Après une pause relativement longue, il est temps de reprendre la série GT (graph type) et à cette occasion de considérer une nouvelle catégorie de graphe. Il s’agira, dans un groupe de post, de traiter des représentations des séries temporelles toujours en nous basant sur les vidéos proposées par Josh Schwabish dans sa playlist One Chart at a time. Ces différents posts auront ainsi comme point commun de présenter différentes manière d’illustrer l’évolution des valeurs d’une ou de plusieurs variables au travers le temps.
Commençons avec la représentation plus simple et la plus connue, la courbe ou en anglais le line chart. Elle présente l’avantage important de ne pas devoir être expliqué lorsque vous l’utilisez. Comme avec le bar chart tous le monde a déjà été confronté à ce type de graphe. Basiquement, elle articule deux mesures continues, le temps et la variable d’intérêt, en présentant la première en abscisse et la seconde en ordonnée. Chacun des points déterminés par leur intersection est relié au précédent pour former une ligne continue. La forme de cette ligne indique alors le sens de variation de la variable d’intérêt en fonction de l’écoulement du temps. Le focus de ce type de graphe est sur cette évolution et donc il n’est pas nécessaire de faire partir les axes de la valeur 0 (elle n’a généralement que peut de sens). De même, l’échelle utilisée pour représenter la variable d’intérêt ne doit forcément être linéaire. Une échelle logarithmique peut être mobilisé dans certain cas pour rendre l’ensemble plus pertinent.
Considérons à titre d’illustration trois cas: une série simple (le taux de change EURO/DOLLAR), une série simple enrichie d’annotation (la fréquence du prénom Neil) et la réunion de plusieurs séries avec les courbes en escalier (nombre de titres NBA part équipe dans le temps).
En préalable chargeons une série de package de base qui seront utiles pour l’ensemble.
library(tidyverse)
library(scales)
library(ggtext)le taux de change EURO/DOLLAR
Chargeons de données. Pour ce faire, nous allons utiliser un package spécifique au traitement des données financières quantmod qui propose une série de fonctions de type wrapper API permettant d’obtenir des informations via différents serveurs.
library(quantmod)Utilisons celle dédiée aux taux de change getFX(). Précisons que l’on veut obtenir le cours Euro/Dollar et qu’on le veut du premier janvier 2022 à aujourd’hui par exemple.
getFX("EUR/USD",from="2022-01-01")## Warning in doTryCatch(return(expr), name, parentenv, handler): Oanda only
## provides historical data for the past 180 days. Symbol: EUR/USD## [1] "EUR/USD"Notez que le fournisseur de donnée Oanda ne fourni qu’un historique de 180 jours et donc nous n’obtenons pas l’ensemble des données demandées. Ici, ce n’est pas vraiment un problème, nous nous en contenterons.
Notez également que les données sont fournis dans un format inhabituel le format xts qui est l’un des format facilitant le traitement des données de séries temporelles.
str(EURUSD)## An 'xts' object on 2022-08-07/2023-02-02 containing:
## Data: num [1:180, 1] 1.02 1.02 1.02 1.03 1.03 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr "EUR.USD"
## Indexed by objects of class: [Date] TZ: UTC
## xts Attributes:
## List of 2
## $ src : chr "oanda"
## $ updated: POSIXct[1:1], format: "2023-02-03 15:12:58"Le package quantmod propose une fonction dédiée pour établir le graphe à partir d’un objet xts. Appliquons-la au cours EURO/Dollar (combien d’Euros pour un Dollar).
plot(EURUSD)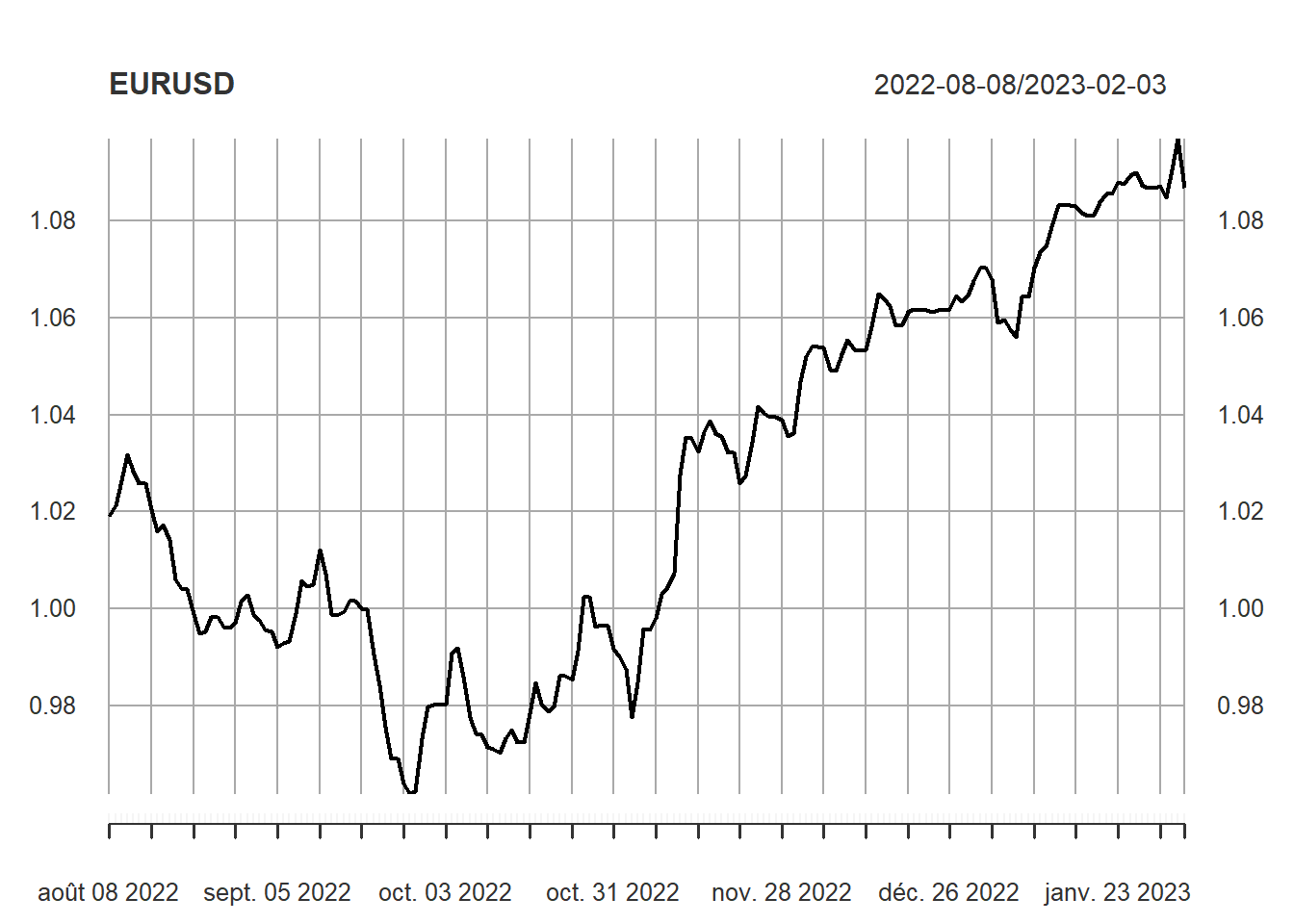
Le graphe obtenu est pas mal. Mais, vous vous en doutez je trouve qu’il manque d’éléments personnalisés. En plus, il est réalisé à partir du système R base auquel je préfère l’univers GGPLOT2.
Passons donc l’ensemble sous ggplot. Pour cela, il y a deux stratégies possibles transformer l’objet xts en une data frame classique (passer les dates qui sont en nom de ligne dans une variable avec la fonction index()), ou utiliser la fonction autoplot.zoo() pour initier le graphe.
Nous retiendrons ici la seconde solution.
autoplot.zoo(EURUSD)
Bon, le résultat de base n’est pas très engageant. Commençons donc la personnalisation en ajoutant des points pour marquer les valeurs, en limitant la plage de valeur visible et en adoptant un thème plus sobre.
autoplot.zoo(EURUSD)+
geom_point()+
coord_cartesian(expand = FALSE)+
theme_minimal()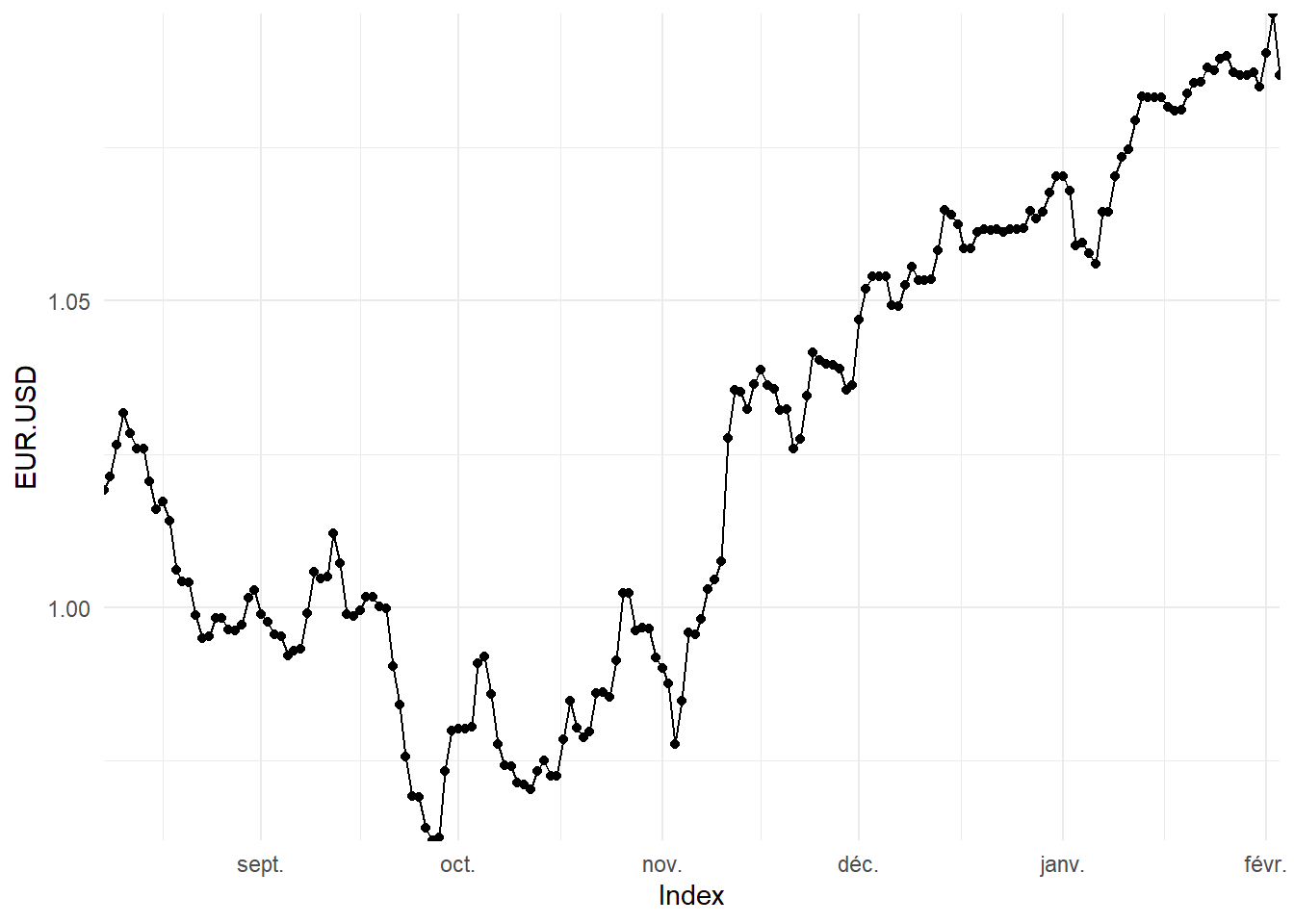
Ajoutons des titres, habillons les axes et simplifions l’ensemble.
autoplot.zoo(EURUSD)+
geom_point()+
labs(title="Cours de l'Euro face au Dollar",
subtitle = "(nb. d'Euro pour un Dollar)")+
scale_y_continuous(labels=label_dollar(
prefix='',suffix=' Euros'))+
coord_cartesian(expand=FALSE,ylim=c(0.96,1.1))+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(hjust=0.5,face='italic'),
axis.line = element_line(color='dark gray'),
axis.title = element_blank())
Réduisons la taille des points et passons-les en rouge.
autoplot.zoo(EURUSD)+
geom_point(size=0.8,color='red')+
labs(title="Cours de l'Euro face au Dollar",
subtitle = "(nb. d'Euro pour un Dollar)")+
scale_y_continuous(labels=label_dollar(
prefix='',suffix=' Euros'))+
coord_cartesian(expand=FALSE,ylim=c(0.96,1.1))+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(hjust=0.5,face='italic'),
axis.line = element_line(color='dark gray'),
axis.title = element_blank())
Le résultat est intéressant. Nous pourrions nous arrêter là. Mais, avant de passer à la seconde illustration, revenant sur les données au format xts. Leur structure permet de mobiliser des fonctions redéfinisant le découpage temporelle de la série. Testons-en une. Passons à une série hebdomadaire avec la fonction to.weekly().
red_EURUSD<-to.weekly(EURUSD,name="mon")
head(red_EURUSD)## mon.Open mon.High mon.Low mon.Close
## 2022-08-07 1.018053 1.018053 1.018053 1.018053
## 2022-08-14 1.019062 1.031758 1.019062 1.025914
## 2022-08-21 1.020464 1.020464 1.004107 1.004107
## 2022-08-28 0.998768 0.998768 0.994914 0.996164
## 2022-09-04 0.997102 1.002861 0.995213 0.995213
## 2022-09-11 0.992168 1.005845 0.992168 1.005046Traçons la courbe du taux de change EURO/UDS en fréquence hebdomadaire ne choisissant pour chaque semaine le dernier cours disponible (le cours de clôture).
autoplot.zoo(red_EURUSD$mon.Close)+
geom_point(size=0.8,color='red')+
labs(title="Cours de l'Euro face au Dollar",
subtitle = "(nb. d'Euro pour un Dollar)")+
scale_y_continuous(labels=label_dollar(prefix='',suffix=' Euros'))+
coord_cartesian(expand=FALSE,ylim=c(0.96,1.1))+
theme_minimal()+
theme(plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(hjust=0.5,face='italic'),
axis.line = element_line(color='dark gray'),
axis.title = element_blank())
La fréquence du prénom masculin Neil
Ce nouveau graphe est une réplication de celui réalisé par Neil Richards pour le SWD challenge (Story With Data). Son point de départ est la base de des prénoms attribués aux Etats Unis que l’on peut charger ici. L’ensemble prend la forme d’un fichier zip nommé names.zip. Il contient une série de fichiers correspondant à des année et indiquant la fréquence de différents prénoms pour différent sexes. Chargez l’archive et décompressez-la dans votre environnement de travail.
Reste alors à la traité pour obtenir une data frame unique facilement manipulable pour créer notre graphe. Pour cela, nous utiliserons un fonction permettant de créer une boucle pour charger chaque fichier et les abouter. Il s’agit de la fonction map_df() du package purrr qui fait partie du tidyverse. Elle prend pour premier argument le vecteur définissant l’itération et comme suivant la fonction itérée ainsi que ses arguments. Profitons-en pour procéder à quelques mises en forme.
nom_f<-paste0("yob",1880:2021)
nom<-paste0('names/',nom_f,'.txt')
dat<-map_df(nom,read_csv,col_names = FALSE,id="annee") %>%
rename(prenom=X1,sex=X2,effectif=X3) %>%
mutate(annee= as.numeric(gsub('\\D+','', annee)))## Rows: 2052781 Columns: 5
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ";"
## chr (2): X3, X4
## dbl (3): X1, X2, X5
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Voyons le résultat.
head(dat)## # A tibble: 6 × 4
## annee prenom sexe effectif
## <dbl> <chr> <chr> <dbl>
## 1 1880 Mary F 7065
## 2 1880 Anna F 2604
## 3 1880 Emma F 2003
## 4 1880 Elizabeth F 1939
## 5 1880 Minnie F 1746
## 6 1880 Margaret F 1578Nous ne voulons que le prénom Neil attribué à des garçons après l’année 1911. Filtrons la base en conséquence.
dat_neil<-dat %>% filter(prenom=='Neil'&sexe=='M'&annee>1911)
head(dat_neil)## # A tibble: 6 × 4
## annee prenom sexe effectif
## <dbl> <chr> <chr> <dbl>
## 1 1912 Neil M 151
## 2 1913 Neil M 184
## 3 1914 Neil M 232
## 4 1915 Neil M 289
## 5 1916 Neil M 375
## 6 1917 Neil M 356Maintenant que les données sont prêtes, nous pouvons commencer à travailler notre graphe.
ggplot(data=dat_neil,aes(x = annee, y=effectif))+
geom_line()+
theme_minimal()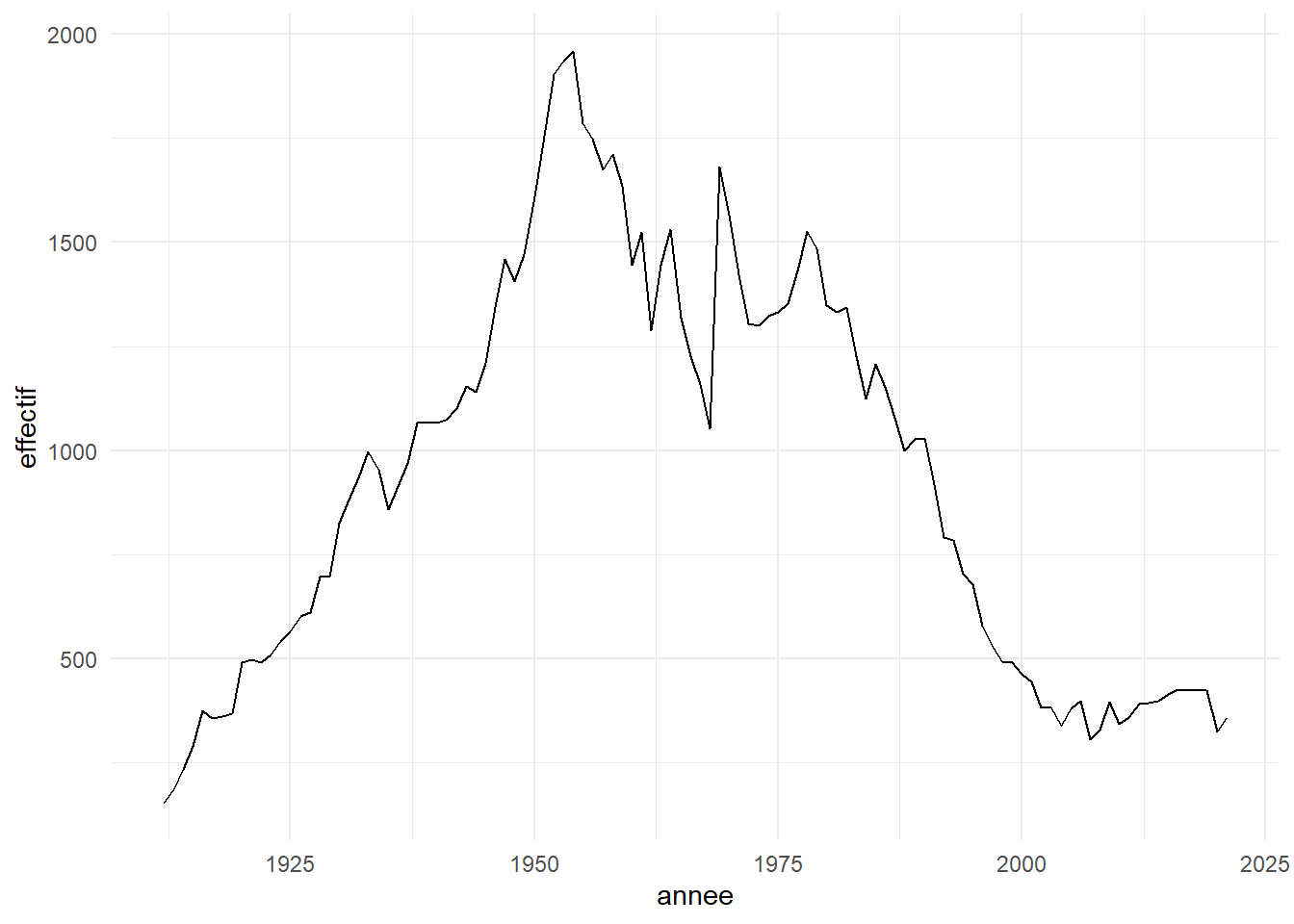
Ajoutons des titres et mettons en forme les axes (supprimons l’axe des ordonnées et habillons celui des abscisses).
ggplot(data=dat_neil,aes(x = annee, y=effectif))+
geom_line()+
labs(title="Rise and Fall of the name Neil in the USA",
subtitle = "Births 1912-2021",
caption="Source: data.gov ")+
theme_minimal()+
theme(plot.title = element_markdown(),
axis.line.x = element_line(color='dark gray'),
axis.title = element_blank(),
axis.text.y = element_blank(),
panel.grid = element_blank())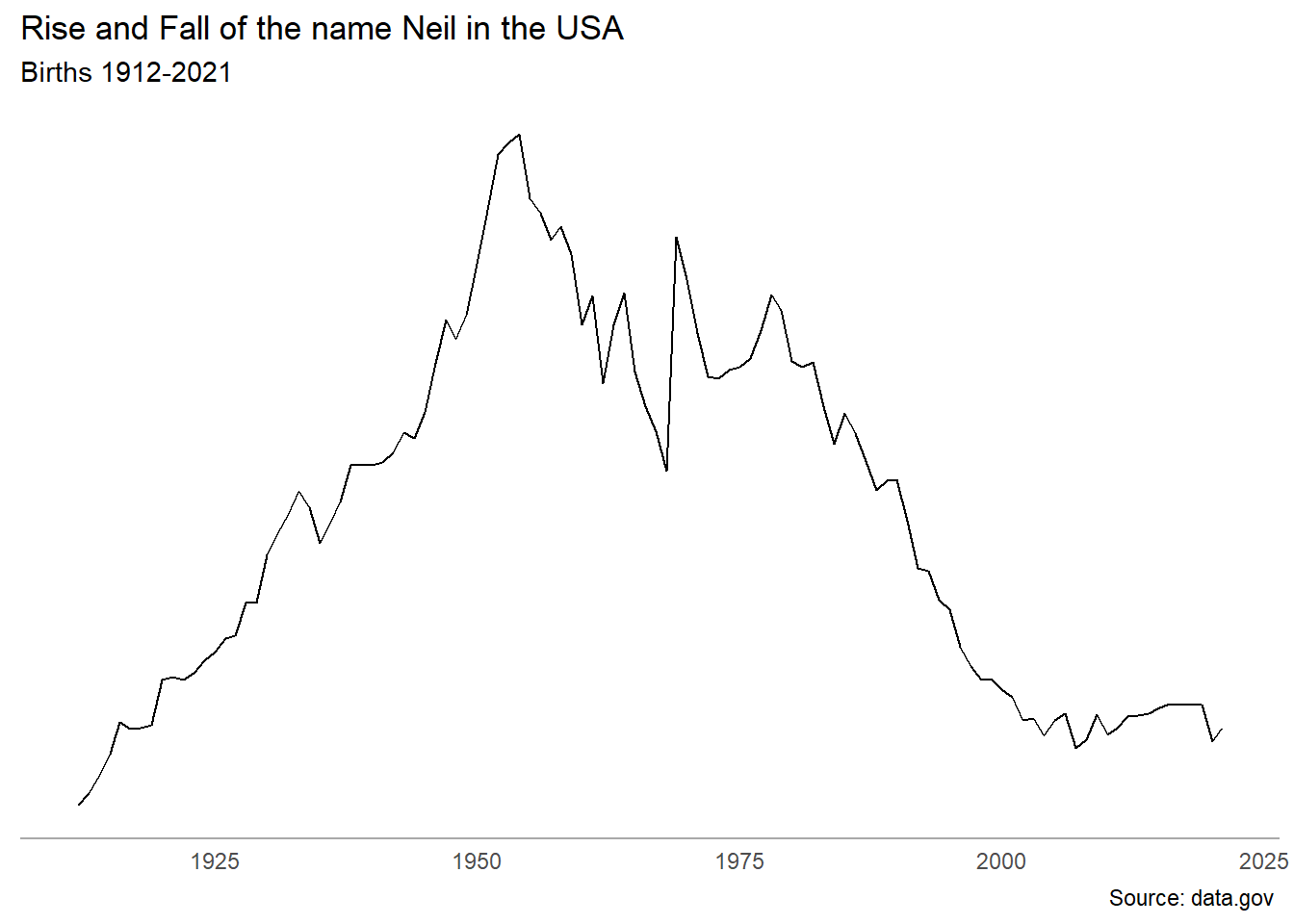
Ajoutons de la couleur et recadrons la courbe.
ggplot(data=dat_neil,aes(x = annee, y=effectif))+
geom_line(color="#ECB84F",linewidth=0.8)+
labs(title="Rise and Fall of the name <b style='color:#ECB84F;'>Neil</b> in the USA",
subtitle = "Births 1912-2021",
caption="Source: data.gov ")+
scale_x_continuous(breaks = seq(1915,2015,10))+
coord_cartesian(expand=FALSE,ylim=c(100,2050))+
theme_minimal()+
theme(plot.title = element_markdown(),
axis.line.x = element_line(color='dark gray'),
axis.title = element_blank(),
axis.text.y = element_blank(),
panel.grid = element_blank())
On a une bonne base ajoutons les annotations. Pour ce faire, fixons les dimensions du graph.
ggplot(data=dat_neil,aes(x = annee, y=effectif))+
geom_line(color="#ECB84F",linewidth=0.8)+
# annotation 1
geom_textbox(aes(x=1915,y=151,
label="Popularity of <b style='color:#ECB84F;'>Neil</b> before WW1 is low <br>
Neils born is 1912: **151**"),
nudge_x =18, nudge_y = 40,width =unit(6, "cm"),
size=3,box.colour='white')+
geom_segment(aes(x=1912,y=151,xend=1917,yend=185),linewidth=0.1,color='dark gray')+
geom_segment(aes(x=1917,y=146,xend=1917,yend=225),linewidth=0.1,color="#ECB84F")+
##
labs(title="Rise and Fall of the name <b style='color:#ECB84F;'>Neil</b> in the USA",
subtitle = "Births 1912-2021",
caption="Source: data.gov ")+
scale_x_continuous(breaks = seq(1915,2015,10))+
coord_cartesian(expand=FALSE,ylim=c(100,2050))+
theme_minimal()+
theme(plot.title = element_markdown(),
axis.line.x = element_line(color='dark gray'),
axis.title = element_blank(),
axis.text.y = element_blank(),
panel.grid = element_blank())
Intégrons l’ensemble des étiquettes.
ggplot(data=dat_neil,aes(x = annee, y=effectif))+
geom_line(color="#ECB84F",linewidth=0.8)+
# annotation 1
geom_textbox(aes(x=1915,y=151,
label="Popularity of <b style='color:#ECB84F;'>Neil</b> before WW1 is low <br>
Neils born is 1912: **151**"),
nudge_x =18, nudge_y = 40,width =unit(6, "cm"),
size=3,box.colour='white')+
geom_segment(aes(x=1912,y=151,xend=1917,yend=185),linewidth=0.1,color='dark gray')+
geom_segment(aes(x=1917,y=146,xend=1917,yend=225),linewidth=0.1,color="#ECB84F")+
# annotation 2
geom_textbox(aes(x=1915,y=1926,
label="<b style='color:#ECB84F;'>Neil Johnson</b> leads NBA scoring <br>
for three successive seassons 1952-55 <br>
Neils born is 1954: **1956**"),
nudge_x =18, nudge_y = 40,width =unit(6, "cm"),halign=1,
size=3,box.colour='white')+
geom_segment(aes(x=1954,y=1956,xend=1949,yend=1960),linewidth=0.1,color='dark gray')+
geom_segment(aes(x=1949,y=1915,xend=1949,yend=2010),linewidth=0.1,color="#ECB84F")+
# annotation 3
geom_textbox(aes(x=1968,y=1689,
label="<b style='color:#ECB84F;'>Neil Amstrong</b> lands of on the moon <br>
Neils born is 1969: **1683**"),
nudge_x =20, nudge_y = 40,width =unit(6, "cm"),
size=3,box.colour='white')+
geom_segment(aes(x=1969,y=1683,xend=1972,yend=1720),linewidth=0.1,color='dark gray')+
geom_segment(aes(x=1972,y=1680,xend=1972,yend=1760),linewidth=0.1,color="#ECB84F")+
# annotation 4
geom_textbox(aes(x=1978,y=1530,
label="Peack popularity of musicians 1972-1979 <br>
<b style='color:#ECB84F;'>Neil Young, Neil Sedaka, Neil Diamond</b> lands of on the moon <br>
Neils born is 1978: **1530**"),
nudge_x =20, nudge_y = 30,width =unit(6, "cm"),
size=3,box.colour='white')+
geom_segment(aes(x=1978,y=1530,xend=1981,yend=1560),linewidth=0.1,color='dark gray')+
geom_segment(aes(x=1981,y=1480,xend=1981,yend=1620),linewidth=0.1,color="#ECB84F")+
# annotation 5
geom_textbox(aes(x=1950,y=400,
label="Modern Neils like <b style='color:#ECB84F;'>Neil DeGrasse Tyson</b> <br>
ensure steady level of popularity post 2005 <br>
Neils born is 2009: **396**"),
nudge_x =20, nudge_y = 30,width =unit(9, "cm"),
size=3,box.colour='white',halign=1)+
geom_segment(aes(x=2009,y=396,xend=1995,yend=399),linewidth=0.1,color='dark gray')+
geom_segment(aes(x=1995,y=360,xend=1995,yend=490),linewidth=0.1,color="#ECB84F")+
##
labs(title="Rise and Fall of the name <b style='color:#ECB84F;'>Neil</b> in the USA",
subtitle = "Births 1912-2021",
caption="Source: data.gov ")+
scale_x_continuous(breaks = seq(1915,2015,10))+
coord_cartesian(expand=FALSE,ylim=c(100,2050))+
theme_minimal()+
theme(plot.title = element_markdown(),
axis.line.x = element_line(color='dark gray'),
axis.title = element_blank(),
axis.text.y = element_blank(),
panel.grid = element_blank())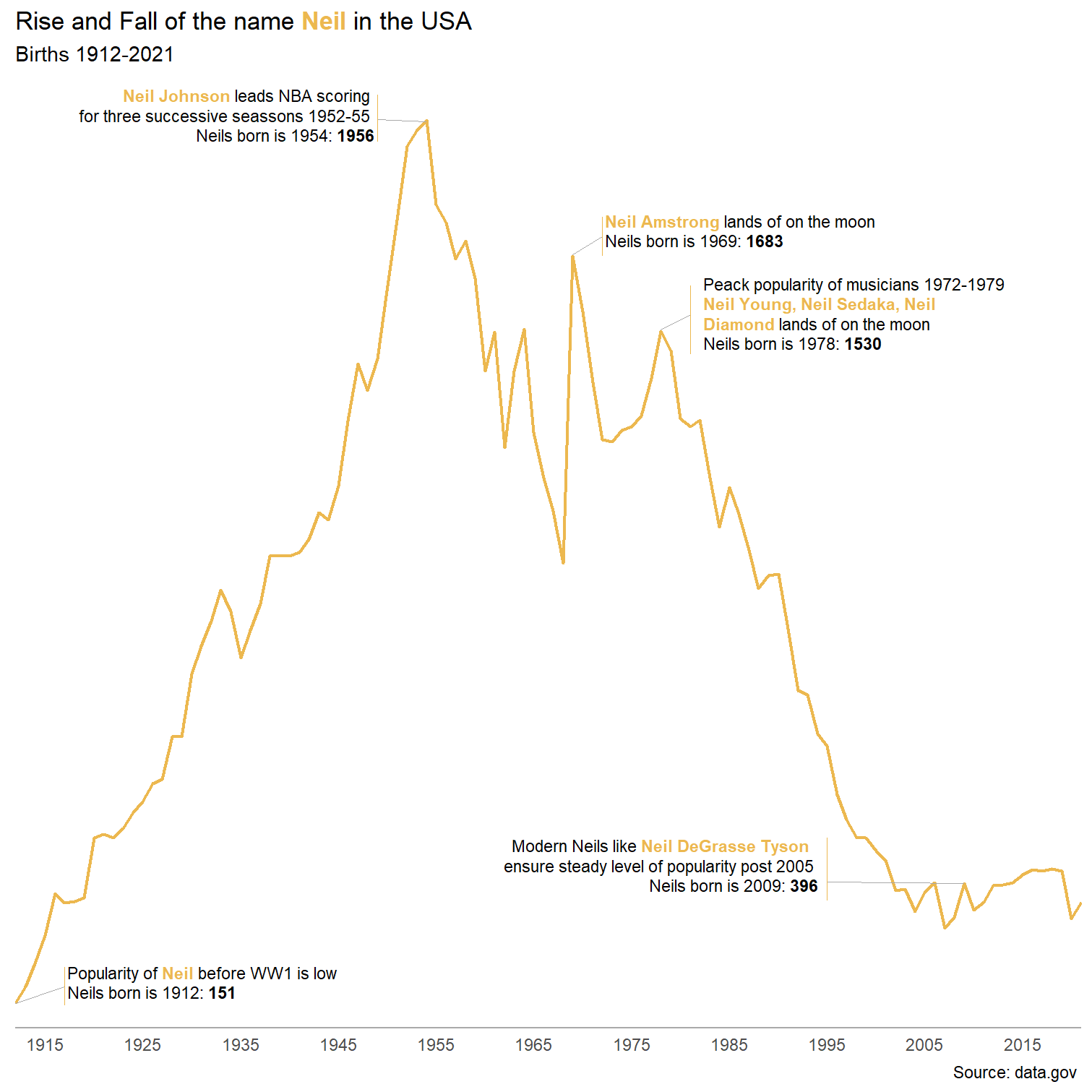
Le placement des étiquettes n’est ce qui est le plus pratique avec R mais on y arrive en tâtonnant pas mal.
Le nombre titres NBA
Passons à notre dernier graphe. Il s’agit d’établir pour chaque équipe ayant gagné au moins un titre un courbe en escalier marquant l’évolution du nombre de titres qu’elle a remporté depuis la création de la ligue. Pour ce faire, nous allons chercher les données sur Wikipedia. Utilisons pour ce faire le package rvest qui permet de scraper la page et le package janitor qui aide à la mise en forme des données.
library(rvest)
library(janitor)Chargeons les données brutes.
content_nba<-read_html('https://fr.wikipedia.org/wiki/Liste_des_champions_NBA')
tables_nba<- content_nba %>% html_table(fill = TRUE)
tab_brute_<-tables_nba[[3]]%>% clean_names() %>%
mutate(team_f=equipe,id=1:33) %>%
filter(victoires>0)
tab_brute_## # A tibble: 20 × 7
## equipe victo…¹ defai…² total…³ annee…⁴ team_f id
## <chr> <chr> <chr> <chr> <chr> <chr> <int>
## 1 Lakers de Los Angeles(inclus le… 17 15 32 1949, … Laker… 1
## 2 Celtics de Boston 17 4 21 1957, … Celti… 2
## 3 Warriors de Golden State(inclus… 7 5 12 1947, … Warri… 3
## 4 Bulls de Chicago 6 0 6 1991, … Bulls… 4
## 5 Spurs de San Antonio 5 1 6 1999, … Spurs… 5
## 6 76ers de Philadelphie(inclus le… 3 6 9 1955, … 76ers… 6
## 7 Pistons de Détroit(inclus le bi… 3 4 7 1989, … Pisto… 7
## 8 Heat de Miami 3 3 6 2006, … Heat … 8
## 9 Knicks de New York 2 6 8 1970, … Knick… 9
## 10 Rockets de Houston 2 2 4 1994, … Rocke… 10
## 11 Bucks de Milwaukee 2 1 3 1971, … Bucks… 11
## 12 Cavaliers de Cleveland 1 4 5 2016 Caval… 12
## 13 Hawks d'Atlanta(inclus le bilan… 1 3 4 1958 Hawks… 13
## 14 Wizards de Washington(inclus le… 1 3 4 1978 Wizar… 14
## 15 Thunder d'Oklahoma City(inclus … 1 3 4 1979 Thund… 15
## 16 Trail Blazers de Portland 1 2 3 1977 Trail… 16
## 17 Mavericks de Dallas 1 1 2 2011 Maver… 17
## 18 Raptors de Toronto 1 0 1 2019 Rapto… 18
## 19 Bullets de Baltimore (disparue … 1 0 1 1948 Bulle… 19
## 20 Kings de Sacramento(inclus le b… 1 0 1 1951 Kings… 20
## # … with abbreviated variable names ¹victoires, ²defaites, ³total_de_finales,
## # ⁴annees_victorieusesNous avons limité la base aux seules (20) équipes qui ont gagnées au moins un titre. Les années de victoires sont indiquées dans une seule variable ce qui n’est pas très pratique. Isolons les informations par année la variable et établissons les cumuls correspondant.
annee<-1947:2022
for(i in 1:20){
assign(paste0("equ_",i),
cumsum(annee%in%as.numeric(str_split_1(tab_brute_$annees_victorieuses[i],","))))}
dtf<-data.frame(annee,mget(paste0("equ_",1:20)))
colnames(dtf)<-c("annee","LAK","CELT","WAR","BULL","SPURS","t76ers","PISTONS","HEAT","KNICKS",
"ROCKETS","BUCKS","CAV","HAWKS","WIZ","THUND","TRAILBL","MAV","RAPT",
"BULLET_BALT","KINGS")
head(dtf)## annee LAK CELT WAR BULL SPURS t76ers PISTONS HEAT KNICKS ROCKETS BUCKS CAV
## 1 1947 0 0 1 0 0 0 0 0 0 0 0 0
## 2 1948 0 0 1 0 0 0 0 0 0 0 0 0
## 3 1949 1 0 1 0 0 0 0 0 0 0 0 0
## 4 1950 2 0 1 0 0 0 0 0 0 0 0 0
## 5 1951 2 0 1 0 0 0 0 0 0 0 0 0
## 6 1952 3 0 1 0 0 0 0 0 0 0 0 0
## HAWKS WIZ THUND TRAILBL MAV RAPT BULLET_BALT KINGS
## 1 0 0 0 0 0 0 0 0
## 2 0 0 0 0 0 0 1 0
## 3 0 0 0 0 0 0 1 0
## 4 0 0 0 0 0 0 1 0
## 5 0 0 0 0 0 0 1 1
## 6 0 0 0 0 0 0 1 1On voit bien que les Warriors ont gagné leur premier titre en 1947 puis attendu longtemps pour le second alors que les Lakers ont enchainé les titres à partir de 1949. La configuration de la base n’est pas idéale. Passons les données du format large au format long en utilisant la fonction pivot_longer().
dd_<-pivot_longer(dtf,cols=c(LAK,CELT,WAR,BULL,SPURS,t76ers,PISTONS,HEAT,KNICKS,
ROCKETS,BUCKS,CAV,HAWKS,WIZ,THUND,TRAILBL,MAV,RAPT,
BULLET_BALT,KINGS),
names_to="equipe",
values_to = 'victoires')
head(dd_)## # A tibble: 6 × 3
## annee equipe victoires
## <int> <chr> <int>
## 1 1947 LAK 0
## 2 1947 CELT 0
## 3 1947 WAR 1
## 4 1947 BULL 0
## 5 1947 SPURS 0
## 6 1947 t76ers 0Maintenant que les données ont le bon format attaquons-nous à l’élaboration de notre graphe. Commençons par un version comprenant un minimum de mise en forme. Le géome centrale ici sera le geom_step().
gr1<-ggplot(data=dd_,aes(x=annee,y=victoires,color=equipe))+
geom_step()+
scale_x_continuous(breaks = seq(1947,2022,5))+
scale_y_continuous(breaks = 1:18)+
coord_cartesian(expand = FALSE)+
theme_minimal()+
theme(
axis.title = element_blank(),
panel.grid = element_blank())
gr1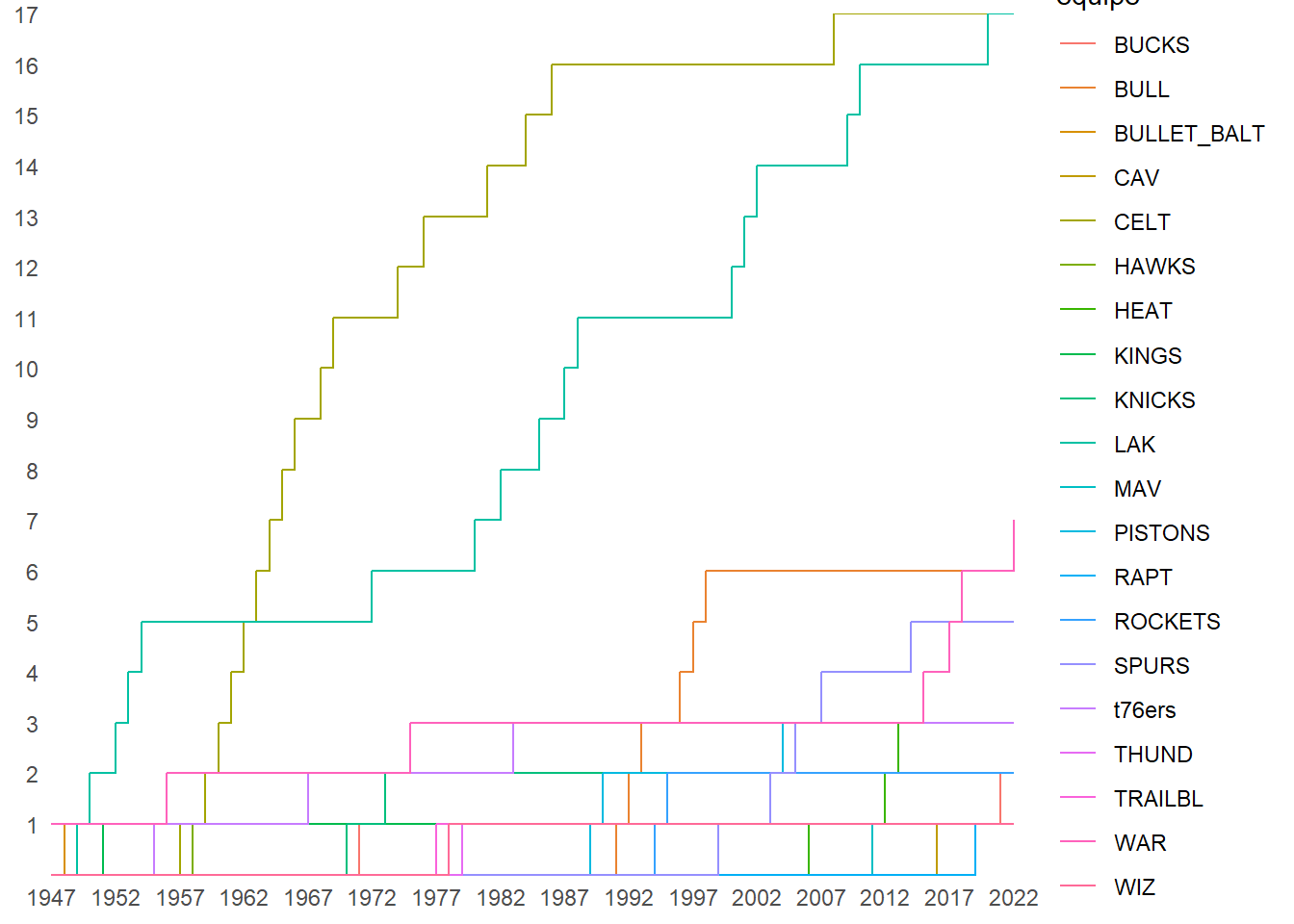
L’ensemble est fort chargé. Supprimons la légende et limitons les couleurs aux équipes cumulant au final le plus de titres (Lakers, Celtics et Warriors). Changeons la couleur de fond pour mettre l’ensemble en valeur.
gr2<-gr1+
geom_step(data=filter(dd_,equipe=="LAK"),linewidth=0.8)+
geom_step(data=filter(dd_,equipe=="CELT"),linewidth=0.8)+
geom_step(data=filter(dd_,equipe=="WAR"),linewidth=0.8)+
scale_color_manual(values = c(rep("grey",4),"#30AF1E",rep("grey",4),"purple",rep("grey",8),
"blue",'grey'))+
coord_cartesian(expand = FALSE,xlim=c(1946,2023),ylim=c(0,20))+
theme(
axis.line.x = element_line(color='black'),
axis.title = element_blank(),
panel.grid = element_blank(),
panel.background=element_rect(fill="#FBFAF5",color="#FBFAF5"),
plot.background=element_rect(fill="#FBFAF5",color="#FBFAF5"),
legend.position = "none")## Coordinate system already present. Adding new coordinate system, which will
## replace the existing one.gr2
Ajoutons un titre, un sous-titre et un caption. Puis, marquons quelques points remarquables.
gr3<-gr2+
geom_point(aes(x=1962,y=5),color='#30AF1E')+
geom_point(aes(x=2020,y=17),color='#9370DB')+
geom_point(aes(x=2022,y=7),color='#0000FF')+
labs(title="Les <b style='color:#9370DB;'>Lakers</b> et les <b style='color:#30AF1E;'>Celtics</b> à égalité avec 17 titres chacun sont largement devant",
subtitle = 'les deux équipes combinent à elles seules 45% des titres',
caption='Source: Wikipedia')+
theme(
plot.title = element_markdown(face='bold'),
plot.subtitle = element_text(face='italic'),
plot.caption = element_text(face='italic',hjust=1),
axis.title = element_blank(),
panel.grid = element_blank(),
axis.line.x = element_line(color='black'),
panel.background=element_rect(fill="#FBFAF5",color="#FBFAF5"),
plot.background=element_rect(fill="#FBFAF5",color="#FBFAF5"),
legend.position = "none")
gr3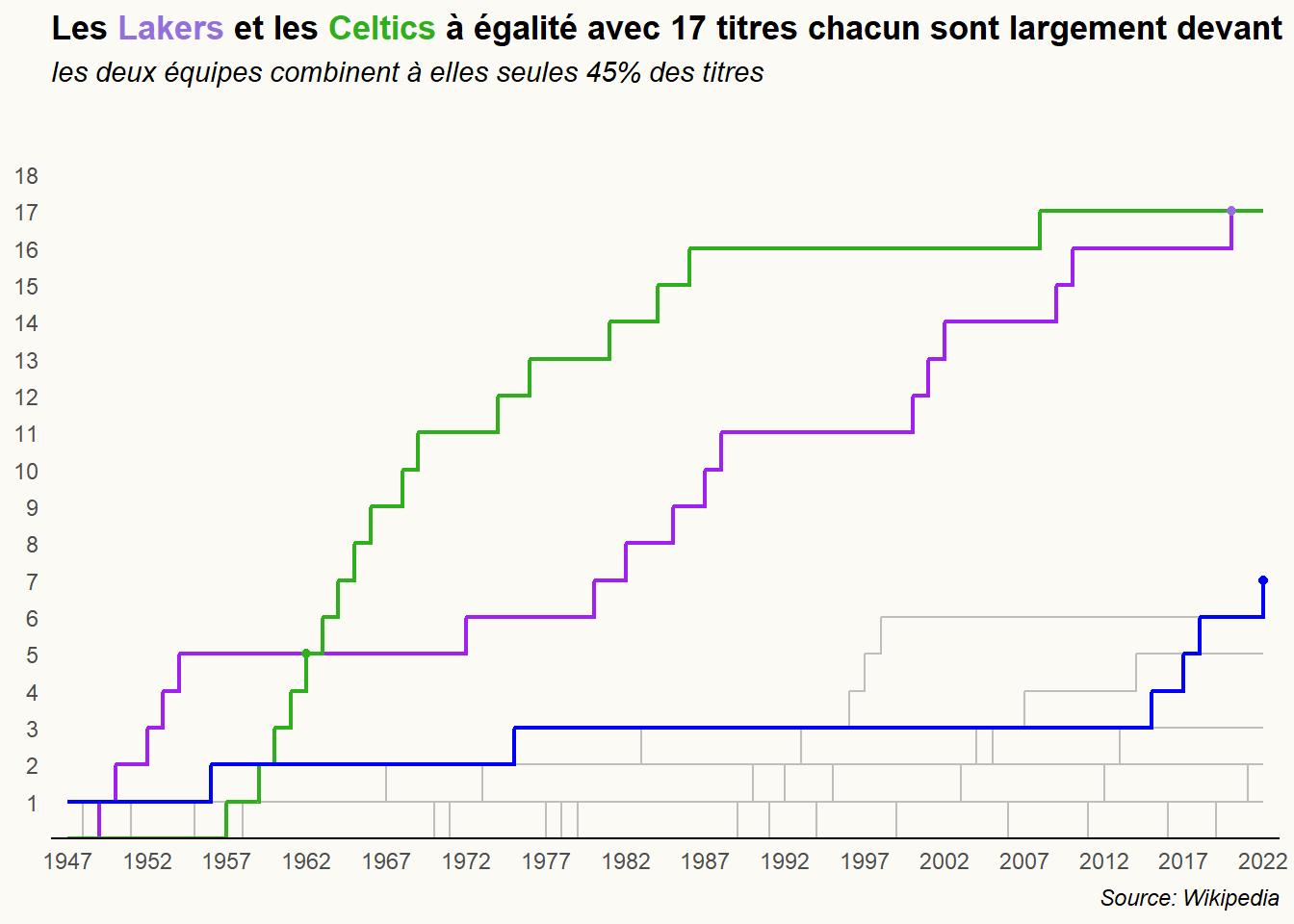
Pour finir, ajoutons des étiquettes expliquant nos points remarquables et agrandissons la taille du graphe.
gr4<-gr3+
# annotation 1
geom_textbox(aes(x=1962,y=5,
label="Les <b style='color:#30AF1E;'>Celtics</b> égalise <br>les <b style='color:#9370DB;'>Lakers</b> en nombre <br> de titres"),
nudge_x =-5, nudge_y = 1,size=2, fill='#FBFAF5',color='black',
box.colour='#FBFAF5',box.padding = unit(c(0, 0, 0, 0), "pt"),
width = unit(1, "inch"),)+
# annotation 2
geom_textbox(aes(x=2020,y=17,
label="Les <b style='color:#9370DB;'>Lakers</b> égalise <br> les <b style='color:#30AF1E;'>Celtics</b> en nombre de titres"),
nudge_x =-2, nudge_y = 1,size=2, fill='#FBFAF5',color='black',
box.colour='#FBFAF5',box.padding = unit(c(0, 0, 0, 0), "pt"))+
# annotation 3
geom_textbox(aes(x=2022,y=7,
label="Les <b style='color:#0000FF;'>Warriors</b> obtiennent leur 7ème titres"),nudge_x =-6,nudge_y = 0.5,size=2, fill='#FBFAF5',color='black',
box.colour='#FBFAF5',box.padding = unit(c(0, 0, 0, 0), "pt"))+
theme(
plot.title = element_markdown(face='bold'),
plot.subtitle = element_text(face='italic'),
plot.caption = element_text(face='italic',hjust=1),
axis.title = element_blank(),
panel.grid = element_blank(),
axis.line.x = element_line(color='black'),
panel.background=element_rect(fill="#FBFAF5",color="#FBFAF5"),
plot.background=element_rect(fill="#FBFAF5",color="#FBFAF5"),
legend.position = "none")
gr4