Dans ce nouveau post, nous revenons sur la question de l’hypothèse de parallel trend mais en adoptant une perspective nouvelle. Il ne s’agit plus de la tester, (de toute façon, il est impossible de le faire de façon définitive), ou de voir dans quelle mesure une violation plus ou moins importante de celle-ci affecterait nos conclusions. Nous cherchons à estimer l’ATET en présence d’une violation soupçonnée de l’hypothèse. Cette violation (si elle existe) biaise l’estimation de l’ATET. Pour gérer le problème plusieurs solutions existent. Celle dont nous traiterons ici est l’estimation en triple différences (ou Difference in Difference in Difference). Elle nécessite pour être mise en oeuvre a minima d’avoir identifié le facteur venant potentiellement poser problème et qu’il puisse prendre la forme d’une variable binaire.
Comme d’habitude, nous développerons les principales intuitions du modèle au travers de réplication d’exemples pratiques issus de la littérature et différents manuels. Mais avant d’aller plus loin, chargeons les différents packages que nous allons mobiliser par la suite.
# manipulation et chargement de données
library(tidyverse)
library(labelled)
# estimation et test Diff in Diff et autres tests classiques
library(fixest)
library(lmtest)
library(sandwich)
# mise en forme des tables
library(broom)
library(gt)
# mise en forme des graphes
library(ggtext)
library(scales)Profitons-en également pour établir quelques fonctions que nous utiliserons par la suite.
# passage de la 2x2 diff-in-diff à la table des moyennes
tab_moy_2x2<-function(reg){
avant<-c(Controle=coef(reg)[1],
Traite=sum(coef(reg)[1:2]))
aprés<-c(Controle=sum(coef(reg)[c(1,3)]),
Traite=sum(coef(reg)))
tab_moy_new<-rbind(avant,aprés) %>%
data.frame() %>%
rename(Controle=`Controle..Intercept.`)
return(tab_moy_new)}
# table des moyennes mise en forme avec établissement des différences
tab_moy_diff<-function(tab_moy){
Controle<-c(tab_moy$Controle,
tab_moy$Controle[2]-tab_moy$Controle[1])
Traite<-c(tab_moy$Traite,
tab_moy$Traite[2]-tab_moy$Traite[1])
data.frame(Controle,Traite) %>%
mutate(diff=Traite-Controle,
rowname=c('Avant','Apres','diff')) %>%
column_to_rownames( var = "rowname") %>%
gt(rownames_to_stub = TRUE) %>%
tab_style(style = list(cell_fill(color = "lightcyan"),
cell_text(weight = "bold")),
locations = cells_body(columns = c(diff))) %>%
tab_style(style = list(cell_fill(color = "lightcyan"),
cell_text(weight = "bold")),
locations = cells_body(rows = c('diff')))%>%
tab_style(style = list(cell_fill(color = "#9FE2BF"),
cell_text(weight = "bold")),
locations = cells_body(rows = 3,
columns = 4)) }Ceci fait passons à notre première illustration.
Le changement de procédure d’admission
Revenons sur l’exemple mobilisé dans le post précédent (mais aussi dans la deuxième partie du post diff in diff - base 3). Il s’agit de l’exemple mobilisé dans les manuels de Stata. Chargeons les données à partir du site des manuels. Attention l’adresse est susceptible de changer en fonction des restructurations de ce “derniers.
dat1<-haven::read_dta("https://www.stata-press.com/data/r17/hospdd.dta")
head(dat1)## # A tibble: 6 × 5
## hospital frequency month procedure satis
## <dbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl>
## 1 1 3 [High] 7 [July] 1 [New] 4.11
## 2 1 2 [Medium] 3 [March] 0 [Old] 3.32
## 3 1 4 [Very high] 2 [February] 0 [Old] 3.41
## 4 1 2 [Medium] 4 [April] 1 [New] 3.00
## 5 1 1 [Low] 3 [March] 0 [Old] 3.11
## 6 1 1 [Low] 7 [July] 1 [New] 2.88Pour rappel, on a des mesures de la satisfaction des usagers pour 46 hôpitaux sur une période de 7 mois pour un total de 7 368 observations. Le 4ème mois certains hôpitaux ont changé leur procédure d’admission. Il s’agit ici déterminer l’effet causale de ce changement de procédure sur la satisfaction des usagers. Nous l’avons fait via une diff-in-diff.
Pour avoir un point de référence, ré-estimons l’ATET en utilisant les TWFE.
reg_f<-feols(satis~procedure| hospital + month,
data = dat1)
coeftest(reg_f,vcov.=vcovCL(reg_f,cluster=dat1$hospital)) %>%
round(digits = 7)##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## procedure 0.847988 0.031999 26.501 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1La nouvelle procédure semble bien augmenter la satisfaction des usagers des hôpitaux qui l’on mise en oeuvre. On a une augmentation de la satisfaction des traités post traitement en moyenne de 0,8479 par rapport à la satisfaction qu’ils auraient normalement connue sans traitement (et l’effet est fortement statistiquement significatif).
Mais ce résultat n’est juste que si l’hypothèse de parallel trend est plausible. Regardons cela via l’approche graphique en présentant la dynamique de l’effet du traitement via un event study plot.
dat1_<-dat1 %>%
group_by(hospital) %>%
mutate(Traite=ifelse(sum(procedure)==0,"Controles","Traités"),
post=month>=4) %>%
ungroup() %>%
mutate(m_cent3=month-3,
m_cent3f=relevel(factor(m_cent3),ref="0"))
reg_dyn <- feols(satis ~ m_cent3f*Traite |
hospital + month,
data = dat1_)
d_graph<-data.frame(temps=c(1,2,4:7),
beta=reg_dyn$coefficients,
coefci(reg_dyn,
vcov.=vcovCL(reg_dyn,cluster=dat1_$hospital),
level=0.95)) %>%
rename(bas=X2.5..,haut=X97.5..) %>%
remove_rownames() %>%
add_row(temps = 3, beta = 0, bas=0, haut=0, .after = 2)
ggplot(data=d_graph,aes(x=temps,y=beta))+
geom_hline(yintercept = 0, linetype="dashed")+
geom_vline(xintercept = 3,linetype="dashed")+
geom_errorbar(aes(ymin = bas,ymax=haut),width=0.2,linewidth=1)+
geom_point(color='red')+
labs(title="Effet dynamique du traitement ",
subtitle = "intervalle de confiance à 95%")+
scale_x_continuous(breaks = 1:7)+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(hjust=0.5),
axis.title = element_blank())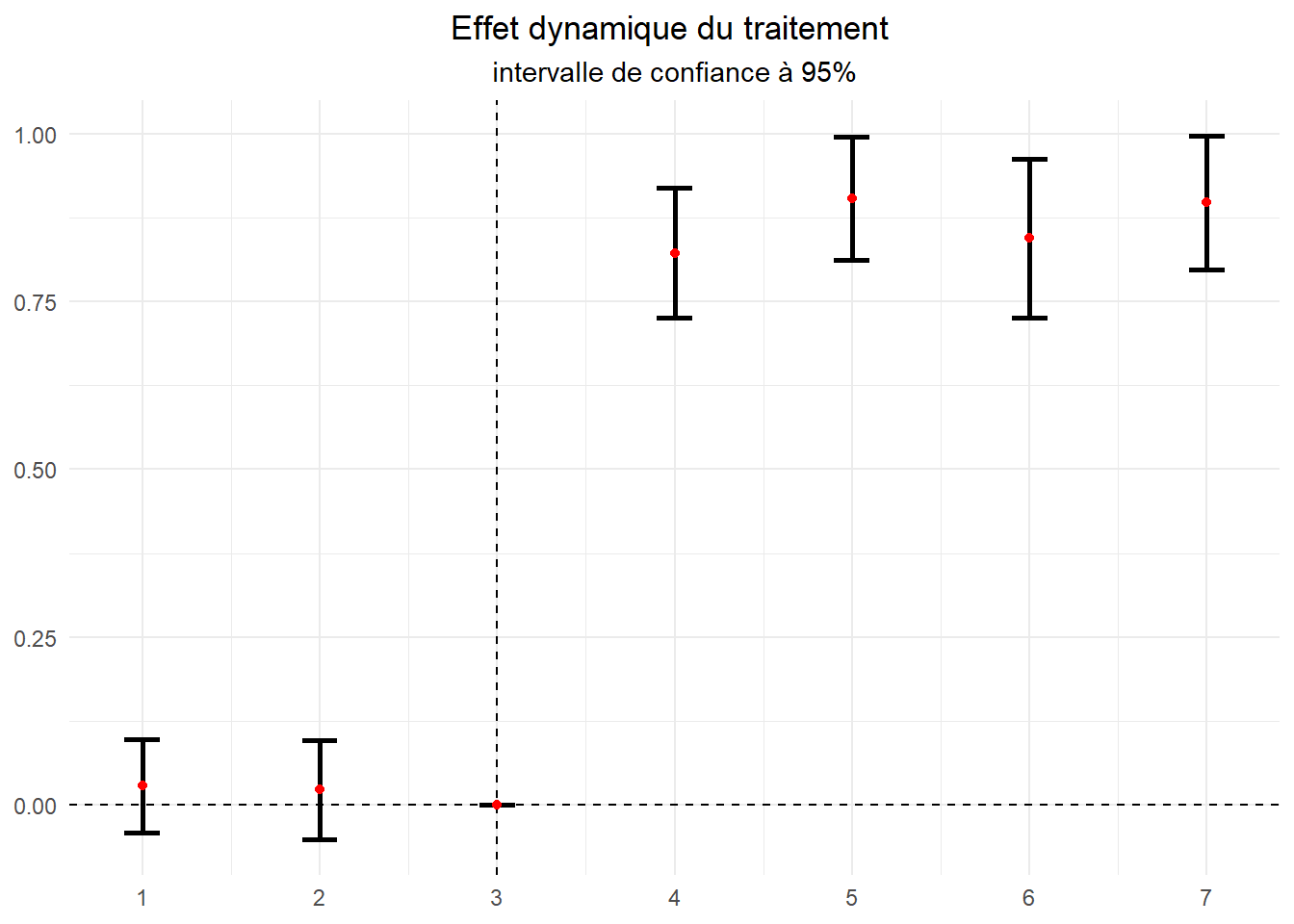
La lecture du graphe nous amène à rejeter l’hypothèse d’un défaut de parallel trend sur la période prétraitement. Les effets du traitement sur la période prétraitement ne sont pas statistiquement différents de 0. Les intervalles de confiance incluent la valeur 0 sur la période prétraitement. Cela nous a amené à valider l’effet positif sur la satisfaction des usagers de la mise en place de la nouvelle procédure d’admission.
Ce résultat a priori juste peut être questionné s’il existe une ou plusieurs variables non observées qui affectent à la fois le traitement et l’outcome (des confounding factors). Dans ce cas, la parallel trend ne serait plus tenue et l’estimation obtenue serait biaisée.
Ces caractéristiques inobservables pourraient, par exemple, être liées à la fréquence des visites à l’hôpital qui est une donnée dont nous disposons. Les individus fréquentant le plus souvent l’hôpital sur la période pourrait avoir une appréciation différente des autres du traitement. Il y aurait une évolution différente de la satisfaction des usagers en fonction de leur fréquence de visite en l’absence de traitement ce que constituerait une violation de la parallel trend.
Pour examiner la situation, commençons par coder deux nouvelles variables binaires: une prenant la valeur TRUE si la fréquence de visite est élevée, 3 ou 4, et FALSE dans le cas contraire (appelons la high); et une prenant également la valeur TRUE pour les hôpitaux traités sur la période post traitement si la fréquence de visite est élevée, 3 ou 4, et FALSE pour les autres configurations (appelons la hightrt - Il s’agit de l’interaction entre high et le traitement).
dat1_<-dat1_ %>%
mutate(high= frequency%in%c(3,4),
hightrt= procedure==1 & frequency%in%c(3,4),
.after=frequency)
head(dat1_)## # A tibble: 6 × 11
## hospital frequency high hightrt month procedure satis Traite post m_cent3
## <dbl> <dbl+lbl> <lgl> <lgl> <dbl+l> <dbl+lbl> <dbl> <chr> <lgl> <dbl>
## 1 1 3 [High] TRUE TRUE 7 [Jul… 1 [New] 4.11 Trait… TRUE 4
## 2 1 2 [Medium] FALSE FALSE 3 [Mar… 0 [Old] 3.32 Trait… FALSE 0
## 3 1 4 [Very h… TRUE FALSE 2 [Feb… 0 [Old] 3.41 Trait… FALSE -1
## 4 1 2 [Medium] FALSE FALSE 4 [Apr… 1 [New] 3.00 Trait… TRUE 1
## 5 1 1 [Low] FALSE FALSE 3 [Mar… 0 [Old] 3.11 Trait… FALSE 0
## 6 1 1 [Low] FALSE FALSE 7 [Jul… 1 [New] 2.88 Trait… TRUE 4
## # ℹ 1 more variable: m_cent3f <fct>Ceci étant fait voyons ce qu’il en est en estimant des modèles diff-in-diff pour chacun des sous-échantillons défini par high.
reg_false1<-lm(data=dat1_ %>% filter(high==TRUE),
satis~Traite*post)
reg_false2<-lm(data=dat1_ %>% filter(high==FALSE),
satis~Traite*post)
rbind(coeftest(reg_false1,
vcov.=vcovCL(reg_false1,cluster=dat1_%>%
filter(high==TRUE) %>%
select(hospital))) %>%
round(digits = 7) %>% tidy() %>% mutate(HIGH="Frequency > 3"),
coeftest(reg_false2,
vcov.=vcovCL(reg_false2,cluster=dat1_%>%
filter(high==FALSE) %>%
select(hospital))) %>%
round(digits = 7) %>% tidy() %>% mutate(HIGH="Frequency < 3")) %>%
group_by(HIGH) %>%
gt() %>%
tab_style(style = list(cell_fill(color = "#9FE2BF")),
locations = cells_body(rows = c(4,8))) %>%
fmt_number(decimal=5)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| Frequency > 3 | ||||
| (Intercept) | 3.42640 | 0.12177 | 28.13848 | 0.00000 |
| TraiteTraités | 0.09520 | 0.21963 | 0.43346 | 0.66471 |
| postTRUE | −0.00498 | 0.01789 | −0.27815 | 0.78091 |
| TraiteTraités:postTRUE | 1.26531 | 0.02732 | 46.31871 | 0.00000 |
| Frequency < 3 | ||||
| (Intercept) | 3.35911 | 0.14526 | 23.12460 | 0.00000 |
| TraiteTraités | 0.16941 | 0.21709 | 0.78040 | 0.43520 |
| postTRUE | −0.01499 | 0.02042 | −0.73393 | 0.46304 |
| TraiteTraités:postTRUE | 0.50132 | 0.02980 | 16.82263 | 0.00000 |
Dans les deux cas, l’effet du traitement impacte positivement et significativement la satisfaction des usagers mais à des niveaux différents. L’ATET est bien plus important pour les usagers fréquents (+1,26531) que pour les autres (+0,50132).
Pour compléter ce premier constat observons la dynamique du traitement sur les deux échantillons à partir d’un event study plot. Cela nous permettra de juger de la parallel trend sur la période prétraitement.
reg_dyn1 <- feols(satis ~ m_cent3f*Traite |
hospital + month,
data = dat1_ %>% filter(high==TRUE))
reg_dyn2 <- feols(satis ~ m_cent3f*Traite |
hospital + month,
data = dat1_ %>% filter(high==FALSE))
d_graph1<-data.frame(temps=c(1,2,4:7),
beta=reg_dyn1$coefficients,
coefci(reg_dyn1,
vcov.=vcovCL(reg_dyn1,
cluster=dat1_%>%
filter(high==TRUE) %>%
select(hospital)),
level=0.95)) %>%
rename(bas=X2.5..,haut=X97.5..) %>%
remove_rownames() %>%
add_row(temps = 3, beta = 0, bas=0, haut=0, .after = 2) %>%
mutate(HIGH="Frequency > 3")
d_graph2<-data.frame(temps=c(1,2,4:7),
beta=reg_dyn2$coefficients,
coefci(reg_dyn2,
vcov.=vcovCL(reg_dyn2,
cluster=dat1_%>%
filter(high==FALSE) %>%
select(hospital)),
level=0.95)) %>%
rename(bas=X2.5..,haut=X97.5..) %>%
remove_rownames() %>%
add_row(temps = 3, beta = 0, bas=0, haut=0, .after = 2) %>%
mutate(HIGH="Frequency < 3")
ggplot(data=rbind(d_graph1,d_graph2),aes(x=temps,y=beta,color=HIGH))+
geom_hline(yintercept = 0, linetype="dashed")+
geom_vline(xintercept = 3,linetype="dashed")+
geom_errorbar(aes(ymin = bas,ymax=haut),width=0.2,
linewidth=1)+
geom_point(color='red')+
labs(title="Effet dynamique du traitement ",
subtitle = "intervalle de confiance à 95%")+
scale_x_continuous(breaks = 1:7)+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(hjust=0.5),
axis.title = element_blank())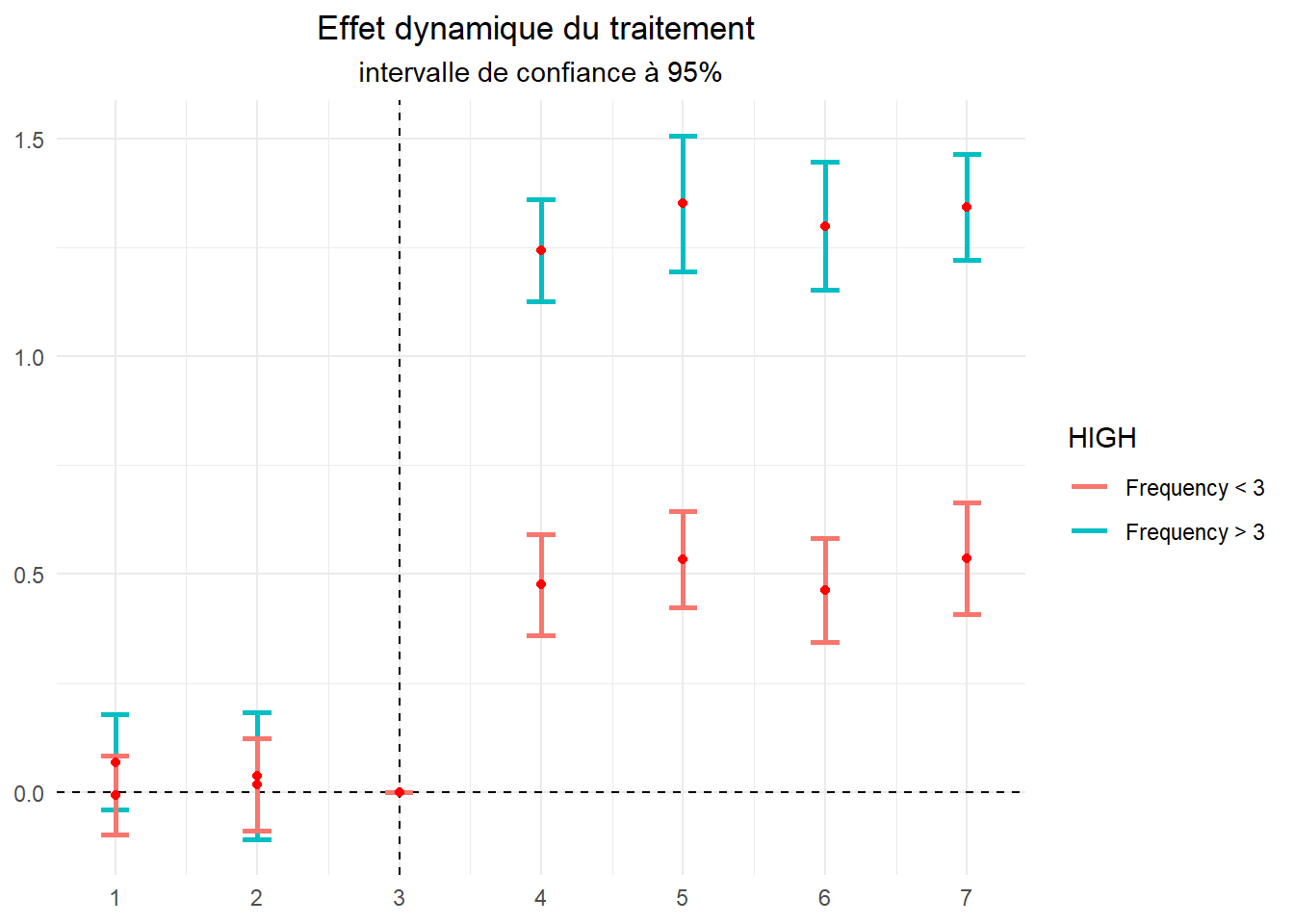
Pour les deux sous-échantillons, la parallel trend prétraitement semble vérifiée. Par ailleurs, sur cette période la dynamique des effets apparaît le même. S’il y a un défaut de parallel trend sur la période post traitement, il semble que celui-ci soit le même pour les deux groupes (en tout cas, c’est ce que montre la période pré traitement). S’il y a un biais, il est vraisemblablement le même sur les deux sous-échantillons. On parle de parallel biais.
Si l’on considère cette hypothèse comme vérifiée, il est possible de déterminer l’ATET corrigé de l’effet de la fréquence de visite (du biais associé au fait qu’il y est un cofounding factor que l’on peut appréhender via la fréquence de visites) en utilisant une triple différence (une diff-in-diff-in-diff).
Celle-ci consiste simplement à pratiquer une diff-in-diff non pas, comme nous l’avons fait jusqu’ici sur l’outcome moyenne, mais sur une relation. Cette relation est celle mise en évidence sur les groupes, l’ATET (biaisé), associés avec le cofounding factor (ici high).
Ici, la démarche est très différente de celle développée via les tests placebo (sur lesquels nous reviendrons prochainement) qui ne visent qu’à la falsification de la relation établie, infirmer l’effet causal mis en évidence sur l’analyse de base. L’échec de la falsification permettant de renforcer la conclusion vis-à-vis de l’effet du traitement (sur les traités). On cherche à estimer l’ATET en l’expurgeant du biais potentiel identifié.
La spécification du modèle estimé est proche du 2x2 diff-in-diff de base. On y ajoute la variable indicatrice génératrice du biais (high) ainsi que les nouvelles interactions associées (Traitexhigh, Postxhigh et TraitexPostxhigh). Cela nous donne:
\[\begin{aligned}satis = & \beta_0 + \beta_1 \cdot Traite + \beta_2 \cdot Post + \beta_3 \cdot high + \\ & \beta_4 \cdot Traite \times Post + \beta_5 \cdot Traite \times high + \\ & \beta_6 \cdot Post \times high + \beta_7 \cdot Traite \times Post \times high + \\ & \epsilon\end{aligned}\]
Estimons le modèle et présentons le résultat dans une table en mettant en évidence le coefficient de la triple interaction qui identifie l’ATET expurgé du biais.
reg_ddd1<-lm(data=dat1_,satis~Traite*post*high)
coeftest(reg_ddd1,vcov.=vcovCL(reg_ddd1,cluster=dat1_$hospital)) %>%
round(digits = 7) %>%
tidy() %>%
gt() %>%
tab_style(style = list(cell_fill(color = "#9FE2BF")),
locations = cells_body(rows = 8)) %>%
fmt_number(decimal=5)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 3.35911 | 0.14527 | 23.12265 | 0.00000 |
| TraiteTraités | 0.16941 | 0.21711 | 0.78033 | 0.43522 |
| postTRUE | −0.01499 | 0.02042 | −0.73387 | 0.46305 |
| highTRUE | 0.06729 | 0.06502 | 1.03496 | 0.30072 |
| TraiteTraités:postTRUE | 0.50132 | 0.02980 | 16.82121 | 0.00000 |
| TraiteTraités:highTRUE | −0.07421 | 0.09905 | −0.74928 | 0.45371 |
| postTRUE:highTRUE | 0.01001 | 0.02769 | 0.36155 | 0.71770 |
| TraiteTraités:postTRUE:highTRUE | 0.76398 | 0.03989 | 19.15044 | 0.00000 |
L’ATET est donc en moyenne une améliorations moyenne de la satisfaction des usagers de 0,76398, ce qui est moins que ce que nous avions mis en évidence avec la simple diff-in-diff (0,847988), mais ce qui reste assez proche et toujours fortement statistiquement significatif.
On peut, comme nous l’avions précédemment avec la diff-in-diff simple, recalculer les moyennes de l’outcome sur les sous-échantillons mobilisés. Mais, cette fois, on peut le faire en distinguant en plus en fonction de la variable définissant les biais identifiés (ici high). Faisons-le et présentons l’ensemble dans un tableau de synthèse faisant apparaître les multiples différences.
rbind(
# high == FALSE
data.frame(c("avant","apres","diff"),
Control=c(avant=reg_ddd1$coefficients[1],
apres=sum(reg_ddd1$coefficients[c(1,3)]),
diff=sum(reg_ddd1$coefficients[c(1,3)])-
reg_ddd1$coefficients[1]),
Traite=c(avant=sum(reg_ddd1$coefficients[c(1,2)]),
apres=sum(reg_ddd1$coefficients[c(1,2,3,5)]),
diff=sum(reg_ddd1$coefficients[c(1,2,3,5)])-
sum(reg_ddd1$coefficients[c(1,2)]))) %>%
mutate(diff=Traite-Control,HIGH="Frequency < 3"),
# high == TRUE
data.frame(c("avant","apres","diff"),
Control=c(avant=sum(reg_ddd1$coefficients[c(1,4)]),
apres=sum(reg_ddd1$coefficients[c(1,3,4,7)]),
diff=sum(reg_ddd1$coefficients[c(1,3,4,7)])-
sum(reg_ddd1$coefficients[c(1,4)])),
Traite=c(avant=sum(reg_ddd1$coefficients[c(1,2,4,6)]),
apres=sum(reg_ddd1$coefficients),
diff=sum(reg_ddd1$coefficients)-
sum(reg_ddd1$coefficients[c(1,2,4,6)]))) %>%
mutate(diff=Traite-Control,HIGH="Frequency > 3")) %>%
group_by(HIGH) %>%
gt() %>%
tab_style(style = list(cell_fill(color = "#9FE2BF"),
cell_text(weight = "bold")),
locations = cells_body(rows = c(3,6),
columns = c(4,4))) %>%
tab_style(style = list(cell_fill(color = "lightcyan")),
locations = cells_body(rows = c(1,2,4,5),
columns = 4)) %>%
tab_style(style = list(cell_fill(color = "lightcyan")),
locations = cells_body(rows = c(3,6),
columns = c(2,3))) %>%
fmt_number(decimal=5)| c..avant....apres....diff.. | Control | Traite | diff |
|---|---|---|---|
| Frequency < 3 | |||
| avant | 3.35911 | 3.52853 | 0.16941 |
| apres | 3.34413 | 4.01486 | 0.67074 |
| diff | −0.01499 | 0.48633 | 0.50132 |
| Frequency > 3 | |||
| avant | 3.42640 | 3.52160 | 0.09520 |
| apres | 3.42143 | 4.78194 | 1.36051 |
| diff | −0.00498 | 1.26033 | 1.26531 |
Parmi les différences mises en évidence, on retrouve les valeurs des diff-in-diff pratiquées sur les sous-échantillons définis par high (la fréquence de visite).
Établissons les tableaux de moyennes pour les deux sous-échantillons à partir des régressions en 2x2 diff-in-diff afin d’établir une comparaison. Commençons par les cas où la fréquence de visite est faible (high==FALSE).
tab_moy_diff(tab_moy_2x2(reg_false2))| Controle | Traite | diff | |
|---|---|---|---|
| Avant | 3.35911495 | 3.5285295 | 0.1694145 |
| Apres | 3.34412623 | 4.0148644 | 0.6707382 |
| diff | -0.01498872 | 0.4863349 | 0.5013236 |
On retrouve les valeurs affichés en début de tableau. Voyons l’autre groupe, les cas où la fréquence de visite est importante (high==TRUE).
tab_moy_diff(tab_moy_2x2(reg_false1))| Controle | Traite | diff | |
|---|---|---|---|
| Avant | 3.426404038 | 3.521604 | 0.09520015 |
| Apres | 3.421427589 | 4.781936 | 1.36050863 |
| diff | -0.004976449 | 1.260332 | 1.26530848 |
On retrouve la seconde partie du tableau. La triple différence correspond simplement à la différence entre ces deux doubles différences, la diff-in-diff pour high==TRUE moins la diff-in-diff pour high==FALSE.
unname(reg_false1$coefficients[4])-unname(reg_false2$coefficients[4])## [1] 0.7639849On a bien une différence de diff-in-diff.
L’estimation réalisée précédemment l’a été via une simple régression. Le même résultat peut être obtenu en TWFE en utilisant la commande suivante:
reg_DDD_TWFE_1 <- feols(satis ~ Traite*post*high | hospital + month,
data = dat1_)
coeftest(reg_DDD_TWFE_1,
vcov.=vcovCL(reg_DDD_TWFE_1,cluster=dat1_$hospital)) %>%
round(digits = 7) %>%
tidy() %>%
gt() %>%
tab_style(style = list(cell_fill(color = "#9FE2BF")),
locations = cells_body(rows = 5)) %>%
fmt_number(decimal=5)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| highTRUE | −0.01767 | 0.03983 | −0.44365 | 0.65731 |
| TraiteTraités:postTRUE | 0.50132 | 0.02979 | 16.82921 | 0.00000 |
| TraiteTraités:highTRUE | 0.03573 | 0.07022 | 0.50889 | 0.61084 |
| postTRUE:highTRUE | 0.01001 | 0.02768 | 0.36172 | 0.71757 |
| TraiteTraités:postTRUE:highTRUE | 0.76398 | 0.03987 | 19.15955 | 0.00000 |
Pour compléter cela, présentons un event study plot pour la triple différence et les deux doubles différences biaisées. Cela nous permettra d’observer les parallel trend prétraitement pour les trois séries d’estimations et d’avoir un visuel de leur positionnement respectif sur la période post traitement. Rappelons ici que concernant la parallel trend prétraitement pour les séries high=0 et high=1, il n’y a pas de problème si elle n’apparaît pas respectée ce qui compte c’est qu’elles souffrent toutes les deux du même biais. L’hypothèse fondamentale de la triple différence consiste en la présence d’un parallel bias sur les diff-in-diff comparées.
Procédons à l’estimation des modèles dynamiques à partir de feols() en utilisant une syntaxe un peu différente de celles mobilisées précédemment. Utilisons la fonction i() pour établir les variables d’interaction. Indiquons en premier argument la variable de temporalité (month) et en second celle qui sera déclinée en fonction de cette dernier. Indiquons, au surplus, la période de référence qui sera omis de la série générée. Ici, retenons le mois 3 (celui juste avant le traitement).
dat1_<-dat1_ %>%
mutate(trait_b=Traite=="Traités")
dyn_triple<-feols(satis ~ i(month, trait_b * high, ref = 3) +
i(month, trait_b, ref = 3) +
i(month, high, ref = 3) | hospital + month,
data = dat1_,cluster = ~hospital) %>%
tidy(conf.int = TRUE) %>%
filter(str_detect(term, "trait_b \\* high")) %>%
mutate(mois=as.numeric(str_extract(term, "\\d+")),
estimator="Triple Différence",
.before=estimate) %>%
select(mois, estimator, estimate, conf.low, conf.high) %>%
add_row(mois = 3, estimator = "Triple Différence",
estimate = 0, conf.low = 0, conf.high = 0) %>%
arrange(mois)
dyn_H_0<-feols(satis ~ i(month, trait_b , ref = 3) | hospital + month,
data = filter(dat1_,high==0), cluster = ~hospital) %>%
tidy(conf.int = TRUE) %>%
mutate(mois=as.numeric(str_extract(term, "\\d+")),
estimator="Diff in diff High=0",
.before=estimate) %>%
select(mois, estimator, estimate, conf.low, conf.high) %>%
add_row(mois = 3, estimator = "Diff in diff High=0",
estimate = 0, conf.low = 0, conf.high = 0) %>%
arrange(mois)
dyn_H_1<-feols(satis ~ i(month, trait_b , ref = 3) | hospital + month,
data = filter(dat1_,high==1), cluster = ~hospital) %>%
tidy(conf.int = TRUE) %>%
mutate(mois=as.numeric(str_extract(term, "\\d+")),
estimator="Diff in diff High=1",
.before=estimate) %>%
select(mois, estimator, estimate, conf.low, conf.high) %>%
add_row(mois = 3, estimator = "Diff in diff High=1",
estimate = 0, conf.low = 0, conf.high = 0) %>%
arrange(mois)
dt_dyn<-rbind(dyn_triple,dyn_H_0,dyn_H_1) %>% arrange(estimator,mois)
ggplot(dt_dyn,
aes(x = mois, y = estimate, color=estimator)) +
geom_hline(yintercept = 0, linetype = "dashed") +
geom_vline(xintercept = 3, linetype = "dashed")+
geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width = 0.1) +
geom_line() +
geom_point(color='red') +
labs(title = "Event Study : Impact du traitement",
subtitle = "Coefficient et IC (95%)",
color = "Modèle") +
scale_x_continuous(breaks=1:7)+
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5),
axis.title = element_blank(),
legend.position = "top",
legend.title = element_text(size=8),
legend.background = element_rect(color="black"))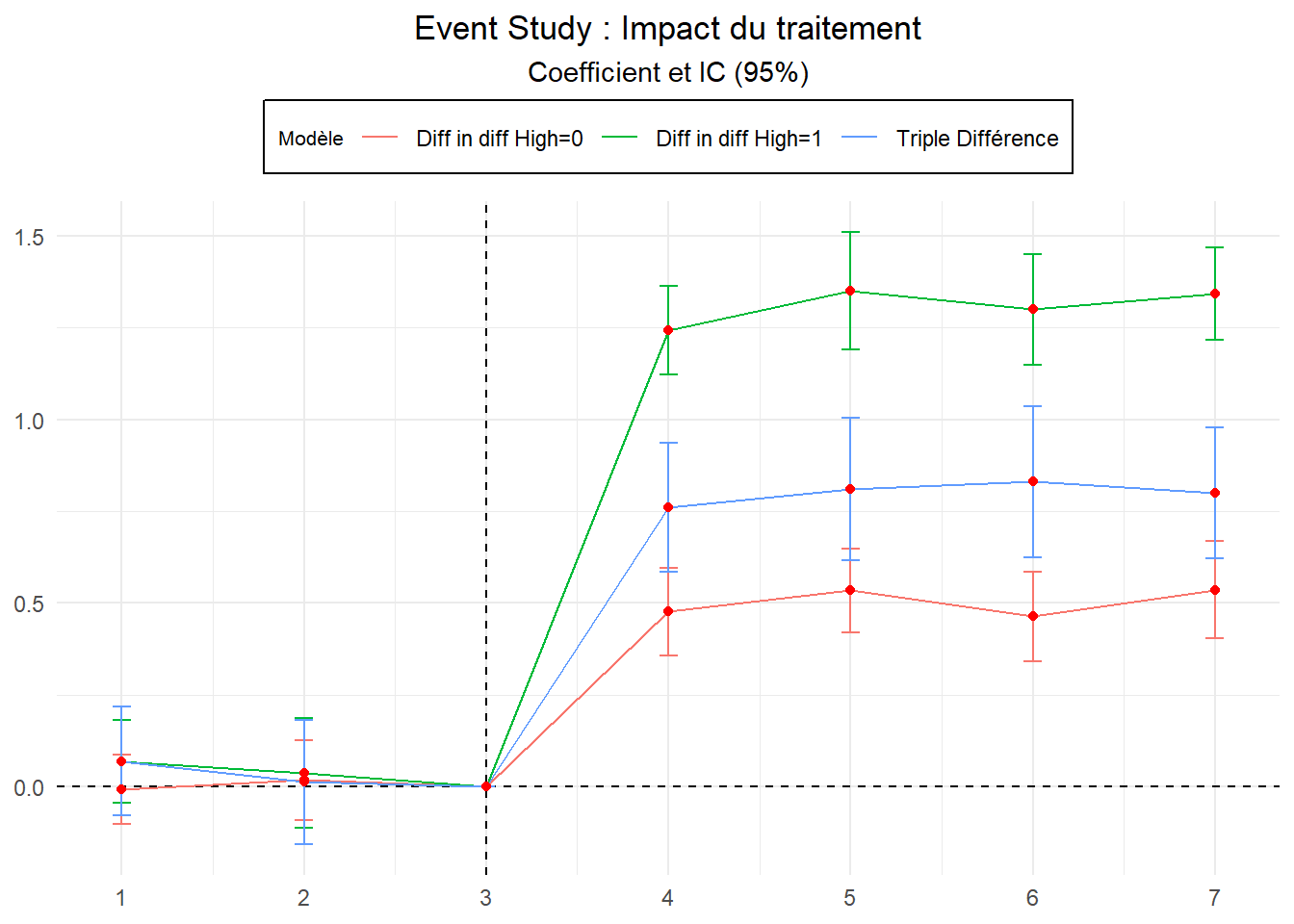
Concernant la parallel trend prétraitement, sans surprise, il n’apparaît pas de divergence. Par ailleurs, on voit bien que la dynamique de la triple différence la place en terme d’effet entre les deux séries biaisées (High=0 et High=1). Il y a même quelques chevauchements des intervalles de confiance avec la série High=0.
Si vous estimez la triple différence via Stata en utilisant didregress, vous n’obtiendrez pas tout à fait ce résultat mais un ATET de 0,764154. En fait, la commande utilise les effets fixes de manière à les saturer. Elle intègre à la fois les effets individuels (hospital), les effets temporels (month), les effets associés à la variable approchant le biais (frenquency) et les interactions de ces trois effets fixes.
On peut répliquer ce résultat. Commençons par utiliser, pour cela, feols() du package fixest. La variable mobilisée dans la régression pour mesurer l’ATET est cette fois hightrt. Elle prend la valeur TRUE pour les traités post traitement pour les usagers fréquents de l’hôpital (high==TRUE) et FALSE dans le cas contraire.
reg_DDD_TWFE_2 <- feols(satis ~ hightrt |
hospital + month + frequency +
hospital^month + hospital^frequency + month^frequency,
data = dat1_)
coeftest(reg_DDD_TWFE_2,
vcov.=vcovCL(reg_DDD_TWFE_2,cluster=dat1_$hospital)) %>%
tidy() %>%
gt() %>%
tab_style(style = list(cell_fill(color = "#9FE2BF")),
locations = cells_body(columns = 2)) %>%
fmt_number(decimal=5)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| hightrtTRUE | 0.76415 | 0.03893 | 19.62776 | 0.00000 |
Notions qu’ici, la jonction des effets fixes se fait avec ^. Utilisé après la | de la formule déclarée dans feols(), ce n’est pas un signe puissance mais le mode d’agrégation des variables retenues pour former l’effet fixe (un équivalent de paste()).
L’estimation de la triple différence est la même que celle obtenue via Stata. Par contre, on peut relever que estimation de la standard error est légèrement plus basse que dans ce que donne le logiciel (0,03893 contre 0,04026).
Utiliser lm() à la place de feols() permet de résoudre le problème.
reg_DDD_TWFE_3 <- lm(satis ~ hightrt +
factor(hospital) + factor(month) + factor(frequency) +
paste(hospital,month) + paste(hospital,frequency) +
paste(month,frequency),
data = dat1_)
coeftest(reg_DDD_TWFE_3,
vcov.=vcovCL(reg_DDD_TWFE_3,cluster=dat1_$hospital)) %>%
tidy() %>%
slice(2) %>%
gt() %>%
tab_style(style = list(cell_fill(color = "#9FE2BF")),
locations = cells_body(columns = 2)) %>%
fmt_number(decimal=5)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| hightrtTRUE | 0.76415 | 0.04026 | 18.98032 | 0.00000 |
Avant d’aborder un nouvel exemple, purgeons l’environnement.
rm(d_graph, d_graph1, d_graph2, dat1, dat1_, dt_dyn, dyn_H_0, dyn_H_1,
dyn_triple, reg_DDD_TWFE_1, reg_DDD_TWFE_2, reg_DDD_TWFE_3,
reg_ddd1,reg_dyn, reg_dyn1, reg_dyn2, reg_f, reg_false1, reg_false2)Incidence de la gonorrhée et légalisation de l’avortement
Attaquons nous à un exemple plus sophistiqué : le test des effets de la légalisation de l’avortement sur le taux d’incidence de la gonorrhée aux Etats-Unis. Il s’agit de l’exemple développé par Scott Cunningham dans son livre Causal Inference Mixtape (que je recommande fortement). Il tire celui-ci d’une étude qu’il a lui-même publié @cornwell2013 .
L’idée est la suivante. Dans un papier qui a fait pas mal de bruit, @donohue2001 apportent des éléments empiriques qui tendrait à montrer que la légalisation de l’avortement aux Etats-Unis dans les années 1970 aurait eu un important impact de long terme (vingt ans après) sur la criminalité. Leur point est que les avortements auraient concerné plus fréquemment des individus en devenir qui auraient connu un futur compliqué qui les aurait amené à avoir des problèmes avec la justice. Ces résultats ont, bien entendu, suscité la polémique. Celle-ci est allée au-delà des potentiels eugénistes de leurs implications. Elle s’est porté notamment sur la validité des protocoles mis en oeuvre pour les mettre au jour. @joyce2009 relèvent ainsi que, si l’effet de sélection allégué est aussi important que ce qui est mis en avant par les auteurs, il devrait avoir des conséquences sur bien d’autres phénomènes que la criminalité.
C’est sur ce point que la papier de Cunningham rebondi. Il cherche à identifier l’effet causale via une méthode de type diff-in-diff de la légalisation de l’avortement sur la prévalence d’une maladie sexuellement transmissible la gonorrhée. Si l’effet de sélection est tel que ce que le postule Levitt, il devrait également avoir des conséquences sur la prévalence de la maladie pour les générations concernées. Les populations qui aurait été normalement les plus à risque étant sorties de l’échantillon puisque pas née.
Reste qu’il faut pouvoir identifier le lien. Pour ce faire, les auteurs exploitent le fait que cinq Etats avaient autorisé l’avortement (abrogés les lois anti-avortement) trois ans avant que l’arrêt de la cours suprême Roe vs Wade en 1973 vienne le légaliser dans l’ensemble du pays. L’effet de cette autorisation anticipée devrait conduire à une différence de prévalence de la MST, une prévalence moins importante, chez les adolescents sur les générations nées dans les années où l’avortement était autorisé dans leurs Etats et pas dans les autres. La différence postulée doit de plus évoluer dans le temps.
Les données utilisées ne permettent pas de travailler avec des âges exactes. Seuls des classes d’âge sont disponibles par bloc de 5 ans. Le groupe étudié ici est les 15-19 ans. La composition de ce groupe évolue dans le temps ceux qui ont 15 ans en 1985 sont nés en 1970, ceux qui ont 15 ans en 1986 sont nés en 1971 et ainsi de suite. Le traitement est le fait d’être née dans un des Etats anticipant la légalisation générale (les repeal states), les traités. On devrait ainsi pour eux constater un déclin de l’incidence de la gonorrhé chez les individus ayant 15 ans en 1986 pour les traités relativement au groupe de contrôle (les Roe states). En 1987, deux cohortes sont traitées (les 15 ans, né en 1972 et 16 ans, né en 1971). On devrait constaté un déclin encore plus fort que celui constaté en 1986. Mais de 1988 à 1991, la différence devrait commencer à s’effacer puisque la génération née en 1973 entre dans le groupe (elle a 15 ans en 1988) et donc le traitement perd de son pouvoir de différenciation. Les Etats Roe effacent la différence. A partir de 1992, il ne devrait plus y avoir de différence dans la mesure où les générations intégrées dans le groupes sont toutes sous le même régime en terme de droit à l’avortement.
Autrement-dit, on devrait être en mesure de mettre en évidence une dynamique particulière des effets du traitement, une parabole inversée (coefficient diff-in-diff de plus en plus négatifs, puis de moins en moins pour finir par être nul), si le droit à l’avortement a l’effet sélectif escompté (que les populations les plus à risque sont bien celles qui sont le plus fréquemment sortis du jeu comme l’affirme Levit).
Mais avant d’aller plus loin, commençons par charger les données utilisées. Elles sont disponibles sur github comme élément d’accompagnement de l’illustration du chapitre dédié à la diff-in-diff du mixtape de Cunningham. On peut les obtenir simplement via le lien https://github.com/scunning1975/mixtape/raw/master/abortion.dta.
dat_av<-haven::read_dta("https://github.com/scunning1975/mixtape/raw/master/abortion.dta")
head(dat_av)## # A tibble: 6 × 39
## fip age race year sex totcase totpop rate totrate id ir crack
## <dbl> <dbl+l> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 30 2 1985 1 1487 78805 2646. 1887. 19 371. 0.217
## 2 1 15 1 1985 2 859 224003 580. 384. 2 51.4 0.217
## 3 1 20 2 1985 2 7563 94113 7464. 8036. 16 391. 0.217
## 4 1 20 1 1985 1 1283 252076 368. 509 3 101. 0.217
## 5 1 20 2 1985 1 7563 94113 8708. 8036. 15 391. 0.217
## 6 1 40 2 1985 1 191 48527 569. 394. 23 199. 0.217
## # ℹ 27 more variables: alcohol <dbl>, income <dbl>, ur <dbl>, poverty <dbl>,
## # black <dbl>, perc1519 <dbl>, perc <dbl>, repeal <dbl>, aids <dbl>,
## # aidscapita <dbl>, ac <dbl>, acc <dbl>, trend <dbl>, tsq <dbl>, blk <dbl>,
## # wht <dbl>, male <dbl>, female <dbl>, lnr <dbl>, t <dbl>, younger <dbl>,
## # fa <dbl>, pi <dbl>, wm15 <dbl>, wf15 <dbl>, bm15 <dbl>, bf15 <dbl>Voyons ce que l’on a et procédons à quelques mises en forme.
La première variable fip correspond au FIPSCODE, autrement-dit au code administratif de l’État sur lequel les mesures sont réalisées. Elle a 56 valeurs différentes, une par État défini par ordre alphabétique allant de 1 pour l’Alabama à 56 pour la Wyoming. La variable est au format numérique double ce qui pose problème pour la suite. Passons-la en facteur de manière à pouvoir l’utiliser comme effets fix individuels plus facilement.
dat_av<-dat_av %>%
mutate(fip=as_factor(fip))
var_label(dat_av$fip) <- "code Etat (FIPCODE) de 1 Alabama à 56 Wyoming"La seconde variable age indique la classe d’âge sur lesquelles les mesures sont réalisées. Il s’agit d’une variable numérique double mais avec étiquette. Voyons cela.
unique(dat_av$age)## <labelled<double>[6]>: AGE
## [1] 30 15 20 40 35 25
##
## Labels:
## value label
## 1 1. 0-4
## 2 2. 10-14
## 3 3. 15-19
## 4 4. 20-24
## 5 5. 25-29
## 6 6. 30-34
## 7 7. 35-39
## 8 8. 40-44
## 9 9. 45-54
## 10 10. 5-9
## 11 11. 55-64
## 12 12. 65+
## 13 13. UnkL’ensemble des valeurs possibles n’est pas présente. En fait, on a six groupes d’âge correspondant à des regroupements de 5 ans: 15-19; 20-24; 25-29; 30-34; 35-39; 40-44. Chaque groupe est indiqué via son âge minimum. On a ainsi respectivement 15, 20, 25, 30, 35 et 40. Nous pourrions en faire un facteur mais ce n’est pas nécessaire pour la suite. Contentons nous de revoir l’étiquette générale pour la rendre plus claire.
var_label(dat_av$age) <- "groupes d'âge (6 groupes de 5 ans indiqués par l'âge de début)"Les trois variables qui suivent indiquent la race du groupe, l’année de mesure, et le sexe du groupe. Les étiquettes associées sont assez claires. Seule year doit être retouchée pour éviter qu’elle ne soit traitée par la suite comme une variable numeric classique. Passons-la en facteur.
dat_av<-dat_av %>%
mutate(year=as_factor(year))
var_label(dat_av$year) <- "année de mesure"totcase est le nombre de cas recensée dans l’État considéré, l’année considérée pour le groupe d’âge et de race considéré. totpop est total de l’État considéré, l’année considérée pour le groupe d’âge et de race considéré.
rate est le nombre de cas par 100 000 habitants recensés l’année considérée, dans l’État considéré, sur le groupe défini par l’interaction classe d’age, race et sexe. C’est sont logarithme, lnr, qui sera l’outcome dans les analyses qui suivront. Complétons les étiquettes de ces deux variables pour les rendre plus parlantes.
var_label(dat_av) <- list(rate = "nombre de cas de gonorrhé pour 100 000 habitants",
lnr = "log du taux d'incidence (rate)")On a ainsi si l’on résume les variables.
look_for(dat_av,details="none")## pos variable label
## 1 fip code Etat (FIPCODE) de 1 Alabama à 56 Wyoming
## 2 age groupes d'âge (6 groupes de 5 ans indiqués par l'âge de début)
## 3 race w-1, b-2
## 4 year année de mesure
## 5 sex m-1, f-2
## 6 totcase TOTCASE
## 7 totpop TOTPOP
## 8 rate nombre de cas de gonorrhé pour 100 000 habitants
## 9 totrate TOTRATE
## 10 id group(fip race age sex)
## 11 ir Incarcerated Males per 100,000
## 12 crack Crack index
## 13 alcohol Alcohol consumption per capita
## 14 income Real income per capita
## 15 ur State unemployment rate
## 16 poverty Poverty rate
## 17 black Percent black
## 18 perc1519 Percent 15-19 yo
## 19 perc —
## 20 repeal —
## 21 aids AIDS mortality in t
## 22 aidscapita AIDS mortality per 100,000 in t
## 23 ac AIDS mortality cumulative in t, t-1, t-2, t-3
## 24 acc AIDS mortality per 100,000 cumulative in t, t-1, t-2, t-3
## 25 trend —
## 26 tsq —
## 27 blk Black Indicator
## 28 wht White Indicator
## 29 male Male Indicator
## 30 female Female Indicator
## 31 lnr log du taux d'incidence (rate)
## 32 t —
## 33 younger —
## 34 fa —
## 35 pi —
## 36 wm15 —
## 37 wf15 —
## 38 bm15 —
## 39 bf15 —Les dernières variables de la liste correspondent à une série de variables binaires marquant l’appartenance des observations à un des groupes d’intérêt, un groupe d’individu qui permettrait de détecter potentiellement l’effet que l’on cherche à mesurer. On a ainsi wm15 qui correspond aux individus masculins désignés comme blancs entre 15 et 20 ans, wf15 qui correspond aux individus féminins désignés comme blancs entre 15 et 20 ans, etc…
Nous travaillerons sur le sous-échantillon des jeunes femmes afrodécendantes désigné par la variable bf15. Les résultats sont réplicables sur les autres sous-échantillons (wf15, wm15 et bm15).
Mais avant de voir si la dynamique du traitement est telle que ce que l’on attend, voyons les tendances générales sur la période d’étude pour les deux populations comparés : les Repeal states (ceux qui ont légalisé l’avortement 3 ans avant les autres) et les Roe states (les autres); concernant la prévalence de la maladie.
dat_av %>%
filter(bf15==1) %>%
summarise(moy=mean(rate,na.rm=TRUE),.by=c(repeal,year)) %>%
mutate(year = as.numeric(as.character(year))) %>%
ggplot(aes(x=year,y=moy,color=factor(repeal,labels = c('Roe','Repeal')),
group = factor(repeal))) +
geom_point()+
geom_line()+
annotate("rect", xmin = 1986, xmax = 1992, ymin = 500, ymax = 6500,
alpha = .2)+
labs(title="Taux d'incidence de la gonorrhée",
subtitle="Femmes afrodécendantes / classe d'âge 15-19 ans",
y="incidence pour 100 000 individus")+
scale_x_continuous(breaks=1985:2000)+
scale_y_continuous(breaks=seq(1000,5500,500),labels=label_number())+
scale_color_manual(values=c("blue","red"))+
coord_cartesian(ylim=c(800,5500),xlim=c(1985,2000))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face="bold"),
plot.subtitle = element_text(hjust=0.5,face="bold"),
axis.line = element_line(color="black"),
axis.ticks = element_line(color="black"),
axis.title.x = element_blank(),
axis.text.x = element_text(angle=90,vjust=0.5),
panel.grid = element_blank(),
legend.position = "top",
legend.title = element_blank()
)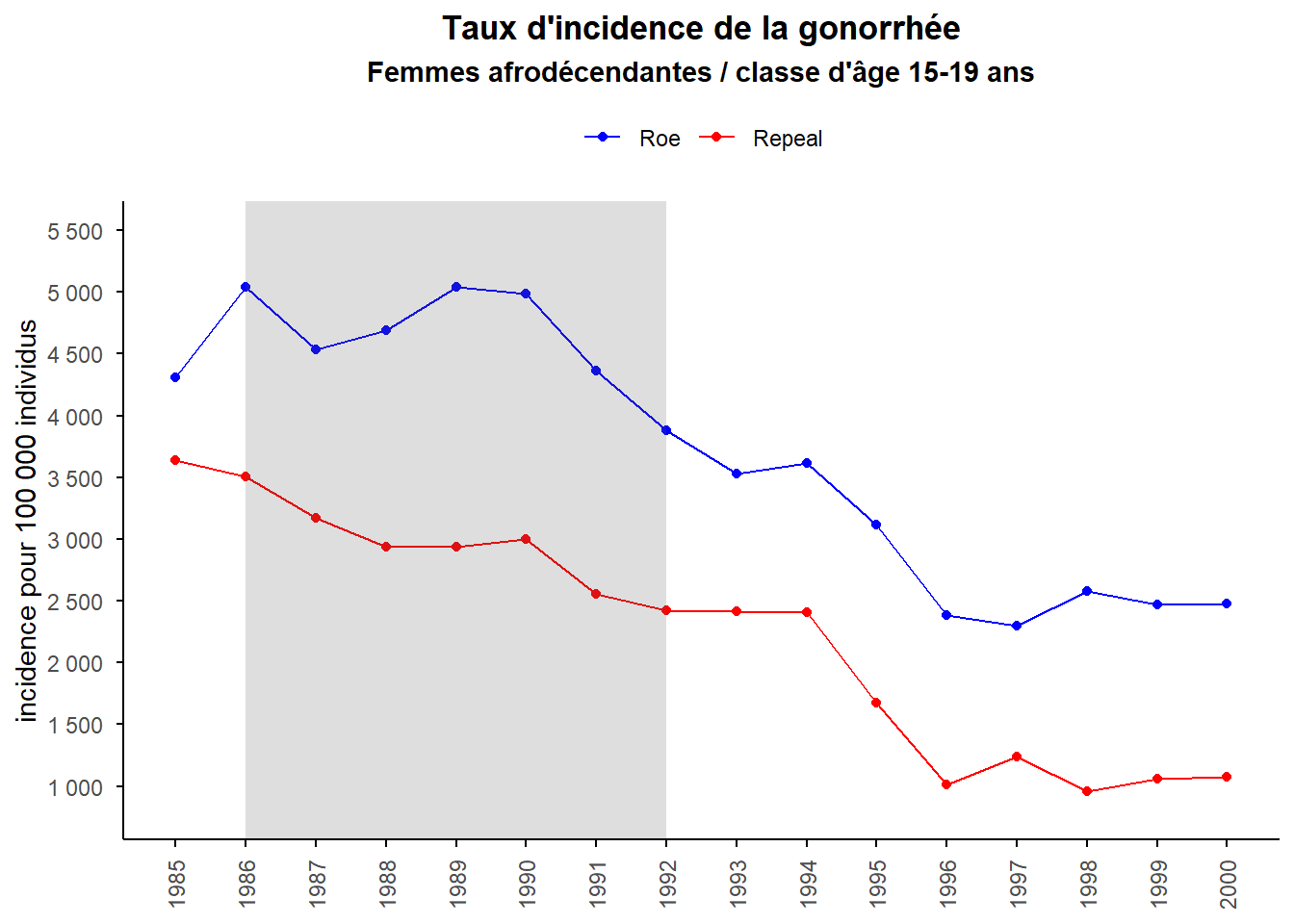
On observe que sur toute la période d’étude les Repeal states présentent un taux d’incidence inférieur au Roe states et que l’évolution de ce taux d’incidence semble globalement suivre une tendance parallèle (ce qui est rassurant pour notre stratégie d’identification) à l’exception de la période 1986-92 pour laquelle un léger décalage semble apparaître. Cette sous période est celle pour laquelle, les générations traités différemment quant à la possibilité d’avortement entre puis sortent progressivement de l’échantillon (la période pendant laquelle elles ont entre 15 et 20 ans).
Ce premier constat est rassurant quand à la perspective de mettre au jour l’effet attendu. Allons plus loin et procédons à l’estimation du modèle Diff-in-Diff dynamique. Mais avant d’aller plus loin posons ici sa spécification:
\[Y_{s,t}=\beta_1.Repeal_s+\beta_2.DT_t+\beta_{3t}.Repeal_s\times DT_t+\gamma. Control+\epsilon_{s,t}\]
\(Y_{s,t}\) est le logarithme de la prévalence de la gomorrhée dans l’Etat s l’année t (lnr). Repeal_s est une variable indicative prenant la valeur 1 sur l’Etat est un Repeal state. DT_t est une série de variables indicatrice marquant l’année d’observation. Control représente une série de variables de contrôles mobilisées pour l’estimation : des effets fixes Etat (fip), la mortalité du sida dans l’Etat les trois dernières année (acc), la proportion d’hommes incarcérés pour 100 000 habitants (ir), une dummy indiquant si l’année en question dans l’Etat en question s’applique une loi sur l’implication parentale imposant l’avis des parents pour un mineur qui voudrait recourir à l’avortement (pi), la consommation d’alcool par habitant (alcohol), l’indice de prévalence du crack (crack), le taux de pauvreté (poverty), le revenu réel par habitant (income) et le taux de chômage (ur).
Dans le modèle, ce qui va nous intéresser, c’est \(\beta_{3t}\). Il donne une série de coefficients associés à l’interaction repeal année. Autrement-dit, il donne l’effet du traitement, la différence de taux d’incidence moyen de la gonorrhée entre les repeal state et les roe state pour les différentes années d’étude. Leur évolution marque la dynamique du traitement pour laquelle les hypothèses ont été formulé (parabole inversé au début puis non statistiquement significatif).
Ceci étant posé, procédons à l’estimation. Pour ce faire, utilisons la fonction lm_robust() du package estimatr. Elle permet d’obtenir de manière efficace des estimations de modèles linéaires avec correction des erreurs-types, particulièrement adaptée aux jeux de données de taille modérée. Pour ce type de données, l’utilisation de lm() suivie de coeftest() est non seulement plus laborieuse, mais peut aussi conduire à des instabilités de calculs pour les corrections plus exigeantes que HC1. En l’occurrence, nous devons établir des erreurs-types corrigées pour le clustering. Par défaut, vcovCL() de sandwich utilise la correction HC1, qui applique un facteur de correction global et uniforme (fonction des degrés de liberté). À l’inverse, lm_robust() utilise par défaut la correction HC2 (ou CR2). Celle-ci est plus fine : au lieu d’une correction globale, elle ajuste chaque observation individuellement en fonction de son levier (son poids mathématique dans la détermination du coefficient), garantissant ainsi une inférence plus robuste, même en présence de clusters déséquilibrés. Ici, nous opterons pour la correction pour les petits échantillons dans un contexte de clustering proposée par défaut par Stata, la CR1. Pour ce faire, nous utiliserons l’option se_type en indiquant “stata” (c’est le choix fait par Cunningham, même si son code de réplication ne l’indique pas…).
Procédons à la régression et établissons à partir des standard errors obtenus des p.value pour les tests portant sur la coefficient en considérant que l’échantillon est suffisamment grand pour assurer la convergence de la statistique de Student vers une loi normale standard. Ce dernier point est contestable (lm_robust() procède à un ajustement des degrés de liberté du test de Student qui les réduits fortement, ici l’ajustement de Satterthwaite qui vise assurer la cohérence des tests avec la balance des données). Néanmoins, afin de simplifier les choses et suivre les choix de présentation réalisés par Cunningham dans le chapitre de Mixtape, nous procéderons ainsi. Ces questions de tests seront traitées dans un prochain post (voir plusieurs compte tenu de la complexité et de la technicité du sujet).
reg_DD <- dat_av %>%
filter(bf15 == 1) %>%
estimatr::lm_robust(lnr ~ repeal*year +
fip +
acc + ir + pi + alcohol+ crack + poverty+ income+ ur,
data = ., weights = totpop, clusters = fip,
se_type = "stata")
reg_DD %>%
tidy() %>%
select(term,estimate,std.error,statistic) %>%
mutate(p.value=2*(1-pnorm(abs(statistic)))) %>%
slice(76:90) %>%
gt() %>%
fmt_number(decimals = 3)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| repeal:year1986 | −0.259 | 0.063 | −4.092 | 0.000 |
| repeal:year1987 | −0.342 | 0.168 | −2.030 | 0.042 |
| repeal:year1988 | −0.611 | 0.203 | −3.014 | 0.003 |
| repeal:year1989 | −0.785 | 0.237 | −3.310 | 0.001 |
| repeal:year1990 | −0.632 | 0.176 | −3.596 | 0.000 |
| repeal:year1991 | −0.553 | 0.139 | −3.966 | 0.000 |
| repeal:year1992 | −0.442 | 0.160 | −2.759 | 0.006 |
| repeal:year1993 | −0.306 | 0.181 | −1.693 | 0.090 |
| repeal:year1994 | −0.118 | 0.207 | −0.570 | 0.568 |
| repeal:year1995 | 0.021 | 0.223 | 0.094 | 0.925 |
| repeal:year1996 | −0.124 | 0.207 | −0.598 | 0.550 |
| repeal:year1997 | 0.021 | 0.264 | 0.079 | 0.937 |
| repeal:year1998 | −0.036 | 0.347 | −0.104 | 0.917 |
| repeal:year1999 | 0.015 | 0.357 | 0.041 | 0.967 |
| repeal:year2000 | 0.041 | 0.387 | 0.107 | 0.915 |
On peut noter que l’on retrouve bien des coefficients sur les années (1986 à 1992) où l’effet est attendu qui présentent la structure en parabole inversée prévue. La période est d’ailleurs la seule à apparaître statistiquement significative et le retournement (le plus bas de la parabole inversée) intervient visiblement en 1989. Visualisons cela en retenant pour chaque année un intervalle de confiance à 95% (encore une fois construit sur la base d’une loi normale).
tibble(year = c(1986:2000),
mean = reg_DD[[1]][76:90],
sd = reg_DD[[2]][76:90]) %>%
ggplot(aes(x = year, y = mean)) +
geom_point()+
geom_hline(yintercept = 0) +
geom_errorbar(aes(ymin = mean - sd*1.96, ymax = mean + sd*1.96), width = 0.2,
position = position_dodge(0.05))+
annotate("rect", xmin = 1986, xmax = 1992, ymin = -2, ymax = 2,
alpha = .2)+
labs(title="Effet estimé de la légalisation de l'avortement sur la gonorrhée",
subtitle="Femmes afrodécendantes / classe d'âge 15-19 ans",
y="Coefficient d'interaction repeal année")+
scale_x_continuous(breaks=1985:2000)+
coord_cartesian(expand=FALSE,xlim=c(1985,2001))+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5,face="bold"),
plot.subtitle = element_text(hjust=0.5,face="bold"),
axis.line = element_line(color="black"),
axis.ticks = element_line(color="black"),
axis.title.x = element_blank(),
axis.text.x = element_text(angle=90,vjust=0.5),
panel.grid = element_blank())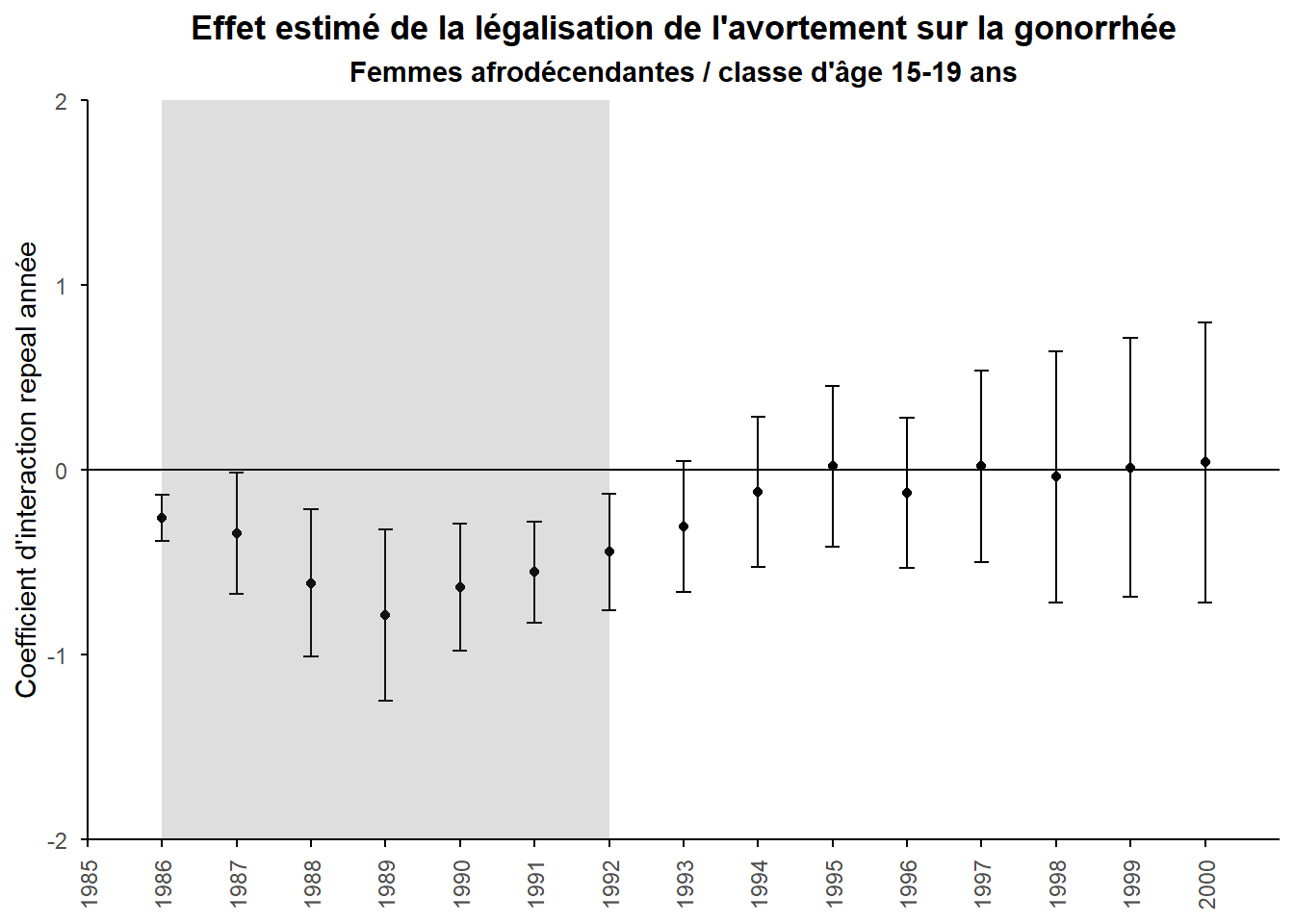
Le graphe confirme visuellement ce que l’on lisait dans la table de régression. Bref, l’hypothèse de départ aussi sophistiquée qu’elle soit semble bien vérifiée.
Mais, qu’en est-il des triples différences ici. Nous y venons. Cunningham rappel que pour identifier un effet causale. Il est à la fois nécessaire de mettre en évidence l’effet en question, mais aussi de parvenir à exclure les explications alternatives. Pour ce faire, une des méthodes consiste à pratiquer une analyse placebo rigoureuse.
Il propose alors d’utiliser une triple de différence dans laquelle est mobilisée une cohorte non traité en l’occurrence des individus nés dans un des repeal states avant que ceux-ci ne légalisent l’avortement. Il choisi les 25-29 ans. Il justifie ce choix par le fait que l’écart d’âge avec le groupe initial des traités (15-19 ans) est à la fois suffisamment petit pour qu’une tendance commune existe (potentiellement) et pour que les groupes ne se contaminent pas l’un l’autre (il y a peu de probabilité que les 15-19 ans aient des relations qui transmettent la gonorrhée avec les 25-29 ans). Ce que l’on cherche, ce sont des individus suffisamment proches pour pouvoir être affectés par un même facteur caché (nécessairement autre que le légalisation de l’avortement autour de leur année de naissance). Facteur qui influencerait la prévalence de la gonorrhée sur les 15-19 ans des repeal states sans qu’il y ait de contaminations croisées (importantes) entre les deux groupes.
Le test pourrait simplement consister à réaliser une analyse en double différence sur la cohorte placebo (les 25-29 ans). On ne devrait alors pas constater de dynamique d’effet (de différence entre les repeal state et les roe state) comparable à celle des 15-19 ans. Néanmoins, même si le test confirme l’absence d’effet sur le groupe placebo, il ne précise pas l’estimation causale réalisée à partir du groupe des traités. Avant de voir comment la triple différence aide sur ce point, réalisons le test en double différence sur le groupe placebo.
Commençons par créer une variable permettant de désigner les femmes afrodéscendantes. Puis, limitons la base à ce groupe en ajoutant la condition d’avoir entre 25-29 ans. Une fois délimité l’échantillon sur lequel nous allons travailler (femmes afrodéscendantes appartenant à la cohorte 25-29 ans) procédons à l’estimation du même modèle que précédemment (traitement repeal). Présentons la tables des coefficients marquant la dynamique de l’effet.
b_lim<-dat_av %>%
mutate(bf=as_factor(case_when(wht == 0 & male == 0 ~ 1, TRUE ~ 0))) %>%
filter(bf==1 & age==25)
reg_DD_25 <- b_lim %>%
estimatr::lm_robust(lnr ~ repeal*year +
fip +
acc + ir + pi + alcohol+ crack + poverty+ income+ ur,
data = ., weights = totpop, clusters = fip,
se_type = "stata")
reg_DD_25 %>%
tidy() %>%
select(term,estimate,std.error,statistic) %>%
mutate(p.value=2*(1-pnorm(abs(statistic)))) %>%
slice(76:90) %>%
gt() %>%
fmt_number(decimals = 3)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| repeal:year1986 | 0.187 | 0.194 | 0.968 | 0.333 |
| repeal:year1987 | 0.167 | 0.181 | 0.920 | 0.357 |
| repeal:year1988 | −0.024 | 0.248 | −0.095 | 0.924 |
| repeal:year1989 | −0.223 | 0.290 | −0.767 | 0.443 |
| repeal:year1990 | −0.253 | 0.260 | −0.972 | 0.331 |
| repeal:year1991 | −0.272 | 0.266 | −1.020 | 0.308 |
| repeal:year1992 | −0.177 | 0.305 | −0.582 | 0.560 |
| repeal:year1993 | 0.221 | 0.477 | 0.465 | 0.642 |
| repeal:year1994 | 0.020 | 0.316 | 0.064 | 0.949 |
| repeal:year1995 | 0.195 | 0.380 | 0.513 | 0.608 |
| repeal:year1996 | −0.031 | 0.339 | −0.090 | 0.928 |
| repeal:year1997 | −0.098 | 0.374 | −0.263 | 0.793 |
| repeal:year1998 | 0.068 | 0.397 | 0.171 | 0.864 |
| repeal:year1999 | 0.104 | 0.445 | 0.233 | 0.816 |
| repeal:year2000 | 0.084 | 0.381 | 0.222 | 0.825 |
On note qu’aucun des coefficients n’est statistiquement significatif et cela quelle que soit la période. Il n’y a pas de différence entre les repael et les roe state en terme d’incidence de la gonorrhée pour cette génération. On le voit très clairement sur le graphe ci-contre.
tibble(year = c(1986:2000),
mean = reg_DD_25[[1]][76:90],
sd = reg_DD_25[[2]][76:90]) %>%
ggplot(aes(x = year, y = mean)) +
geom_point()+
geom_hline(yintercept = 0) +
geom_errorbar(aes(ymin = mean - sd*1.96, ymax = mean + sd*1.96), width = 0.2,
position = position_dodge(0.05))+
annotate("rect", xmin = 1986, xmax = 1992, ymin = -2, ymax = 2,
alpha = .2)+
labs(title="Effet estimé de la légalisation de l'avortement sur la gonorrhée",
subtitle="Femmes afrodécendantes / classe d'âge 25-29 ans",
y="Coefficient d'interaction repeal année")+
scale_x_continuous(breaks=1985:2000)+
coord_cartesian(expand=FALSE,xlim=c(1985,2001))+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5,face="bold"),
plot.subtitle = element_text(hjust=0.5,face="bold"),
axis.line = element_line(color="black"),
axis.ticks = element_line(color="black"),
axis.title.x = element_blank(),
axis.text.x = element_text(angle=90,vjust=0.5),
panel.grid = element_blank())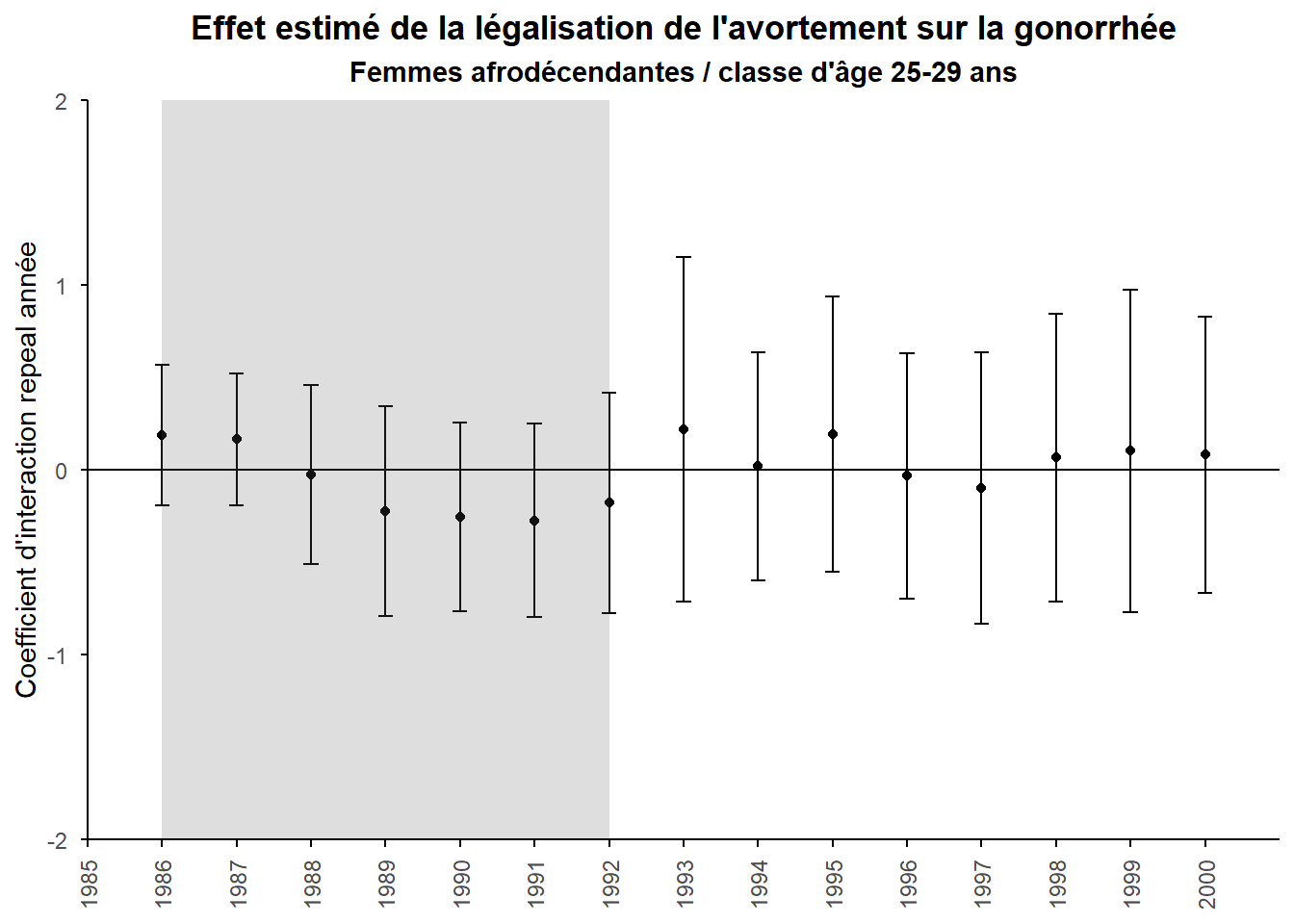
La légalisation de l’avortement en 1970 dans les repeal state n’affecte pas 15 ans après la différence de prévalence de la gonorrhée chez les 25-29 ans par rapport aux autres Etats (ni 16 ans après, ni 17ans …). S’ils avait été affectés sur la même période que les 15-19 ans, on aurait pu se posé la question d’un facteur commun autre que la légalisation de l’avortement qui affecte simultanément les deux cohortes. Cela aurait remis en question notre précédente conclusion.
Cette façon de procéder présente néanmoins le défaut de ne pas fournir d’estimation de l’effet causale sur la cohorte cible (les 15-19 ans) nettoyés de l’effet d’éventuel facteurs communs avec la cohorte des 25-29 ans. La triple différence le permet. C’est ce que propose Cunningham avec un modèle qui non seulement considère les interactions mais aussi des variables de contrôle générales et permettant la prise en compte des tendances marquant la période d’étude. L’équation estimée est la suivante:
\[\begin{aligned} Y_{ast} = \, &\beta_1 \text{Repeal}_s + \beta_2 DT_t + \beta_{3t} \text{Repeal}_s \times DT_t +\\ &\delta_1 DA_a + \delta_2 \text{Repeal}_s \times DA_a + \delta_{3t} DA_a \times DT_t +\\ &\delta_{4t} \text{Repeal}_s \times DA_a \times DT_t +\\ & \xi Control_{st} +\\ & \alpha_{1s}DS_s + \alpha_{2s}DS_s \times DA_a +\\ & \gamma_1 t + \gamma_{2s}DS_s \times t + \gamma_3 DA_a \times t + \gamma_{4s}DS_s \times DA_a \times t +\\ & \epsilon_{ast} \end{aligned}\]
On retrouve les éléments de la spécification de base en simple différences auxquels on a ajouté un certain nombre de choses. DA est une variable binaire prenant la valeur 1 si l’observation est faite sur un membre du groupe test (les 15-19 ans) et la valeur 0 si l’observation est faire sur un membre du groupe de comparaison (les 25-19 ans). DS est série de variables binaires correspondant aux effets fixes Etat. t est une variable marquant le passage du temps de manière continue. Elle est mobilisée pour contrôler de tendances générales, de tendances affectant les Etats, de tendances affectant le groupe test, et des tendances jointes Etat et groupe test.
La partie présentant la dynamique issue de la triple différence pour le groupe des traités (les 15-19 ans) est marqué par \(\delta_{4t}\). Il s’agit d’une série de coefficients marquant les différences comparable à ceux dans un contexte de double différence pour le groupe des traités. Mais présente un effet net d’éventuels facteurs communs avec le groupe placebo, autrement-dit l’effet additionnel sur le groupe test par rapport au groupe placebo.
Procédons à l’estimation. Pour ce faire nous devons procéder à quelques mises en forme de données. Établir une variable marquant le groupe des femmes afrodescendantes (bf) pour la sélection de l’échantillon de travail et un variable marquant l’interaction (yr) entre le fait d’être dans un repeal state et le fait de faire partie du groupe des 15-19 ans (younger, DA dans l’équation). Ceci fait on peut limiter les données au deux cohortes (15-19 ans,test, et 25-29 ans, placebo) pour les femmes afrodescendantes. Extrayons coefficients issues des triples différences (ceux prendant la forme year…:yr1) et présentons les dans un tableau.
reg_DDD <- dat_av %>%
mutate(bf = as_factor(case_when(wht == 0 & male == 0 ~ 1, TRUE ~ 0)),
yr = as_factor(case_when(repeal == 1 & younger == 1 ~ 1, TRUE ~ 0))) %>%
# limitons la base au seul groupe des femmes afrodéscendantes et appartenant
# soit à la classe d'âge des 15-19 ans (les traités potentiels si repeal)
# soit à la classe d'âge de 25-29 ans (le groupes de contrôle placebo si repeal)
filter(bf == 1 & (age == 15 | age == 25)) %>%
# estimons le modèle en triple différences avec contrôle et saturation des
# dynamiques
estimatr::lm_robust(lnr ~ repeal*year +
younger*repeal + younger*year +
yr*year +
fip*t +
acc + ir + pi + alcohol + crack + poverty + income + ur,
data = ., weights = totpop, clusters = fip,
se_type="stata")
# présentons nos résultat mais en ne gardant que les coefficients dynamiques
# associés à la triple intéraction
reg_DDD %>%
tidy() %>%
select(term,estimate,std.error,statistic) %>%
mutate(p.value=2*(1-pnorm(abs(statistic)))) %>%
slice(110:124) %>%
gt() %>%
fmt_number(decimals = 3)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| year1986:yr1 | −0.337 | 0.115 | −2.937 | 0.003 |
| year1987:yr1 | −0.389 | 0.155 | −2.515 | 0.012 |
| year1988:yr1 | −0.382 | 0.143 | −2.673 | 0.008 |
| year1989:yr1 | −0.277 | 0.138 | −2.009 | 0.045 |
| year1990:yr1 | −0.046 | 0.146 | −0.314 | 0.753 |
| year1991:yr1 | 0.079 | 0.148 | 0.535 | 0.593 |
| year1992:yr1 | 0.122 | 0.140 | 0.869 | 0.385 |
| year1993:yr1 | −0.168 | 0.360 | −0.467 | 0.640 |
| year1994:yr1 | 0.239 | 0.124 | 1.935 | 0.053 |
| year1995:yr1 | 0.151 | 0.142 | 1.066 | 0.287 |
| year1996:yr1 | 0.183 | 0.114 | 1.603 | 0.109 |
| year1997:yr1 | 0.357 | 0.114 | 3.130 | 0.002 |
| year1998:yr1 | 0.096 | 0.105 | 0.913 | 0.361 |
| year1999:yr1 | 0.097 | 0.122 | 0.791 | 0.429 |
| year2000:yr1 | 0.084 | 0.133 | 0.629 | 0.530 |
On voit que cette fois l’effet du traitement n’est visible que sur le tout début de la période. Les coefficients de la triple différence ne sont significatifs que de 1985 à 1989. Sur cette courte période, on retrouve schématiquement une parabole inversée avec un pique en 1987. Elle est bien moins nette que celle mise en évidence dans notre double différence initiale. Pour avoir une image plus nette de cela, visualisons les triples différences et leur dynamique.
tibble(year = c(1986:2000),
mean = reg_DDD[[1]][110:124],
sd = reg_DDD[[2]][110:124]) %>%
ggplot(aes(x = year, y = mean)) +
geom_point()+
geom_hline(yintercept = 0) +
geom_errorbar(aes(ymin = mean - sd*1.96, ymax = mean + sd*1.96), width = 0.2,
position = position_dodge(0.05))+
annotate("rect", xmin = 1986, xmax = 1992, ymin = -1, ymax = 1,
alpha = .2)+
labs(title="Effet estimé de la légalisation de l'avortement sur la gonorrhée",
subtitle="Femmes afrodécendantes / classe d'âge 15-19 ans (test) et 25-29 ans (placebo)",
y="Coef. d'int. repeal année 15-19 ans")+
scale_x_continuous(breaks=1985:2000)+
coord_cartesian(expand=FALSE,xlim=c(1985,2001))+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5,face="bold"),
plot.subtitle = element_text(hjust=0.5,face="bold"),
axis.line = element_line(color="black"),
axis.ticks = element_line(color="black"),
axis.title.x = element_blank(),
axis.text.x = element_text(angle=90,vjust=0.5),
panel.grid = element_blank())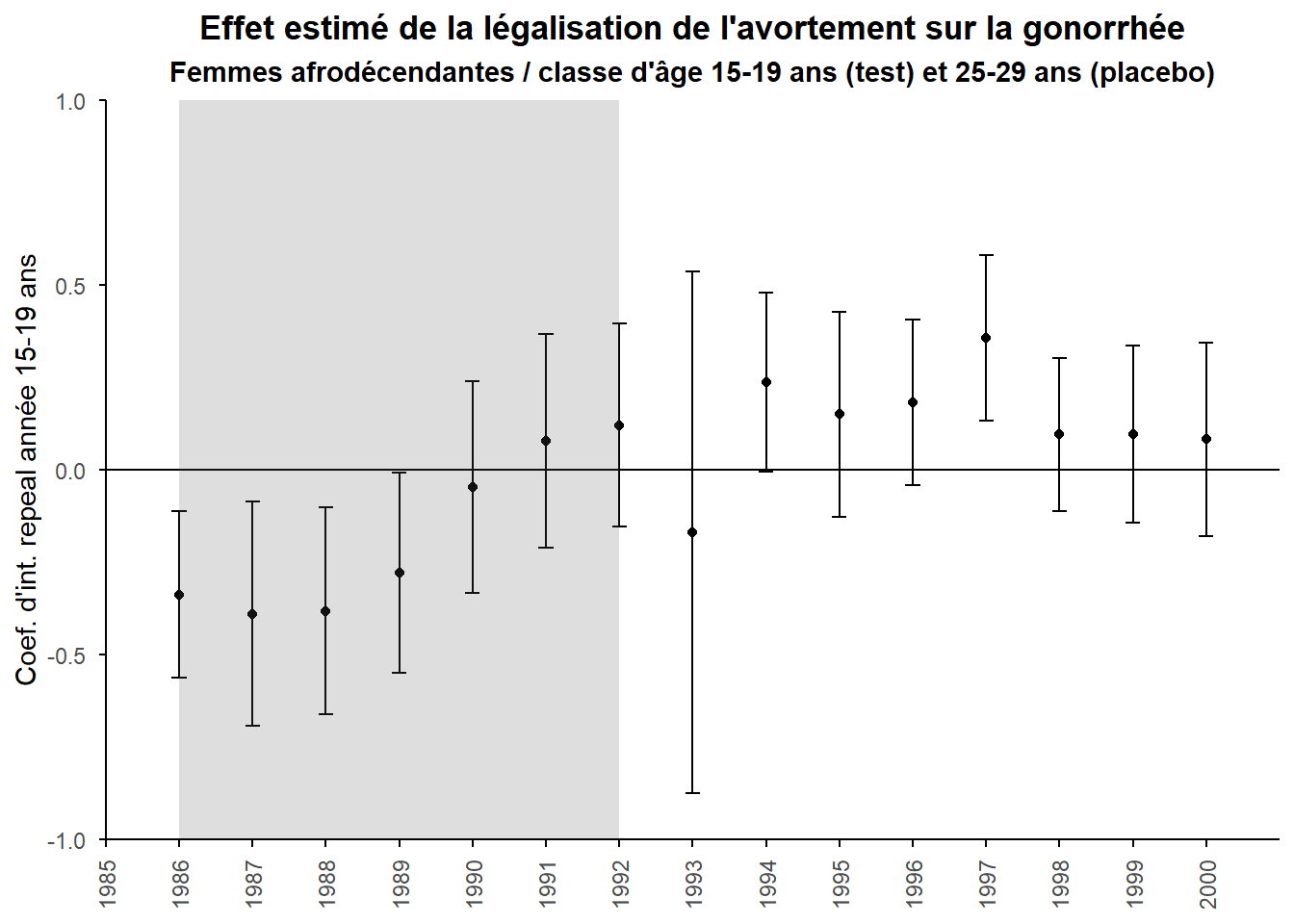
Pour bien comprendre ce que cela représente revenons à l’équation du modèle et mettons en évidence à la fois les doubles différences et notre triple. Commençons par la plus simple à identifier, les doubles différences pour le groupe placebo. Il s’agit simplement, dans la mesure où pour lui DA égal 0, du coefficient \(\beta_{3t}\) qui marque le choc commun (dans un repeal state vs dans un roe state). Passons aux doubles différences pour le groupe test. Pour eux DA égal 1, les effets correspondent pour chaque année à la somme des coefficients \(\beta_{3t}\), \(\delta_{3t}\) et \(\delta_{4t}\) (l’effet du choc commun au test et au placebo - repeal vs roe, l’effet de l’âge - 15-19 vs 25-29- et l’effet croisé -repeal 15-19 vs le reste). Concernant la triple différence, elle est matérialisée par \(\delta_{4t}\). Elle correspond à la dynamique constatée sur le groupe test (les 15-19 ans), \(\beta_{3t}\), \(\delta_{3t}\) et \(\delta_{4t}\), corrigée de deux éléments contre-factuels : la dynamique générale du choc commun (\(\beta_{3t}\)) et la dynamique indépendante du choc du groupe test sur la période (\(\delta_{3t}\)). Cette triple différence marque ainsi clairement l’ATT purgé des facteurs inobservables communs avec le groupe placebo (choc commun géographique, repeal vs roe, et tendance démographique, 15-19 vs 25-29).
Dans sa spécification empirique, Cunningham réduit le nombre de coefficient à estimé en procédant à des regroupements de variables de manière à obtenir un modèle parcimonieux qui lui permet d’obtenir les éléments d’intérêt. L’objectif est de limiter les phénomènes de colinéarité associés mécaniquement à la multiplication des paramètres à estimer (effets fixes, effets fixes croisés…). Ce faisant il simplifie la table de sortie des estimations (en gardant ce qui l’intéresse vraiment). Ainsi, il ne se contente pas de coder la variable younger qui est le DA de l’équation de base mais il code également yr (repeal multiplié par DA/younger). Les coefficients associés à yr pour chaque année nous donne alors directement la dynamique de la triple différence. En additionnant ces coefficients de yr (la dynamique de la triple différence) et ceux de repeal:year (la DiD sur le groupe placebo), on retrouve l’estimation de la DiD “brute” sur le groupe test. Ce calcul permet de décomposer l’effet total et de mesurer précisément l’ampleur du biais commun qui a été purgé grâce à la triple différence.
Observons cela à partir d’un graphe. Reprenons uniquement les effets moyennes pour chaque année pour le groupe placebo (repeal:year), la triple différence (year…:yr1) et le groupe test non corrigé (repeal:year + year…:yr1).
# 1. On récupère la table des coefficients propre
res_tidy <- tidy(reg_DDD)
# 2. On filtre et on extrait les années (ex: 1986)
# Extraction de la DiD Placebo (25-29 ans)
did_placebo <- res_tidy %>%
filter(stringr::str_detect(term, "^repeal:year")) %>%
mutate(year = as.numeric(stringr::str_extract(term, "\\d{4}")),
groupe = "25-29 ans (Placebo DiD)",
effet = estimate) %>%
select(year, groupe, effet)
# Extraction de la Triple Différence (DDD)
ddd_effect <- res_tidy %>%
filter(stringr::str_detect(term, "year\\d{4}:yr")) %>%
mutate(
year = as.numeric(stringr::str_extract(term, "\\d{4}")),
groupe = "Triple Différence (DDD)",
effet = estimate
) %>%
select(year, groupe, effet)
# 3. Calcul de la dynamique Brute pour le groupe traité (15-19 ans)
# On fusionne les deux pour faire la somme (DiD Placebo + DDD)
did_traite <- inner_join(did_placebo, ddd_effect, by = "year",
suffix = c("_plac", "_ddd")) %>%
mutate(groupe = "15-19 ans (Traité DiD)",
effet = effet_plac + effet_ddd) %>%
select(year, groupe, effet)
# 4. Combinaison des 3 trajectoires
graph_data <- bind_rows(did_placebo, did_traite, ddd_effect)
ggplot(graph_data, aes(x = year, y = effet,
color = groupe, group = groupe)) +
geom_line(linewidth = 1) +
geom_point(size = 2) +
geom_hline(yintercept = 0) +
annotate("rect", xmin = 1986, xmax = 1992, ymin = -1, ymax = 1,
alpha = .2)+
labs(title = "Dynamiques d'effet : Double vs Triple Différence",
subtitle = "Comparaison des groupes d'âge",
y = "Coefficient (Impact sur lnr de repeal)",
color = "Indicateur") +
scale_x_continuous(breaks=1985:2000)+
coord_cartesian(expand=FALSE, xlim=c(1985,2001))+
theme_minimal() +
theme(
plot.title = element_text(hjust=0.5,face="bold"),
plot.subtitle = element_text(hjust=0.5,face="bold"),
axis.line = element_line(color="black"),
axis.ticks = element_line(color="black"),
axis.title.x = element_blank(),
axis.text.x = element_text(angle=90,vjust=0.5),
legend.position = "top",
legend.title = element_blank(),
panel.grid = element_blank())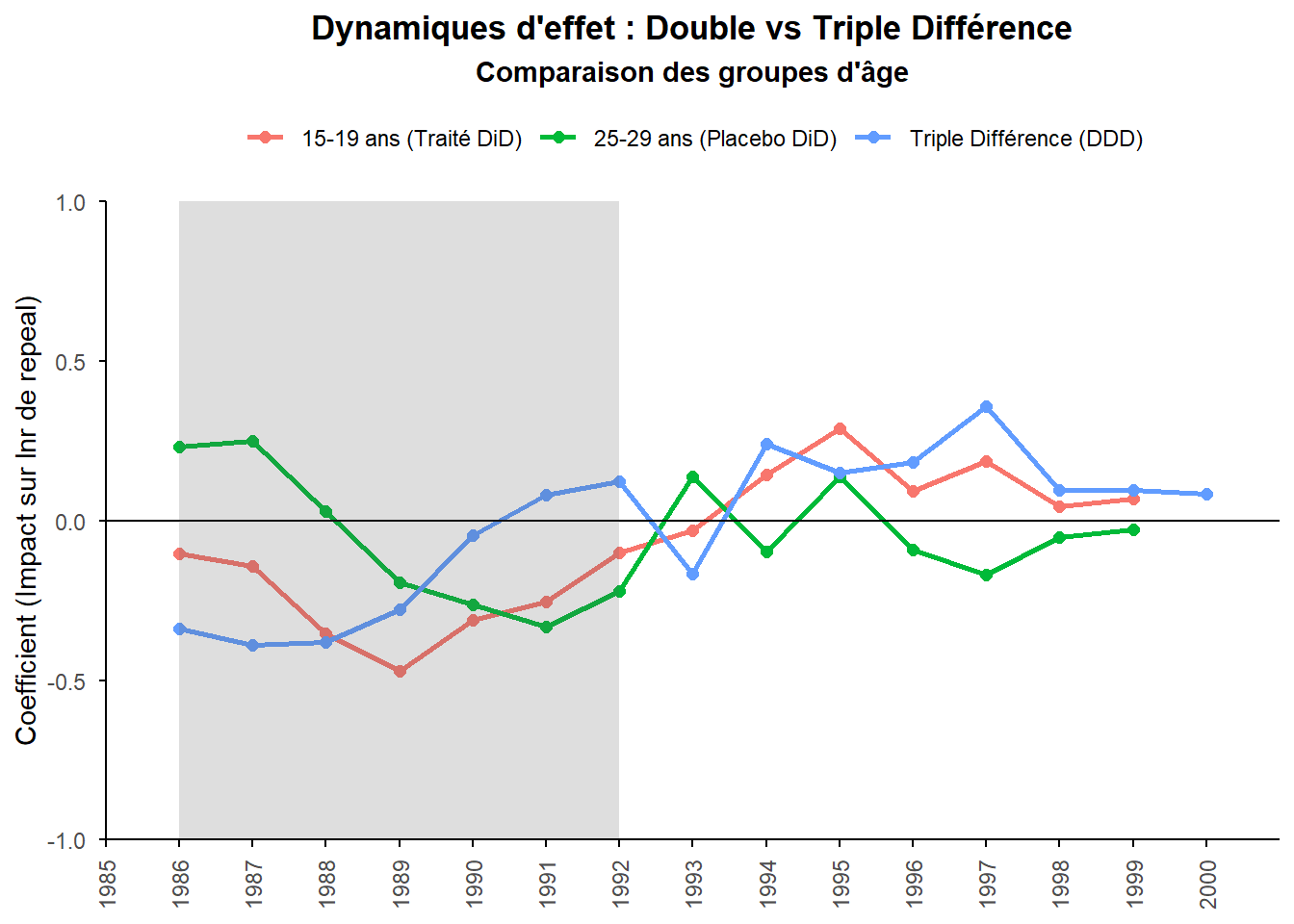
La triple différence apparaît en bleu. On observe précisément comment la ligne verte (le groupe placebo) vient corriger la dynamique de la ligne rouge (le groupe test). Entre 1986 et 1988, le coefficient du groupe placebo est nettement positif, révélant une prévalence de la gonorrhée plus importante dans les repeal states. En soustrayant ce bruit de fond, la triple différence (ligne bleue) accentue l’effet initial chez les 15-19 ans en le rendant encore plus négatif. En 1989, la dynamique s’inverse. le groupe placebo plonge à son tour, ce qui permet d’atténuer le pic négatif de la courbe rouge. Enfin, sur la seconde partie de la période (post-1992), la baisse de l’épidémie chez les 25-29 ans dans les repeal states conduit, par soustraction, à réviser à la hausse la tendance de l’effet net pour notre groupe test.
On peut procéder à la même analyse à partir de graphes juxtaposés mettant en regard chaque DiD individuel (test et placebo) avec la triple différence.
col_traite <- "#F8766D"
col_placebo <- "#00BFC4"
ddd_background <- graph_data %>%
filter(groupe == "Triple Différence (DDD)") %>%
select(-groupe)
ggplot() +
# 1. La DDD en arrière-plan (ligne pointillée grise/bleue dans chaque panneau)
geom_line(data = ddd_background, aes(x = year, y = effet),
linetype = "dashed", color = "royalblue",
alpha = 0.5, size = 0.8) +
# 2. Les données spécifiques à chaque groupe
geom_line(data = filter(graph_data, groupe != "Triple Différence (DDD)"),
aes(x = year, y = effet, color = groupe), size = 1) +
geom_point(data = filter(graph_data, groupe != "Triple Différence (DDD)"),
aes(x = year, y = effet, color = groupe), size = 2) +
geom_hline(yintercept = 0, linetype = "solid",
color = "black", alpha = 0.3) +
annotate("rect", xmin = 1986, xmax = 1992, ymin = -0.5, ymax = 0.5,
alpha = .2) +
labs(title=paste0(
"Décomposition de la Triple Différence :<br>",
"<span style='color:", col_traite, "'> **Groupe Traité (15-19 ans)**</span> vs ",
"<span style='color:", col_placebo, "'>**Groupe Placebo (25-29 ans)**</span>"
),
subtitle = "La ligne en pointillés représente l'effet net (DDD) après purge du biais",
y = "Coefficient")+
scale_x_continuous(breaks=1985:2000)+
# 3. Facette sur les deux sous-groupes test et placebo
facet_wrap(~groupe, ncol = 2) +
theme_minimal() +
theme(
plot.title = element_markdown(hjust=0.5,face="bold",size = 14,
lineheight = 1.3,
margin = margin(t = 10, b = 5)),
plot.subtitle = element_text(hjust=0.5,face="italic",
size = 11,
margin = margin(b = 15)),
axis.line = element_line(color="black"),
axis.ticks = element_line(color="black"),
axis.title.x = element_blank(),
axis.text.x = element_text(angle=90,vjust=0.5),
legend.position = "none",
panel.grid = element_blank(),
strip.text = element_blank())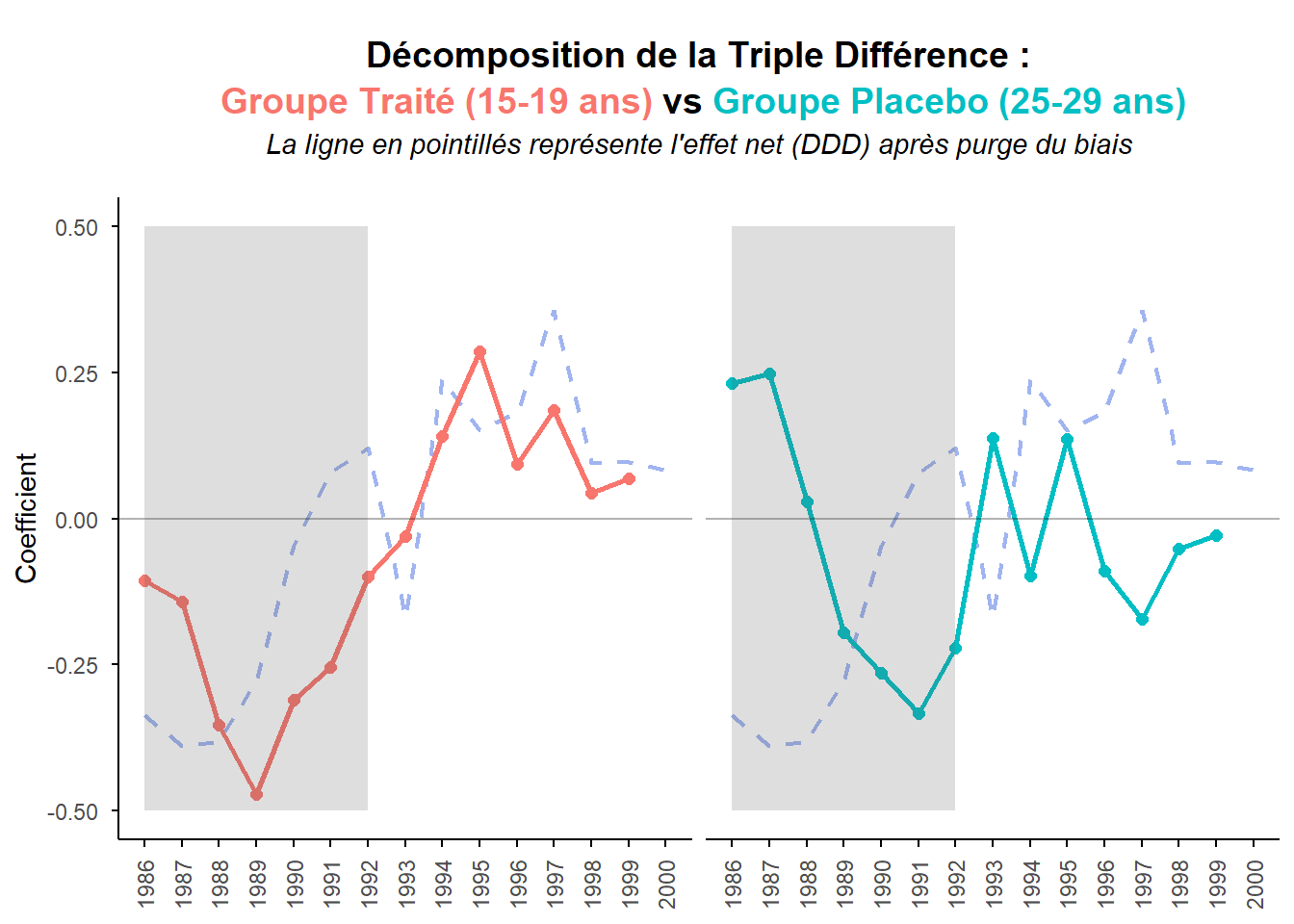
Cette présentation comme la précédente permet d’approfondir ce que permet la triple différence avec le groupe placebo. Néanmoins, elles présentent un défaut. Elles ignorent les questions de significativité statistiques. Pour y remédier, incluons dans notre représentation les intervalles à 95% correspondant à nos effets pour les doubles différences et la triple différences. Afin d’alléger la figure, répartissons les courbes sur trois graphes.
Pour ce faire, il faut récupérer les estimations des standard erreurs des coefficients associés à nos double et triple différence. Pour le groupe placebo et la triple différence cela ne pose pas de difficultés particulière. Pour le groupe test, nous n’avons pas de mesure directe. Comme pour les coefficients, il faut les reconstituer à partir des éléments obtenus pour le groupe placebo et la triple différence. Néanmoins, on ne peut pas ici se contenter de les additionner. Il faut tenir compte de la manière dont les erreurs d’estimation covarient. Pour ce faire, nous utiliserons la méthode delta via la fonction deltaMethod() proposée par la package car.
res_tidy <- tidy(reg_DDD)
did_placebo <- res_tidy %>%
filter(stringr::str_detect(term, "^repeal:year")) %>%
mutate(year = as.numeric(stringr::str_extract(term, "\\d{4}")),
groupe = "25-29 ans (Placebo DiD)",
effet = estimate,
sd=std.error) %>%
select(year, groupe, effet, sd)
ddd_effect <- res_tidy %>%
filter(stringr::str_detect(term, "year\\d{4}:yr")) %>%
mutate(year = as.numeric(stringr::str_extract(term, "\\d{4}")),
groupe = "Triple Différence (DDD)",
effet = estimate,
sd=std.error) %>%
select(year, groupe, effet, sd)
did_traite <- inner_join(did_placebo, ddd_effect, by = "year",
suffix = c("_plac", "_ddd")) %>%
mutate(groupe = "15-19 ans (Traité DiD)",
effet = effet_plac + effet_ddd,
sd=sd_plac+sd_ddd) %>%
select(year, groupe, effet,sd)
graph_data <- bind_rows(did_placebo, did_traite, ddd_effect)
# Correction delta
# 1. On récupère les coefficients et la matrice
all_coefs <- coef(reg_DDD)
v_mat <- vcov(reg_DDD)
# 2. On élimine les coefficients "NA" pour aligner les dimensions
keep <- !is.na(all_coefs)
coefs_clean <- all_coefs[keep]
v_mat_clean <- v_mat[keep, keep]
# 3. Nouveau vecteur pour les SE
se_delta <- numeric(15)
years <- 1986:1999
for(i in seq_along(years)) {
yr <- years[i]
# Construction de l'expression avec vos noms de variables réels
# On additionne le choc commun (yr1) et l'interaction triple (yr)
expr <- paste0("`repeal:year", yr, "` + `year", yr, ":yr1` ")
# Utilisation de deltaMethod avec les objets nettoyés
res_delta <- car::deltaMethod(coefs_clean, g = expr, vcov. = v_mat_clean)
se_delta[i] <- res_delta$SE}
# 4. Mise à jour de graph_data
# On crée un vecteur 'sd_complet' initialisé avec les valeurs actuelles
sd_complet <- graph_data$sd
# On identifie les positions des lignes du groupe test
idx_traite <- which(graph_data$groupe == "15-19 ans (Traité DiD)")
# On remplace uniquement ces 15 positions par les valeurs Delta
sd_complet[idx_traite] <- se_delta
# On met à jour graph_data
graph_data <- graph_data %>%
mutate(sd = sd_complet)
ggplot(
data=graph_data,
aes(x = year, y = effet, color=groupe, groupe=groupe)) +
geom_point()+
geom_hline(yintercept = 0) +
geom_errorbar(aes(ymin = effet - sd*1.96, ymax = effet + sd*1.96), width = 0.2,
position = position_dodge(0.05))+
annotate("rect", xmin = 1986, xmax = 1992, ymin = -1, ymax = 1,
alpha = .2)+
labs(title="Effet estimé de la légalisation de l'avortement sur la gonorrhée",
subtitle="Femmes afrodécendantes / classe d'âge 15-19 ans vs 25-29",
y="Coefficient d'interaction repeal année")+
scale_x_continuous(breaks=1985:2000)+
coord_cartesian(expand=FALSE,xlim=c(1985,2001))+
facet_wrap(~groupe, nrow = 2) +
theme_minimal()+
theme(plot.title = element_text(hjust=0.5,face="bold"),
plot.subtitle = element_text(hjust=0.5,face="bold"),
axis.line = element_line(color="black"),
axis.ticks = element_line(color="black"),
axis.title.x = element_blank(),
axis.text.x = element_text(angle=90,vjust=0.5),
legend.position = "none",
panel.grid = element_blank())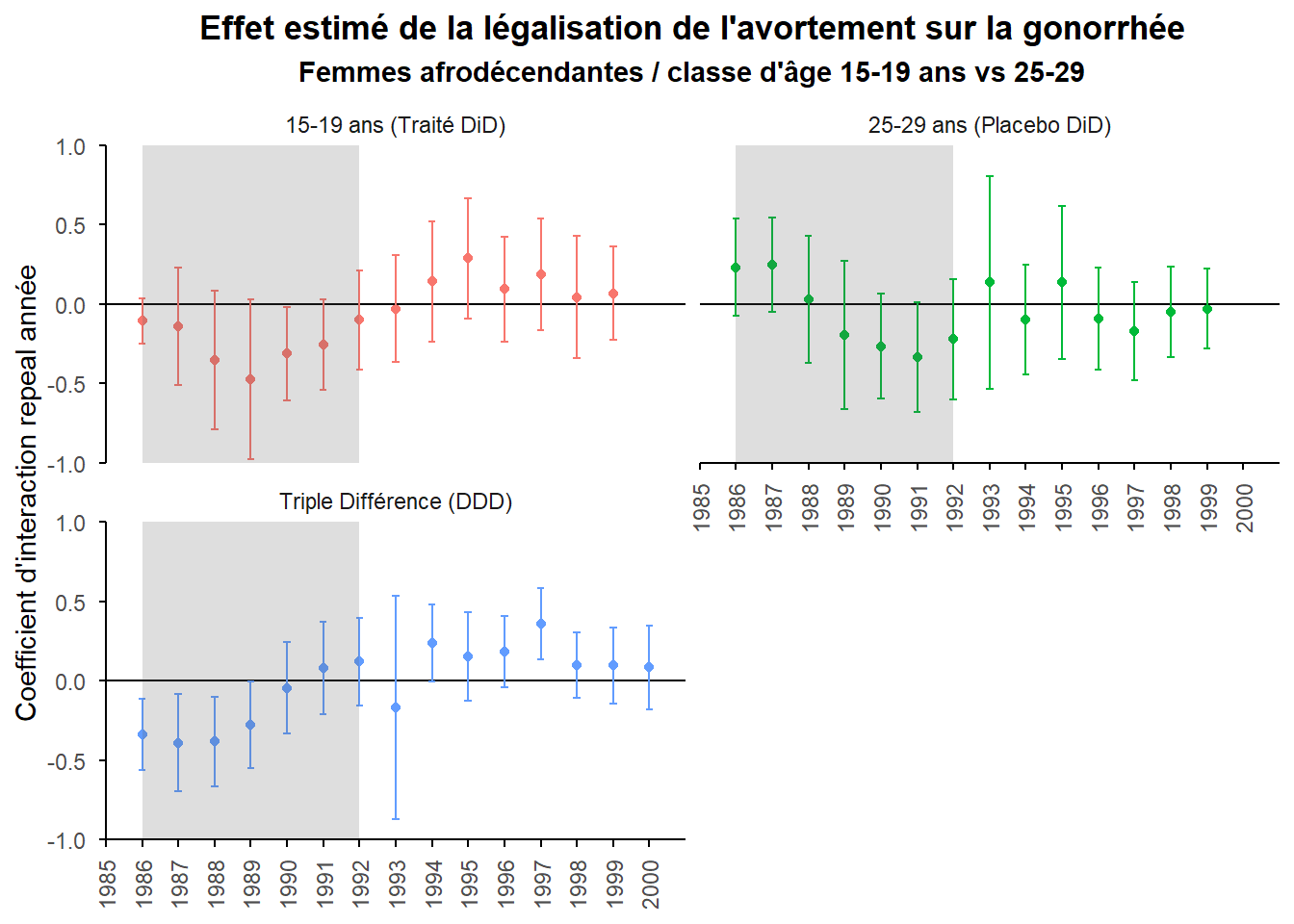
On peut noter que la double différence pour le groupe test très similaire quant à la forme (parabole inversée) par rapport à la double différence initiale (pratiqué uniquement sur les 15-19), néanmoins la plus part de ses coefficients apparaissent non significatifs (même sur la période teste, en gris sur le graphe). Cela est associé notamment au fait que le groupe de comparaison est plus large (les 15-19 et les 25-29).
Pour résumer à ce stade, les résultats vont dans le sens d’un effet sélectif de la légalisation de l’avortement proche de celui mis en avant pas Levitt. A la nuance prés que ce dernier semble perdre de la puissance avant la date attendue (1990 à la place de 1992). C’est la dessus que Cunningham s’arrête dans son papier (@cornwell2013a).
Dans mixtape, il propose d’aller un peu plus loin. Comme la cohorte concernée celle naie dans le début des années 1970 a été traité in utero, nous ne devrions non seulement constater une parabole inversée quand ils ont entre 15-19 ans entre 1986 et 1992, mais aussi quand ils ont entre 20 et 24 ans entre 1991-1997. A mesure que la cohorte avance en âge, on devrait voir l’effet de sélection avancer. A l’origine Cunningham pensait que les comportements à risque diminuerait à l’age et donc qu’il ne serait plus pertinant d’étendre l’analyse aux jeunes adultes. Dans le chapitre, il revient sur cet a priori et réplique l’analyse en double différence sur ce groupe d’âge.
reg_20 <- dat_av %>%
filter(race == 2 & sex == 2 & age == 20) %>%
estimatr::lm_robust(lnr ~ repeal*year + fip + acc + ir + pi + alcohol+ crack + poverty+ income+ ur,
data = ., weights = totpop, clusters = fip,
se_type = "stata")
tibble(year = c(1986:2000),
mean = reg_20[[1]][76:90],
sd = reg_20[[2]][76:90]) %>%
ggplot(aes(x = year, y = mean)) +
geom_point()+
geom_hline(yintercept = 0) +
geom_errorbar(aes(ymin = mean - sd*1.96, ymax = mean + sd*1.96), width = 0.2,
position = position_dodge(0.05))+
annotate("rect", xmin = 1991, xmax = 1997, ymin = -1, ymax = 1,
alpha = .2)+
labs(title="Effet estimé de la légalisation de l'avortement sur la gonorrhée",
subtitle="Femmes afrodécendantes / classe d'âge 20-24 ans",
y="Coef. d'int. repeal année")+
scale_x_continuous(breaks=1985:2000)+
coord_cartesian(expand=FALSE,xlim=c(1985,2001))+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5,face="bold"),
plot.subtitle = element_text(hjust=0.5,face="bold"),
axis.line = element_line(color="black"),
axis.ticks = element_line(color="black"),
axis.title.x = element_blank(),
axis.text.x = element_text(angle=90,vjust=0.5),
panel.grid = element_blank())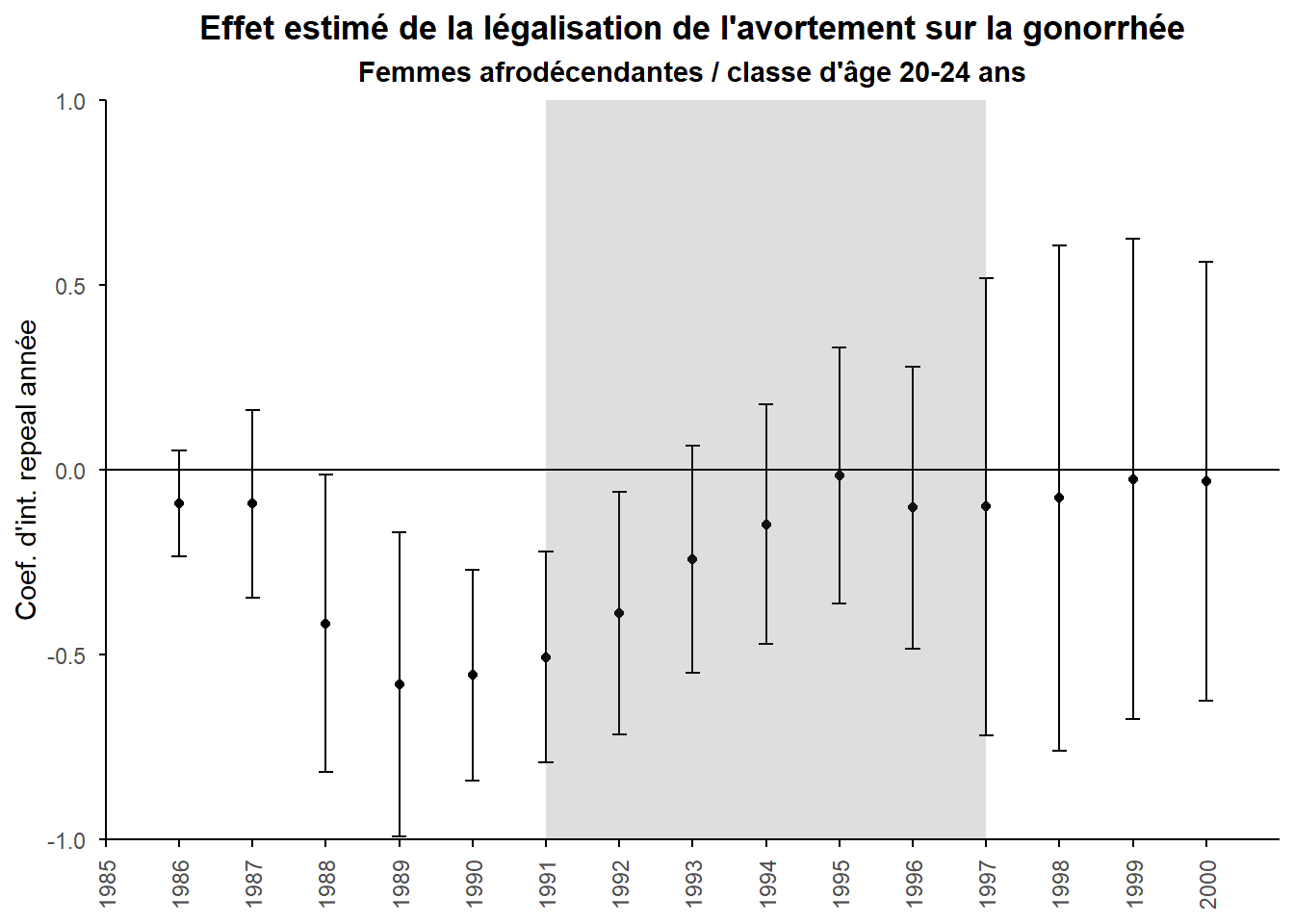
Examinons le graphe des coefficients DiD. Plusieurs choses sont troublantes. Tout d’abord, il y a une parabole inversée sur le période 1986-1992 et cela ne concerne pas le groupe des traités. Cela suggère que notre analyse précédente a mi le doigt sur autre chose que la légalisation de l’avortement. C’est une justification de l’utilisation d’une triple différence, comme il est claire que quelque chose se passe entre les repeal states et les Roe state sur cette période que l’on ne parvient pas à contrôler avec nos effets fixes et autres variables de contrôles (on a un défaut de parallel trend). Ensuite, on peut noter qu’il n’y a pas de parabole inversée sur la période test (1991-1997). Cette dernière apparaît plus comme une période ce convergences entre les repeal et les roe state.
Établissons l’analyse en triple différence avec le groupe placebo 25-29 ans (même s’il est moins probable que la condition de non contamination croisée tienne ici). Ne représentons que les coefficients associés à la dynamique de cette triple différence. L’effet sur les 20-24 ans purgé de celui sur les 25-29 ans.
dat_ddd20 <- dat_av %>%
filter(race == 2 & sex == 2 & (age == 20 | age == 25)) %>%
mutate(younger2 = case_when(age == 20 ~ 1, TRUE ~ 0),
yr2 = case_when(repeal == 1 & younger2 == 1 ~ 1, TRUE ~ 0))
reg_DDD_20 <- estimatr::lm_robust(
lnr ~ repeal * as.factor(year) +
younger2 * repeal +
younger2 * as.factor(year) +
yr2 * as.factor(year) +
fip * t +
acc + ir + pi + alcohol + crack +
poverty + income + ur,
data = dat_ddd20,
weights = totpop,
clusters = fip,
se_type = "stata")
df_graph <- tidy(reg_DDD_20) %>%
# On cherche les lignes qui contiennent l'interaction yr2 et l'année
filter(str_detect(term, "as.factor\\(year\\)")) %>%
filter(str_detect(term, "yr2")) %>%
# On extrait l'année du nom de la variable pour le graphique
mutate(year = as.numeric(str_extract(term, "\\d{4}")))
ggplot(df_graph, aes(x = year, y = estimate)) +
geom_point() +
geom_hline(yintercept = 0) +
geom_errorbar(aes(ymin = estimate - std.error * 1.96,
ymax = estimate + std.error * 1.96),
width = 0.2) +
annotate("rect", xmin = 1991, xmax = 1997, ymin = -1, ymax = 0.7, alpha = .2) +
labs(title = "Effet estimé de la légalisation de l'avortement sur la gonorrhée",
subtitle = "Femmes afrodécendantes / classe d'âge 20-24 ans et 25-29 ans",
y = "Coef. d'int. repeal année 20-24") +
scale_x_continuous(breaks = 1985:2000) +
coord_cartesian(expand = FALSE, xlim = c(1985, 2001), ylim = c(-1, 0.7)) +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5, face = "bold"),
plot.subtitle = element_text(hjust = 0.5, face = "bold"),
axis.line = element_line(color = "black"),
axis.ticks = element_line(color = "black"),
axis.title.x = element_blank(),
axis.text.x = element_text(angle = 90, vjust = 0.5),
panel.grid = element_blank())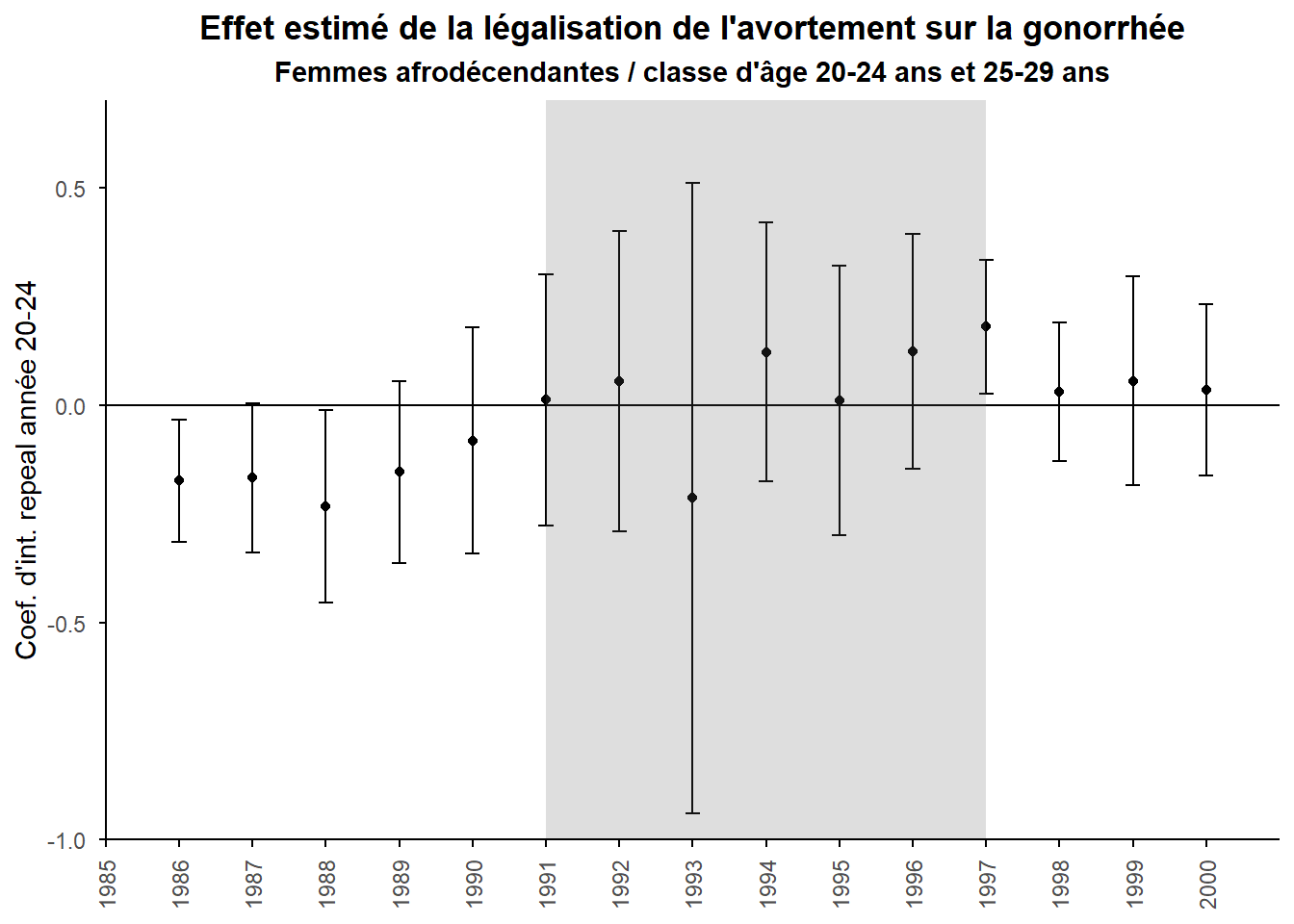
On a plus rien de significatif et surtout pas de parabole inversée sur la période teste (ni sur la période que précède). Cela peut nous amener à deux conclusions possibles. Soit l’effet de sélection associé à la légalisation de l’avortement doit être rejeté, soit il existe mais uniquement sur la période 1985-1990. Le fait de ne pas l’observé pour la cohorte sur 1991-1997 peu être dû au fait que les comportement à risque des jeunes adultes sont différents de ceux des adolescents et que passer cette période l’effet de sélection disparaît (c’est ce que postulait Cunningham à l’origine). Par ailleurs, le placebo choisi dans l’analyse ne satisfait pas la condition de non contaminations croisées (SUTVA, Stable Unit Traetment Value Assumption) et donc permet pas d’éliminer les facteurs que l’on ne parvient pas à neutraliser à partir des variables de contrôle et des effets fixes.
Qu’est ce que l’on peut en conclure ? Pour ce qui est de l’étude de Cunningham, je pencherai en faveur du résultat initial (même si je n’aime pas particulièrement implication de l’étude Levitt). Pour ce qui est de la méthodologie, l’ensemble montre que le choix des hypothèses a testé est d’autant plus riche qu’il s’appuie sur une analyse théorique préalable solide de ce que peut donner les données dont on dispose et cela que ce soit pour le résultat principal comme pour les tests de robustesse/placebo qui le mettent en question. Ainsi, par exemple, la triple différence doit être pensée comme un design expérimental autonome même si elle ne vient que compléter une analyse principale réalisée au préalable.