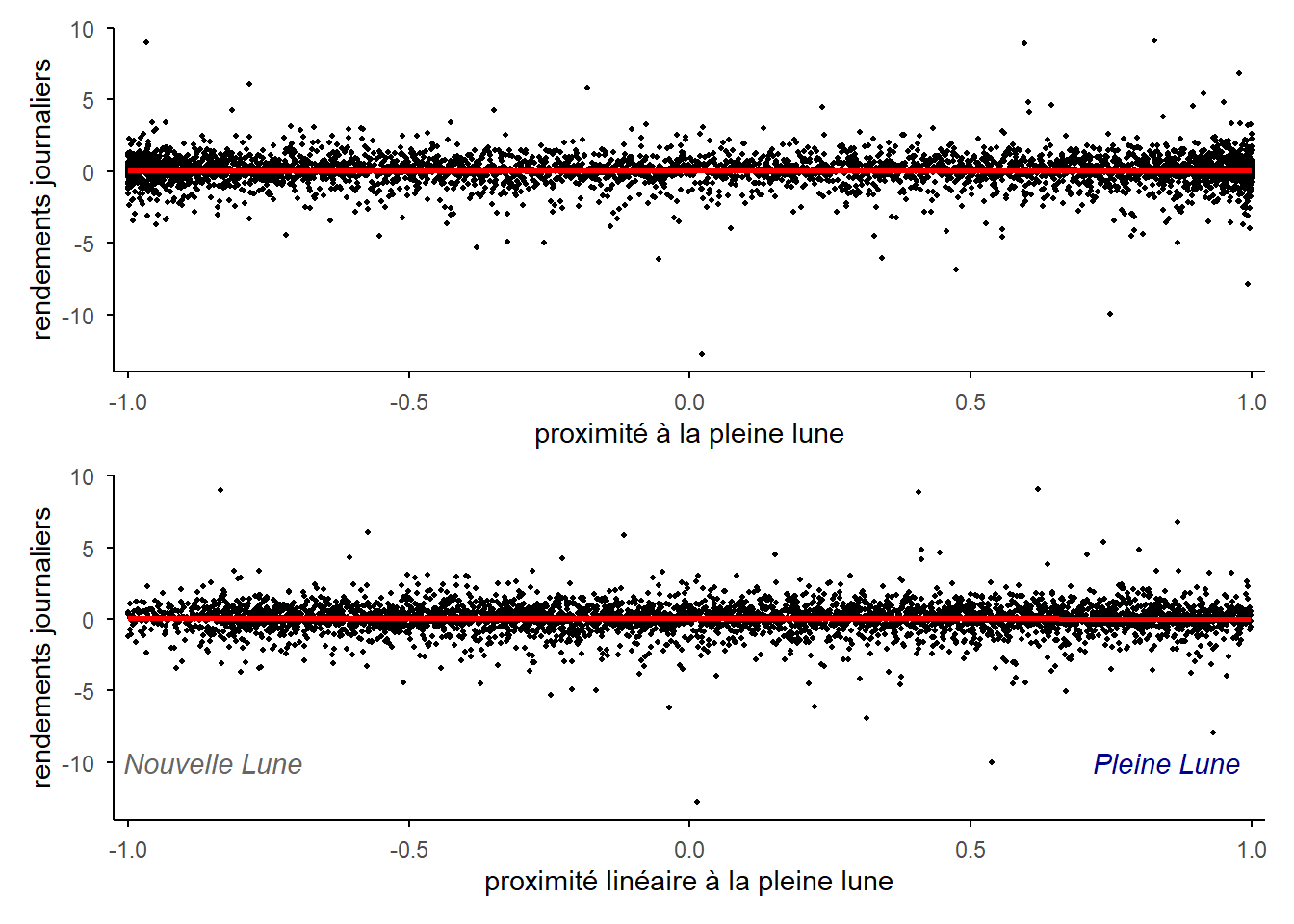
Les deux nuages présentent globalement la même forme allongée. Seules les extrémités apparaissent différentes. Par ailleurs, ils ne semblent pas se dégager de tendance même si la droite de régression reportée en rouge montre une pente très très légèrement négative. Rien de semble ici venir appuyer l’hypothèse d’effets du cycle lunaire sur les rendements.
L’analyse discrète laissait potentiellement entre voir un effet de la lune sur la volatilité (la variance/écart-type) des rendements. Pour s’en donner une idée, utilisons une proxy de la variance de rendement souvent mobilisé sur ce type d’étude, le carré des rendements. Avant de produire les graphes, revenons sur cette approximation. Rappelons la formule de la variance des rendements.
\[\sigma^2=E(ret_t-\mu)^2\]
Concentrons-nous sur le noyau de la formule, le traitement des observations individuels (avant l’espérance): la différence à la moyenne au carré. Développons cet élément afin de voir ce qui pèse le plus sur sa valeur.
\[(ret_t-\mu)^2=ret_t^2-2.ret_t.\mu+\mu^2\]
Si \(\mu\) est proche de zéro, ce qui est sur longue période le cas pour les rendements journaliers des actions, alors ce qui pèse le plus sur ce noyau ce sont les rendements carrés. Plus cette élément sera grand plus la variance le sera également.
Cette simplification n’est pas valable pour les moments de rang supérieure. Dès qu’on passe à l’ordre 3 (asymétrie) et à l’ordre 4 (aplatissement), les distorsions liées à la moyenne et l’absence de division par l’écart-type (\(\sigma^3\) ou \(\sigma^4\)) font que \(ret_t^3\) et \(ret_t^4\) ne mesurent plus du tout la forme de la distribution. Ce ne sont pas des proxies valides. Par ailleurs, utiliser des estimations journalières établies sur la base du noyaux de leur formule pose d’autres problèmes. Les moyenne et écart-type mobilisés pour standardiser les rendements sont influencées par les valeurs de ces derniers. En présence de valeurs extrêmes, cela crée des distorsions loin d’être le reflet des processus sous-jacents. La difficulté est d’autant plus importante que l’échantillon est petit. Plusieurs solutions peuvent être mises en oeuvre pour surmonter la difficulté : estimation des paramètres out-of-sample, estimation sur fenêtre glissante excluant la date de mesure du rendement, mobilisation d’un modèle GARCH pour établir l’écart-type mobilisé… Nous laisserons ces dimensions de côté.
Produisons les nuages associés à notre mesure de contribution à la volatilité, notre proxy (les rendements au carré).
g1<-df_ %>%
ggplot(aes(x=prox_pl_lune,y=ret^2))+
annotate("text", x = -0.80, y = 110, label = "Nouvelle\nLune", color = "gray40",
fontface = "bold", vjust = 1, size = 3) +
annotate("text", x = 0.87, y = 110, label= "Pleine\nLune", color = "#27408B",
fontface = "bold", vjust = 1, size= 3) +
geom_point(size=0.75)+ geom_smooth(method = "lm", color = "red",se = FALSE)+
labs(x="proximité à la pleine lune",
y="rendements journaliers carrés")+
coord_cartesian(expand=FALSE,xlim=c(-1.025,1.025),ylim=c(0,110))+
theme_minimal()+
theme(axis.line = element_line(color="black"),
axis.ticks = element_line(color='black'),
panel.grid = element_blank())
g2<-df_ %>%
ggplot(aes(x=prox_pl_lune_lin_norm,y=ret^2))+
annotate("text", x = -0.80, y = 110, label = "Nouvelle\nLune", color = "gray40", fontface = "bold", vjust = 1, size = 3) +
annotate("text", x = 0.87, y = 110, label = "Pleine\nLune", color = "#27408B", fontface = "bold", vjust = 1, size = 3) +
geom_point(size=0.75)+
geom_smooth(method = "lm", color = "red", se = FALSE)+
labs(x="proximité linéaire à la pleine lune",y="rendements journaliers carrés")+
coord_cartesian(expand=FALSE,xlim=c(-1.1,1.1),ylim=c(0,110))+
theme_minimal()+
theme(
axis.line = element_line(color="black"),
axis.title.y = element_blank(), axis.text.y = element_blank(),
axis.ticks = element_line(color='black'), panel.grid = element_blank())
g1+g2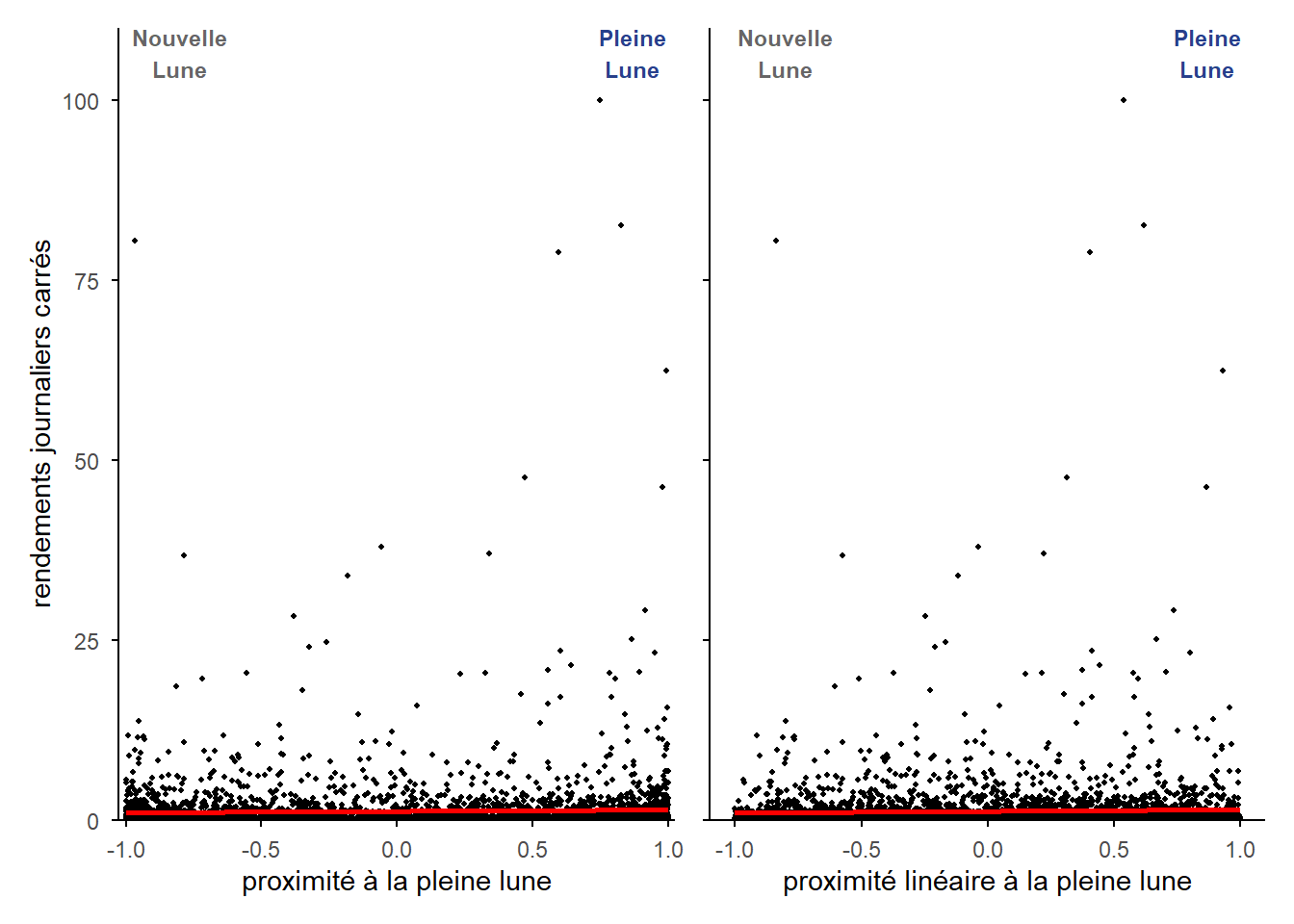
Encore une fois, il est difficile de déceler une réelle tendance, un lien linaire, à partir du nuage. La pente de la droite de régression apparaît légèrement positive. Néanmoins, on retrouve comme précédemment une série de points qui se détache du nuage marquant des valeurs extrêmes et ces points sont plus fréquent à proximité de la pleine lune.
Quelques tests uni-variés
L’ensemble des statistiques et graphes présentés ne semblent pas en faveur de la présence d’un effet net des phase de la lune sur les rendements de l’indice si ce n’est concernant l’écart-type de ces derniers. Néanmoins, si une approche visuelle peut poser les bases de l’analyse, elle peut être trompeuse quand au phénomène sous-jacent. En effet, elle ne prend pas en compte la probabilité que les phénomènes constatés soient dus au hasard et est sujette à de potentielles illusions d’optiques. Les tests statistiques uni-variés permettent de solutionner aux moins en partie ces problèmes.
Procédons donc à une série de tests. Commençons par traiter de la question de l’égalité de tendance centrale des rendements sur les différents jours du cycle lunaire. Laissons de coté nos variables explicatives pour travailler globalement.
Le premier réflexe que l’on a générale dans ce cas est de mobiliser une ANOVA à un facteur. Il s’agit de l’option la plus puissante mais repose sur des conditions d’utilisation très restrictives (normalité et homoscédasticité). Laissons-les de coté pour le moment. Utilisons aov() pour réaliser le test.
aov(ret~factor(jour_lunaire),data=df_) %>%
summary()## Df Sum Sq Mean Sq F value Pr(>F)
## factor(jour_lunaire) 29 36 1.245 1.04 0.407
## Residuals 3992 4779 1.197Le résultat ne permet pas de rejeter H0 l’hypothèse d’égalité des rendements moyens sur l’ensemble des jours du cycle lunaire. Le même résultat peut être obtenu à partir de la fonction oneway.test() en précisant que l’on considère la variance égale sur l’ensemble des groupes (homoscédasticité).
oneway.test(ret~factor(jour_lunaire),data=df_,var.equal = TRUE)##
## One-way analysis of means
##
## data: ret and factor(jour_lunaire)
## F = 1.04, num df = 29, denom df = 3992, p-value = 0.4067Revenons sur l’hypothèse d’égalité de variance. Testons-la. Pour ce faire, il y plusieurs possibilités au nombre desquelles on trouve les tests de Bartlett et de Levene. Le premier repose sur l’hypothèse forte de normalité des variables au sein des groupes comparés. Il est très puissant si cette condition est respectée. Le second est moins puissant même ne repose pas sur cette hypothèse (dans sa configuration centrée sur la médiane, test de Bronw-Forsythe). Il est plus robust.
Commençons par le test de Bartlett.
bartlett.test(ret~factor(jour_lunaire),data=df_)##
## Bartlett test of homogeneity of variances
##
## data: ret by factor(jour_lunaire)
## Bartlett's K-squared = 147, df = 29, p-value < 2.2e-16Le test rejette très clairement l’hypothèse d’égalité des variances, ce qui irait dans le sens de nos constats sur l’écart-type et nous conduirait à revoir nos ANOVA pour les adapter à l’hétéroscédasticité. Cela peut être fait via la fonction oneway.test() sans précisé var_equal (la valeur par défaut est FALSE). Le test est alors pratiqué en utilise l’approximation de Welch.
oneway.test(ret~factor(jour_lunaire),data=df_)##
## One-way analysis of means (not assuming equal variances)
##
## data: ret and factor(jour_lunaire)
## F = 1.1194, num df = 29.0, denom df = 1402.4, p-value = 0.3026Le test, même corrigé, ne permet pas de rejeter l’égalité des moyennes sur le cycle lunaire.
Néanmoins, nous l’avons vu via les skewness et kurtosis l’hypothèse de normalité est loin d’être vraisemblable. Aussi, doublons-nous le test pas un test de Levene. Celui-ci peut être réalisé via la fonction leveneTest() du package car.
car::leveneTest(ret ~ factor(jour_lunaire), data = df_)## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 29 0.7809 0.7919
## 3992Le test ne permet pas de rejeter l’égalité de variance. Cela va dans le sens d’une conservation des résultats de nos ANOVA de départ. Néanmoins, ceux reposent sur l’hypothèse de normalité. Il est donc plus rigoureux de procéder à un test non paramétrique de type Kruskal-Wallis (différences de médianes). Cela se fait facilement via la fonction kruskal.test().
kruskal.test(ret ~ factor(jour_lunaire), data = df_)##
## Kruskal-Wallis rank sum test
##
## data: ret by factor(jour_lunaire)
## Kruskal-Wallis chi-squared = 29.436, df = 29, p-value = 0.4425Les conclusions des tests univariés s’avèrent convergentes. Alors que le test de Levene valide l’homoscédasticité des rendements à travers le calendrier lunaire (\(p = 0,79\)), l’ANOVA classique tout comme le test non paramétrique de Kruskal-Wallis (\(p = 0,4425\)) échouent à rejeter l’hypothèse nulle d’égalité des tendances centrales. Qu’on observe la moyenne arithmétique ou la médiane des rendements, aucun jour du cycle ne se distingue par une performance anormalement haute ou basse.
Passons aux tests de régression.
Régressions simples
Ici nous travaillerons à partir des variables définies précédemment pour caractériser le cycle lunaire et la proximité à la pleine lune : fenêtres et mesures continues. Commençons par traité des rendements en eux-mêmes (sans les élevés au carré). Procédons aux régressions (lm()) et assemblons les résultats dans une même table via la fonction modelsummary() du package éponyme.
reg1<-lm(ret~dummy_lune_7, data=df_)
reg2<-lm(ret~dummy_lune_15, data=df_)
reg_d<-lm(ret~prox_pl_lune, data=df_)
reg_d2<-lm(ret~prox_pl_lune_lin_norm, data=df_)
modelsummary::modelsummary(list(reg1,reg2,reg_d,reg_d2),stars=TRUE,gof_map = c("nobs","r.squared","F"))| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||||
| (Intercept) | 0.042* | 0.049* | 0.045** | 0.045** |
| (0.020) | (0.025) | (0.017) | (0.017) | |
| dummy_lune_7 | 0.014 | |||
| (0.041) | ||||
| dummy_lune_15 | -0.008 | |||
| (0.035) | ||||
| prox_pl_lune | -0.012 | |||
| (0.025) | ||||
| prox_pl_lune_lin_norm | -0.015 | |||
| (0.031) | ||||
| Num.Obs. | 4022 | 4022 | 4022 | 4022 |
| R2 | 0.000 | 0.000 | 0.000 | 0.000 |
| F | 0.118 | 0.060 | 0.236 | 0.240 |
La première chose à noter est que concernant les rendements rien n’est statistiquement significatif ce qui confirme ce qui ressortait de nos analyses préliminaires. On peut également noter que les estimations un paterne particulier le coefficient est positif sur la fenêtre courte et négatif sur les autres variables. Cela laisse à penser que sur la fenêtre large il existe des rendements négatifs fort sur cette espace entre la fenêtre court et large. Nous l’avons vu c’est le cas du désastre associé au jour 22.
Mais avant de laisser cela de coté, procédons aux tests de validation des hypothèses portant sur la forme des résidus afin d’assurer la fiabilité des tests sur les coefficients. Procédons au test de Breusch-Pagan pour l’hétéroscédasticité et de Breusch-Gordfrey pour l’auto-corrélation. Les fonctions bptest() et bgtest() du package lmtest permettent de les réaliser facilement. Pour le test d’auto-corrélation, considérons deux niveaux de retard l’ordre 1 (le jour de cotation précédent le jour considéré) et l’ordre 5 (la semaine précédent le jour de considéré). Présentons uniquement les p-values.
data.frame( reg=1:4,
breusch_P=c(lmtest::bptest(reg1)$p.value,lmtest::bptest(reg2)$p.value,
lmtest::bptest(reg_d)$p.value,lmtest::bptest(reg_d2)$p.value) %>%
round(digits=3),
breusch_G_1=c(lmtest::bgtest(reg1)$p.value,lmtest::bgtest(reg2)$p.value,
lmtest::bgtest(reg_d)$p.value,lmtest::bgtest(reg_d2)$p.value) %>%
round(digits=3),
breusch_G_5=c(lmtest::bgtest(reg1,order=5)$p.value,
lmtest::bgtest(reg2,order=5)$p.value,
lmtest::bgtest(reg_d,order=5)$p.value,
lmtest::bgtest(reg_d2,order=5)$p.value) %>%
round(digits=3))## reg breusch_P breusch_G_1 breusch_G_5
## 1 1 0.176 0 0
## 2 2 0.046 0 0
## 3 3 0.065 0 0
## 4 4 0.084 0 0Globalement, les tests rejettent homoscédasticité (sauf la régression 1) et l’absence d’auto-corrélation (d’ordre 1 et 5). Les tests doivent donc être ajustés sur ces deux dimensions. Nous utiliserons pour ce faire la méthode de Newey-West. Intégrons cela dans nos régressions via l’option vcov de modelsummary() en indiquant “NeweyWest”.
reg1<-lm(ret~dummy_lune_7, data=df_)
reg2<-lm(ret~dummy_lune_15, data=df_)
reg_d<-lm(ret~prox_pl_lune,data=df_)
reg_d2<-lm(ret~prox_pl_lune_lin_norm, data=df_)
modelsummary::modelsummary(list(reg1,reg2,reg_d,reg_d2),stars=TRUE, vcov="NeweyWest", gof_map = c("nobs","r.squared","F"))| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||||
| (Intercept) | 0.042* | 0.049* | 0.045** | 0.045** |
| (0.017) | (0.023) | (0.016) | (0.016) | |
| dummy_lune_7 | 0.014 | |||
| (0.042) | ||||
| dummy_lune_15 | -0.008 | |||
| (0.033) | ||||
| prox_pl_lune | -0.012 | |||
| (0.023) | ||||
| prox_pl_lune_lin_norm | -0.015 | |||
| (0.028) | ||||
| Num.Obs. | 4022 | 4022 | 4022 | 4022 |
| R2 | 0.000 | 0.000 | 0.000 | 0.000 |
L’ajustement des standard errors ne remet pas en cause les précédentes conclusions. Le cycle lunaire n’influence pas les rendements du S&P500. Intéressons-nous maintenant à la question de la volatilité et répliquons l’analyse sur notre proxy les rendements au carré. Passons les tests diagnostiques d’hétéroscédasticité et d’autocorrélation et appliquons directement la correction de Mewey-West.
reg1<-lm(ret^2~dummy_lune_7, data=df_)
reg2<-lm(ret^2~dummy_lune_15, data=df_)
reg_d<-lm(ret^2~prox_pl_lune, data=df_)
reg_d2<-lm(ret^2~prox_pl_lune_lin_norm, data=df_)
modelsummary::modelsummary(list(reg1,reg2,reg_d,reg_d2),stars=TRUE,vcov="NeweyWest", gof_map = c("nobs","r.squared","F"))| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||||
| (Intercept) | 1.143*** | 1.049*** | 1.193*** | 1.193*** |
| (0.161) | (0.135) | (0.180) | (0.183) | |
| dummy_lune_7 | 0.239 | |||
| (0.166) | ||||
| dummy_lune_15 | 0.296+ | |||
| (0.179) | ||||
| prox_pl_lune | 0.196+ | |||
| (0.105) | ||||
| prox_pl_lune_lin_norm | 0.227+ | |||
| (0.122) | ||||
| Num.Obs. | 4022 | 4022 | 4022 | 4022 |
| R2 | 0.000 | 0.001 | 0.001 | 0.001 |
Cette fois les choses sont différentes. Mis à part pour la fenêtre courte, ils font apparaître un effet statistiquement significatif au seuil de 10% de la proximité à la pleine lune sur la variance des rendements (sur notre proxy de cette dernière).
Néanmoins ce résultat nous amène à nous poser des questions quand à sa robustesse. Pourquoi la fenêtre la plus courte là où la proximité avec la pleine lune est la plus grande n’est pas significative alors que les mesures continues de la distance le sont?
Une des réponses potentielles à cette interrogation est qu’il existe une forme de non linéarité entre nos rendement carré et les mesures continues de proximité à la pleine lune. Testons cela en supposant une spécification quadratique et une autre cubique.
reg_quad1 <- lm(ret^2 ~ prox_pl_lune + I(prox_pl_lune^2),
data = df_)
reg_quad2 <- lm(ret^2 ~ prox_pl_lune + I(prox_pl_lune_lin_norm^2),
data = df_)
reg_cub1 <- lm(ret^2 ~ prox_pl_lune + I(prox_pl_lune^2)+ I(prox_pl_lune^3),
data = df_)
reg_cub2 <- lm(ret^2 ~ prox_pl_lune + I(prox_pl_lune_lin_norm^2)+
I(prox_pl_lune_lin_norm^3), data = df_)
modelsummary::modelsummary(list(reg_quad1,reg_quad2,reg_cub1,reg_cub2),stars=TRUE,vcov="NeweyWest", gof_map = c("nobs","r.squared","F"))| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||||
| (Intercept) | 1.267*** | 1.260*** | 1.265*** | 1.255*** |
| (0.232) | (0.216) | (0.228) | (0.215) | |
| prox_pl_lune | 0.201* | 0.204+ | 0.403 | 0.349+ |
| (0.101) | (0.104) | (0.265) | (0.188) | |
| I(prox_pl_lune^2) | -0.153 | -0.144 | ||
| (0.152) | (0.146) | |||
| I(prox_pl_lune_lin_norm^2) | -0.212 | -0.182 | ||
| (0.189) | (0.174) | |||
| I(prox_pl_lune^3) | -0.275 | |||
| (0.280) | ||||
| I(prox_pl_lune_lin_norm^3) | -0.337 | |||
| (0.259) | ||||
| Num.Obs. | 4022 | 4022 | 4022 | 4022 |
| R2 | 0.001 | 0.001 | 0.001 | 0.001 |
Aucun des coefficients des variables élevées à la puissance (2 ou 3) n’est statistiquement significatif ce que confirme la linéarité de la relation mise en évidence.
La seconde hypothèse est que cette relation soit le fruit d’observations aberrantes (d’outliers) qui pousse le lien qui sans eux n’existerait pas. Pour tester cette hypothèse, procédons à un ajustement simple winsorisons les données à 1%. Cela consiste à remplacer les valeurs extrêmes par des moins extrêmes pour en neutraliser l’effet. En winsorisant à un 1%, on remplace les valeurs inférieures au 0,5ème precentiles par ce derniers et les valeurs supérieures au 99,5ème percentile par celui-ci. La fonction Winsorize() du package DescTools permet de réaliser l’opération très facilement. Réalisons la sur nos rendements et refaisons tourner nos régressions sur ces nouvelles valeurs.
df_$ret_winsor <- DescTools::Winsorize(df_$ret,
quantile(df_$ret, probs=c(0.005, 0.995)))
df_$ret_winsor_2 <- df_$ret_winsor^2
reg1<-lm(ret_winsor_2~dummy_lune_7, data=df_)
reg2<-lm(ret_winsor_2~dummy_lune_15, data=df_)
reg_d<-lm(ret_winsor_2~prox_pl_lune, data=df_)
reg_d2<-lm(ret_winsor_2~prox_pl_lune_lin_norm, data=df_)
modelsummary::modelsummary(list(reg1,reg2,reg_d,reg_d2),stars=TRUE,vcov="NeweyWest", gof_map = c("nobs","r.squared","F"))| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||||
| (Intercept) | 0.976*** | 0.952*** | 0.994*** | 0.994*** |
| (0.065) | (0.091) | (0.071) | (0.071) | |
| dummy_lune_7 | 0.089 | |||
| (0.089) | ||||
| dummy_lune_15 | 0.089 | |||
| (0.063) | ||||
| prox_pl_lune | 0.088 | |||
| (0.055) | ||||
| prox_pl_lune_lin_norm | 0.106 | |||
| (0.067) | ||||
| Num.Obs. | 4022 | 4022 | 4022 | 4022 |
| R2 | 0.000 | 0.000 | 0.001 | 0.001 |
Les tests perdent leur significativité statistique. Le précédant constat était bien le fruit des valeurs extrêmes que l’on avait identifiées entre l’extrémité de la fenêtre courte et celle de la fenêtre large et notamment le jour 22.
Le verdict des tests de robustesse est sans appel. En appliquant une procédure de winsorisation au seuil de 1 % afin de neutraliser l’influence des valeurs extrêmes, l’ensemble des significativités précédemment observées sur les rendements au carré s’évanouit.
Ce résultat nous amène à rejeter définitivement l’hypothèse d’une influence des phases de la lune sur la volatilité moyenne ou régulière des actifs. L’anomalie calendaire observée initialement n’était qu’un mirage statistique provoqué par la sensibilité des moindres carrés ordinaires aux chocs atypiques (comme celui apparaissant le jour 22).
Pour autant, cette conclusion déplace le débat de manière stimulante : si la lune n’influence pas le risque ordinaire, la concentration de ces variabilités exceptionnelles et de ces outliers sur des fenêtres précises du cycle soulève des questions de recherche ouvertes sur la distribution des risques extrêmes (fat-tails) plutôt que sur celle de la variance conditionnelle.
Par ailleurs, notez que nos tests ont été réalisé sur l’indice S&P 500 qui est un indice large mais pondéré. Ce qui veut dire que les grosses capitalisations ont un poids fort sur les valeurs de l’indice. Or, ces grosses capitalisations sont plus fréquemment traité de manière professionnelle ou même automatisée ce qui laisse peu de place à une potentielle influence de la lune sur les décisions des investisseurs. C’est d’ailleurs ce que pointaient déjà Yuan et al (2006) dans leur conclusion. Les petites capitalisations sont moins fréquemment arbitrées pour des questions de liquidité ou même de restriction de position (pas de ventes à découvert) ce qui laisse plus de place à de potentiels anomalies au regard l’efficience.