Au printemps prochain, je donnerai, dans mon université, un cours introductif sur la visualisation de données. L’idée est de conférer aux étudiants un savoir technique, afin qu’ils soient capables de réaliser des graphes rigoureux et esthétiques,et de cultiver chez eux un regard critique sur les représentations qui leur sont présentées dans la presse, sur internet ou ailleurs. Pour ce faire, j’ai choisi d’utiliser R comme outil principal, plus spécifiquement le package GGPLOT2 (et ses compléments) qui permet d’obtenir très rapidement, au travers d’un codes intuitifs, des graphes qui ont de l’allure.
Jusqu’à récemment, je n’utilisais pas beaucoup cette solution. Je préférais réaliser les figures de mes papiers et de mes cours avec les fonctionnalités de base de R. Je partais du postulat que tout ce qui peut être fait avec GGPLOT2, peut être fait, avec un effort supplémentaire de programmation, avec R base. Bref, je ne me facilitais pas la vie mais ça convenait à mes faibles ambitions esthétiques. Puis, j’ai découvert la communauté des spécialistes de la Datavisualisation et là les choses ont changé. Les graphes réalisées par de gens comme Cédric Scherer m’ont convaincu qu’un peu simplification pouvait permettre d’aller beaucoup plus loin dans les représentations et au final mieux communiquer les résultats de mes travaux.
Le package a été crée par Hadley Wickham en 2005 en s’inspirant de la grammaire des graphiques développée par le statisticien Leland Wilkinson dans son livre de 1993 (Grammar of graphics).Schématiquement, il propose de coder le graphe que vous souhaitez réaliser comme une phrase. Vous commencez par indiquer le sujet, les données que vous cherchez à représenter. Puis, vous indiquez ce que vous voulez faire avec, autrement-dit le verbe ou les verbes (une nuage de points, un histogramme, des courbes…). Et vous finalisez les choses par des compléments qui ajoutent à l’information principale (légende, titres ou autres).
Pour illustrer son utilisation, dans ce premier billet associé à la préparation du cours, j’ai choisi de travailler à partir de données environnementales. L’idée est de trouver des sujets susceptibles d’intéresser des étudiants d’horizons différents et je pense que la question de la lutte contre réchauffement climatique peut être fédérateur. A ce stade, il me faut néanmoins préciser que je ne suis pas climatologue et donc que les analyses qui seront réalisées seront purement statistiques. Pour celles et ceux qui voudraient allez au delà, je recommande la lecture du nouveau rapport produit par le GIEC qui montre une nouvelle fois la situation alarmante dans laquelle nous trouvons.
Obtenir les données
La premier étape de tout travail statistique repose sur une collecte de données. Plus celle-ci sera rigoureuse, meilleure sera la qualité des conclusions qui pourront en être tirées. Ici, nous intéresserons à l’évolution des températures sur une période longue si possible au moins deux siècles. Nous devons donc déléguer… Après, une rapide recherche sur internet, je suis parvenu à identifier le plus long historique relevé journaliers disponible, celui réalisé par le centre Hadley du service métrologique du Royaume-Uni. Celui-ci court du 1er janvier 1772 à nos jours et concerne les températures moyennes constatées sur un triangle formé par Bristol, le Lancashire et Londres.
Commençons donc par charger ces données dans R et regardons comment elles se présentent.
dat<-read.table("https://hadleyserver.metoffice.gov.uk/hadcet/cetdl1772on.dat")
head(dat)## V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14
## 1 1772 1 32 -15 18 25 87 128 187 177 105 111 78 112
## 2 1772 2 20 7 28 38 77 138 154 158 143 150 85 62
## 3 1772 3 27 15 36 33 84 170 139 153 113 124 83 60
## 4 1772 4 27 -25 61 58 96 90 151 160 173 114 60 47
## 5 1772 5 15 -5 68 69 133 146 179 170 173 116 83 50
## 6 1772 6 22 -45 51 77 113 105 175 198 160 134 134 42On a sur la premier colonne (V1) l’année, sur la seconde (V2) le jour et les douze colonnes suivantes reprennent pour chaque mois (un par colonnes) les températures constatées en dixièmes de degré Celsius.
Mettre en forme les données
Les données ne sont pas directement utilisables. Il va donc falloir procéder à quelques transformations avant de pouvoir entrer dans le vif du sujet. Commençons par renommer les colonnes pour y voir plus clair.
colnames(dat)<-c('year','day',paste0('month_',1:12))
head(dat)## year day month_1 month_2 month_3 month_4 month_5 month_6 month_7 month_8
## 1 1772 1 32 -15 18 25 87 128 187 177
## 2 1772 2 20 7 28 38 77 138 154 158
## 3 1772 3 27 15 36 33 84 170 139 153
## 4 1772 4 27 -25 61 58 96 90 151 160
## 5 1772 5 15 -5 68 69 133 146 179 170
## 6 1772 6 22 -45 51 77 113 105 175 198
## month_9 month_10 month_11 month_12
## 1 105 111 78 112
## 2 143 150 85 62
## 3 113 124 83 60
## 4 173 114 60 47
## 5 173 116 83 50
## 6 160 134 134 42C’est déjà mieux, mais ce n’est toujours pas exploitable. Ce que l’on veut, c’est simplement deux colonnes: une avec la date et une avec la température relevée. Nous allons donc devoir étendre la base de manière à ce que les colonnes de mois (month_1,…) s’empilent pour donner deux colonnes une indiquant le mois et une la température pour l’année, le mois et le jour considéré. Pour ce faire, nous allons utiliser la fonction pivot_longer() qui fait partie du package tidyverse. Ce dernier comprend également GGPLOT2, et donc une fois chargé, il ne sera donc pas nécessaire d’appeler spécifiquement le package graphique par la suite. Indiquons dans la fonction que l’on veut étendre les colonnes commençant par month_ pour les inclure dans une colonne nommée month. Indiquons également que nous ne voulons pas que le prefix month_ apparaisse parmi les valeurs de la nouvelle colonnes et que la colonnes où figureront les températures sera nommée d_t. Ceci fait, créons la variable date regroupant le jour, le mois et l’année. Limitons la base à la colonne date et d_t. Supprimons les valeurs manquantes ici indiquées par des valeurs de température égales à -999. Enfin, rétablissons les valeurs en degré et non en dixièmes de degrés.
library(tidyverse)
dat_<-dat%>%pivot_longer(cols=starts_with('month_'),names_to="month",
names_prefix='month_',values_to='d_t')%>%
mutate(date=as.Date(paste0(day,'/',month,'/',year),
format='%d/%m/%Y',origin='1/1/1990'))%>%
select(date,d_t)%>%
arrange(date)%>%
mutate(d_t=ifelse(d_t==-999,NA,d_t),
degre_C=d_t/10)%>%
filter(is.na(d_t)==FALSE)%>%
select(-d_t)
head(dat_)## # A tibble: 6 x 2
## date degre_C
## <date> <dbl>
## 1 1772-01-01 3.2
## 2 1772-01-02 2
## 3 1772-01-03 2.7
## 4 1772-01-04 2.7
## 5 1772-01-05 1.5
## 6 1772-01-06 2.2nrow(dat_)## [1] 91158On obtient une base à deux variables (la date et la température relevée), soit une série chronologique comprenant 91 158 valeurs correspondant au nombre de jours entre le 1er janvier 1772 et le 31 juillet 2021.
Représenter les données
On peut maintenant s’attaquer la représentation de ces données. Mais que choisir? Une courbe? Cela donnerait l’illusion d’avoir une mesure continue des températures alors que nous n’en avons que des mesures ponctuelles (journalières). Ici, compte tenu du nombre d’observations, cette approximation ne serait pas trop préjudiciable. J’opte néanmoins pour le nuage de points. Voyons ce que cela donne avec R base (on ne perd pas si vite les mauvaises habitudes).
plot(dat_)
Pour être honnête, on ne voit pas grand chose. Chaque relevé journalier est représenté par un petit cercle. Il est difficile de lire une quelconque tendance à partir de là. Sauf, peut être, une légère remontée en toute toute fin de série, en tout cas rien de très significatif sur notre graphe (qui n’est d’ailleurs pas très beau). Voyons ce que l’on obtient avec GGPLOT2. Désignons dat_ comme sujet et identifions les éléments de dat_ qui seront représentés avec la fonction aes() pour l’anglais aesthetic : la date et la temperature (deg_C). Ajoutons que nous voulons un nuage de point en applant la fonction geom_point().
ggplot(dat_,aes(x=date,y=degre_C))+geom_point()
Ce n’est pas beaucoup mieux. Les points sont plus petits et la grille blanche sur fond gris permet une lecture plus rapide. On voit mieux le décrochage sur la toute fin de la série mais cela reste sujet à caution. Essayons d’ajouter une ligne horizontale marquant la température moyenne sur l’ensemble de la période en utilisant la fonction geom_hline(). Pour qu’elle soit visible, traçons la en rouge. Profitons en pour rendre plus lisible la légende de nos axes avec xlab() et ylab() et ajoutons un titre.
ggplot(dat_,aes(x=date,y=degre_C))+geom_point()+geom_hline(yintercept=mean(dat_$degre_C),color='red')+
xlab('Date (jour)')+ylab('Température (degrés Celsius)')+
ggtitle("Températures moyennes journalières au centre de l'Angleterre (1772-2021)")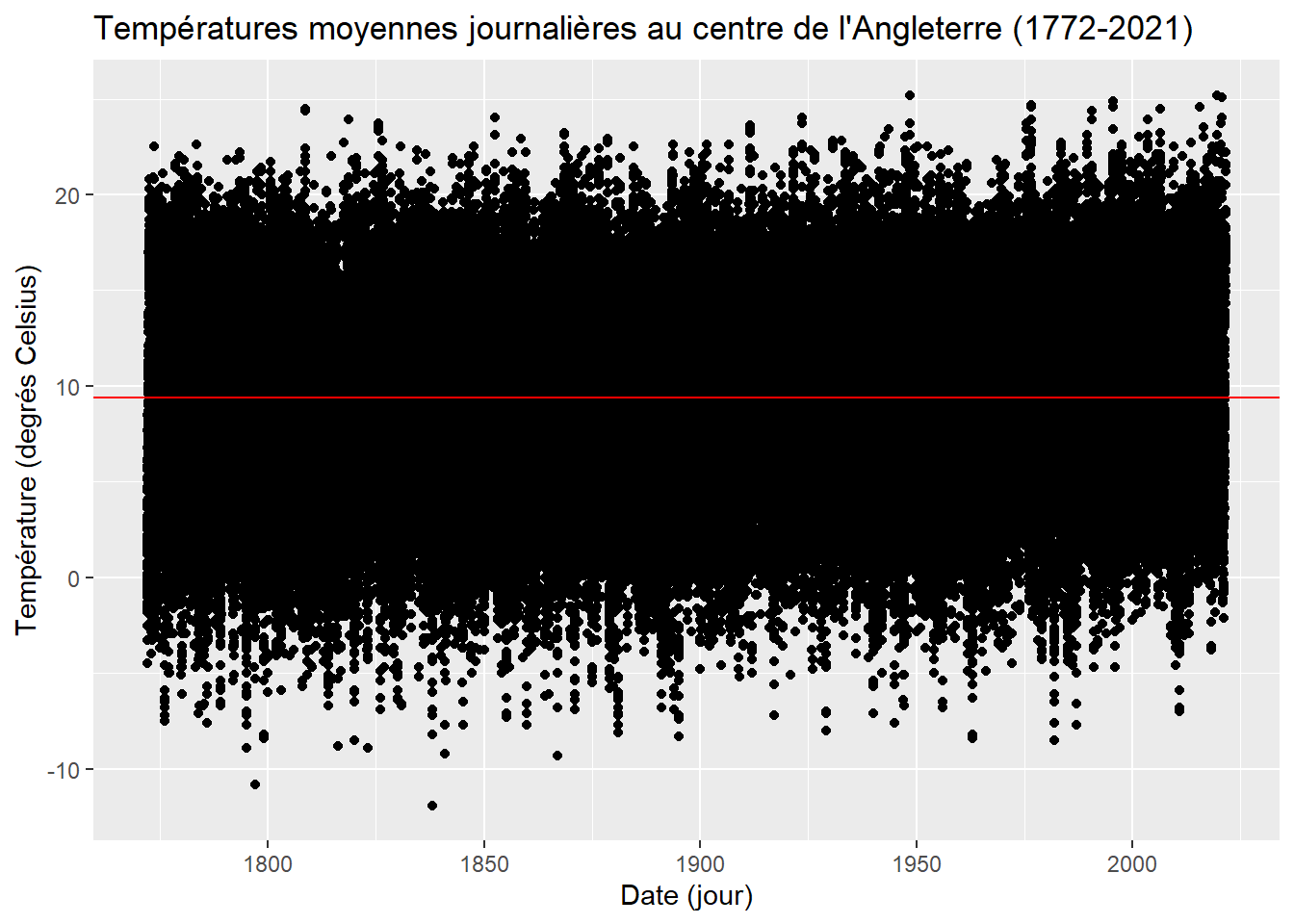
C’est mieux, mais il y a beaucoup trop de points pour y voir les choses clairement. Essayons de voir si la tendance se dessine mieux en agrégeant les températures sur des moyennes mensuelles. Créons pour cela une nouvelle base. Utilisons le fonction as.yearmon() du package zoo pour obtenir directement le bon découpage temporelle.
d_m<-dat_%>%mutate(dd=zoo::as.yearmon(date))%>%
group_by(dd)%>%
summarise(deg_C=round(mean(degre_C),digits=2))
head(d_m)## # A tibble: 6 x 2
## dd deg_C
## <yearmon> <dbl>
## 1 janv. 1772 1.22
## 2 févr. 1772 1.88
## 3 mars 1772 4.39
## 4 avr. 1772 6.41
## 5 mai 1772 10.1
## 6 juin 1772 16.1On passe d’un peu plus de 91000 jours à 2995 mois ce qui devrait éclaircir un peu les choses. Réalisons un nouveau graphe pour voir ce qu’il en est.
ggplot(d_m,aes(x=dd,y=deg_C))+geom_point()+geom_hline(yintercept=mean(d_m$deg_C),color='red')+
xlab('Date (mois)')+ylab('Température (degrés Celsius)')+
ggtitle("Températures moyennes mensuelles au centre de l'Angleterre (1772-2021)")
Encore une fois, c’est mieux mais les points sont encore trop nombreux pour lire une tendance claire. Voyons ce qu’il en est, si l’on agrège l’information sur une base annuelle. Pour ce faire, utilisons la fonction year() du package lubridate.
d_y<-dat_%>%mutate(dd=lubridate::year(date))%>%
group_by(dd)%>%
summarise(deg_C=round(mean(degre_C),digits=2))
head(d_y)## # A tibble: 6 x 2
## dd deg_C
## <dbl> <dbl>
## 1 1772 9.17
## 2 1773 9.29
## 3 1774 9.08
## 4 1775 10.1
## 5 1776 9.01
## 6 1777 9.11Voyons ce que donne le graphe sur cette nouvelle base.
ggplot(d_y,aes(x=dd,y=deg_C))+geom_point()+geom_hline(yintercept=mean(d_m$deg_C),color='red')+
xlab('Date (années)')+ylab('Température (degrés Celsius)')+
ggtitle("Températures moyennes annuelles au centre de l'Angleterre (1772-2021)")
Les choses sont réellement plus nettes avec ce dernier graphe. On constate que les températures moyennes annuelles deviennent de plus en plus chaude à partir de 1900. Il y a moins d’années pour lesquels la température moyenne est inférieur à la moyenne sur la période (1772-2021).Il n’y en a quasiment plus après 2000.
Travailler l’esthétique du graphe pour mieux communiquer
Maintenant que nous avons une vue générale de ce que recèlent nos données, voyons comment mettre l’ensemble en valeur.
Commençons par ajouter une courbe de tendance permettant de mettre en évidence l’évolution des températures. Pour cela utilisons la fonction geom_smooth(). Celle-ci trace une courbe estimée à partir d’une régression loess pratiquée sur nos données. Il s’agit d’une procédure non paramétrique très performante. Pour plus d’explications, je vous conseil la vidéo de StatQuest sur le sujet.
ggplot(d_y,aes(x=dd,y=deg_C))+geom_point()+geom_smooth(se=FALSE)+
geom_hline(yintercept=mean(d_m$deg_C),color='red')+
xlab('Date (années)')+ylab('Température (degrés Celsius)')+
ggtitle("Températures moyennes annuelles au centre de l'Angleterre (1772-2021)")## `geom_smooth()` using method = 'loess' and formula 'y ~ x'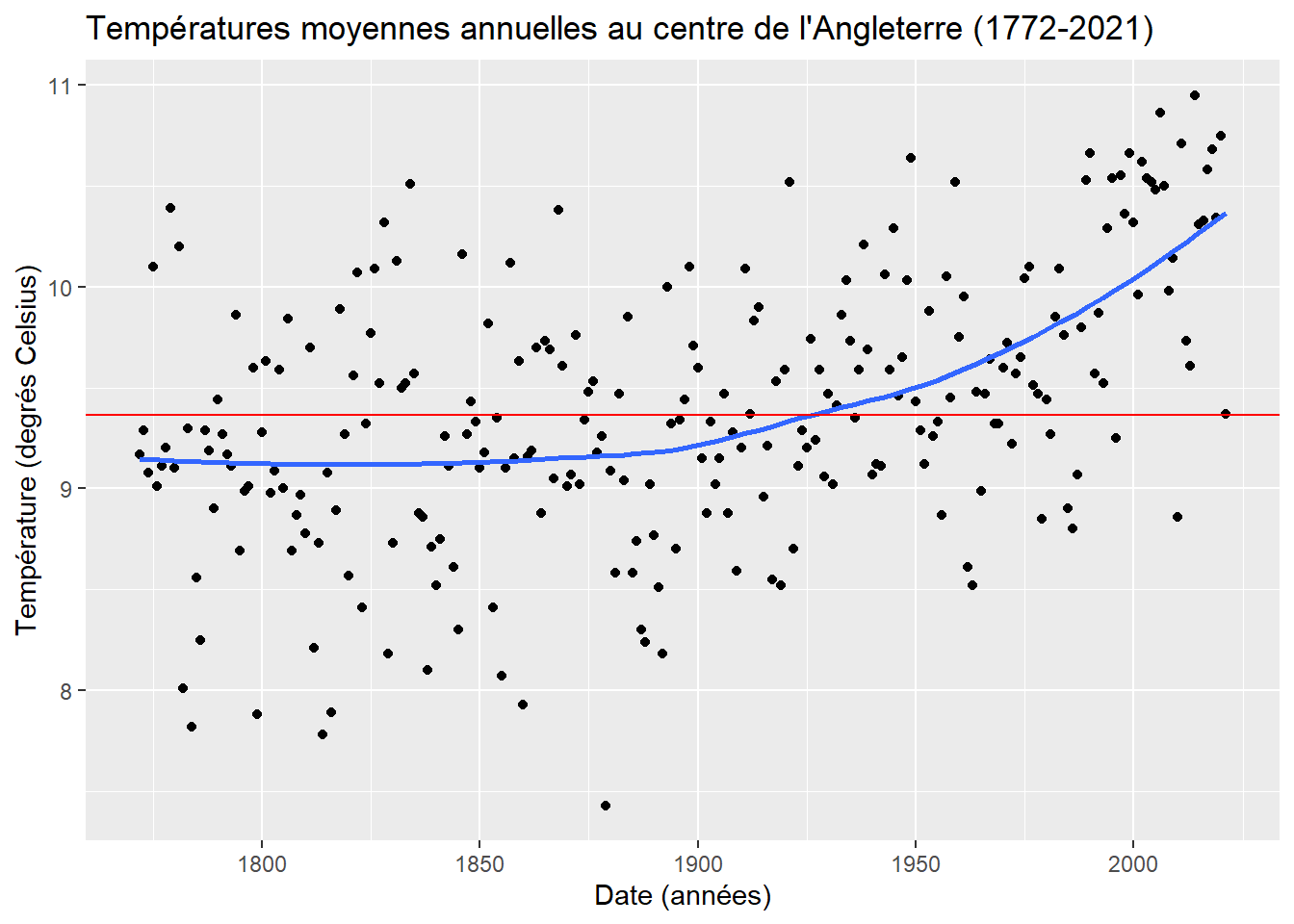
Grace à la courbe en bleu, on voit clairement la tendance à la hausse qui devient nette après 1900. Le message du graphe est plus clair, mais on peut encore améliorer les choses. Ajoutons une légende expliquant la nature des courbes (rouge et bleu). Pour ce faire, indiquons un attribut esthétique, aes(), correspondant à la couleur, dans les geom_ correspondant. Puis, utilisons la fonction scale_coulour_manual() pour personnaliser la légende.
ggplot(d_y,aes(x=dd,y=deg_C))+geom_point()+geom_smooth(se=FALSE,aes(colour="Courbe d'ajustement (loess)"))+
geom_hline(aes(yintercept=mean(d_m$deg_C),colour="Moyenne"))+
xlab('Date (années)')+ylab('Température (degrés Celsius)')+
ggtitle("Températures moyennes annuelles au centre de l'Angleterre (1772-2021)")+
scale_colour_manual(name="Légende", values=c("blue", "red"))## `geom_smooth()` using method = 'loess' and formula 'y ~ x'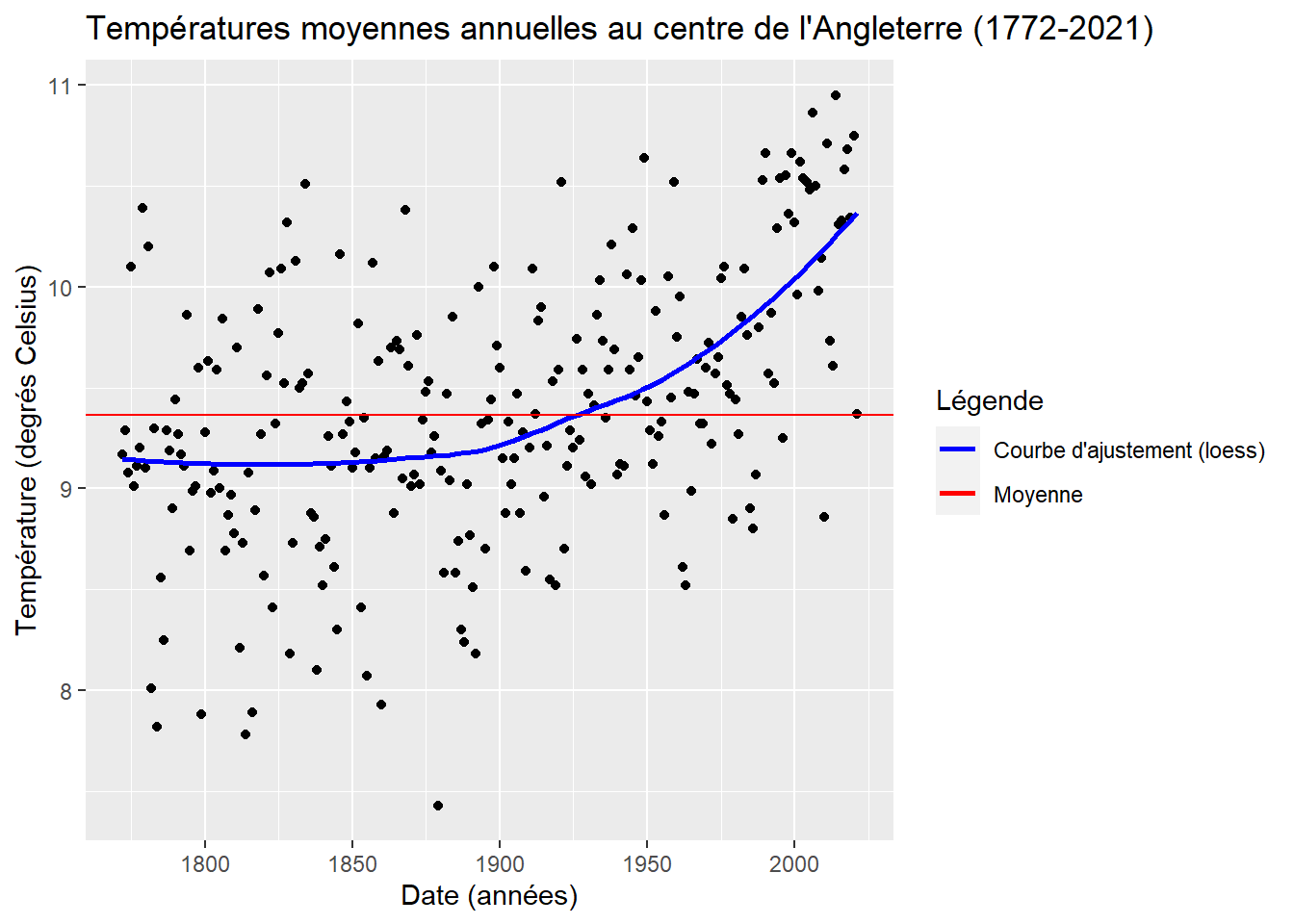
C’est pas mal. Mais, on peut encore faire mieux. Je ne suis pas fan de la grille banc sur gris. Voyons comment changer cela. Celle-ci est associée à des choix graphiques faits par défaut qui sont regroupés dans ce que l’on appelle un thème. Changeons-le pour quelque chose de plus minimaliste en ajoutons à notre phrase theme_minimal(). Profitons-en pour procéder à quelques autres modifications. Retravaillons le titre du graphe et des axes pour être moins redondant dans l’information donnée. Ajoutons un sous titre qui indique le type de représentation dont il s’agit et une note qui précise l’origine des données. Utilisons labs() pour mettre tout ce texte. Ajustons la fenêtre graphique pour qu’elle se resserre autour de notre nuage avec coord_cartesian(). Pour finir, modifions quelques autres options par défaut avec la commande theme(). Changeons la police pour Taille New Roman (qui s’appelle en fait ici serif). Déplaçons la légende, ajoutons lui un cadre…
ggplot(d_y,aes(x=dd,y=deg_C))+geom_point()+geom_smooth(se=FALSE,aes(colour="Courbe d'ajustement (loess)"))+
geom_hline(aes(yintercept=mean(d_m$deg_C),colour="Moyenne"))+
labs(title="Températures moyennes au centre de l'Angleterre (1772-2021)",
subtitle="Nuage de points",
caption="Données: Hadley Center [Parker, Legg et Folland (1992)]",
x='années',y='°C')+
scale_colour_manual(name="Légende", values=c("blue", "red"))+
coord_cartesian(xlim=c(1770,2022),ylim=c(7.2,11),expand = FALSE)+
theme_minimal()+
theme(text=element_text(family="serif"),
plot.title = element_text(size=16,face='bold'),
plot.title.position = 'plot',
plot.margin = margin(25,25,10,25),
legend.background = element_rect(size=0.5, linetype="solid"),
legend.position = "bottom")## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
Voilà qui est bien mieux, mais on peut encore améliorer les choses. Par exemple, en ajoutant des mises en formes différenciées aux différents textes. Pour cela, utilisons le package ggtext qui permet l’introduction d’éléments de langage markdown dans GGPLOT2. Ici, nous nous contenterons des * * pour les éléments en italiques et des ** ** pour ceux en gras mais on pourrait aller bien au delà. Profitions en aussi pour déplacer légèrement notre note sur l’origine des données que je trouve bien trop proche de la légende et réorientons l’étiquette des ordonnées pour qu’elle soit plus lisible.
library(ggtext)
ggplot(d_y,aes(x=dd,y=deg_C))+geom_point()+geom_smooth(se=FALSE,aes(colour="Courbe d'ajustement (loess)"))+
geom_hline(aes(yintercept=mean(d_m$deg_C),colour="Moyenne"))+
labs(title="*Températures moyennes au centre de l'Angleterre* (*1772-2021*)",
subtitle="*Nuage de points*",
caption="*Données: centre Hadley [Parker, Legg et Folland (1992)]*",
x='*années*',y='°C')+
scale_colour_manual(name="*Légende*", values=c("blue", "red"))+
coord_cartesian(xlim=c(1770,2022),ylim=c(7.2,11),expand = FALSE)+
theme_minimal()+
theme(text=element_text(family="serif"),
plot.title = element_markdown(size=16,face='bold'),
plot.title.position = 'plot',
plot.margin = margin(25,25,10,25),
plot.subtitle = element_markdown(),
axis.title.x = element_markdown(),
axis.title.y = element_markdown(angle = 0, vjust = 0.5),
legend.title = element_markdown(),
legend.background = element_rect(size=0.5, linetype="solid"),
legend.position = "bottom",
plot.caption = element_markdown(margin=margin(t=15)))## `geom_smooth()` using method = 'loess' and formula 'y ~ x'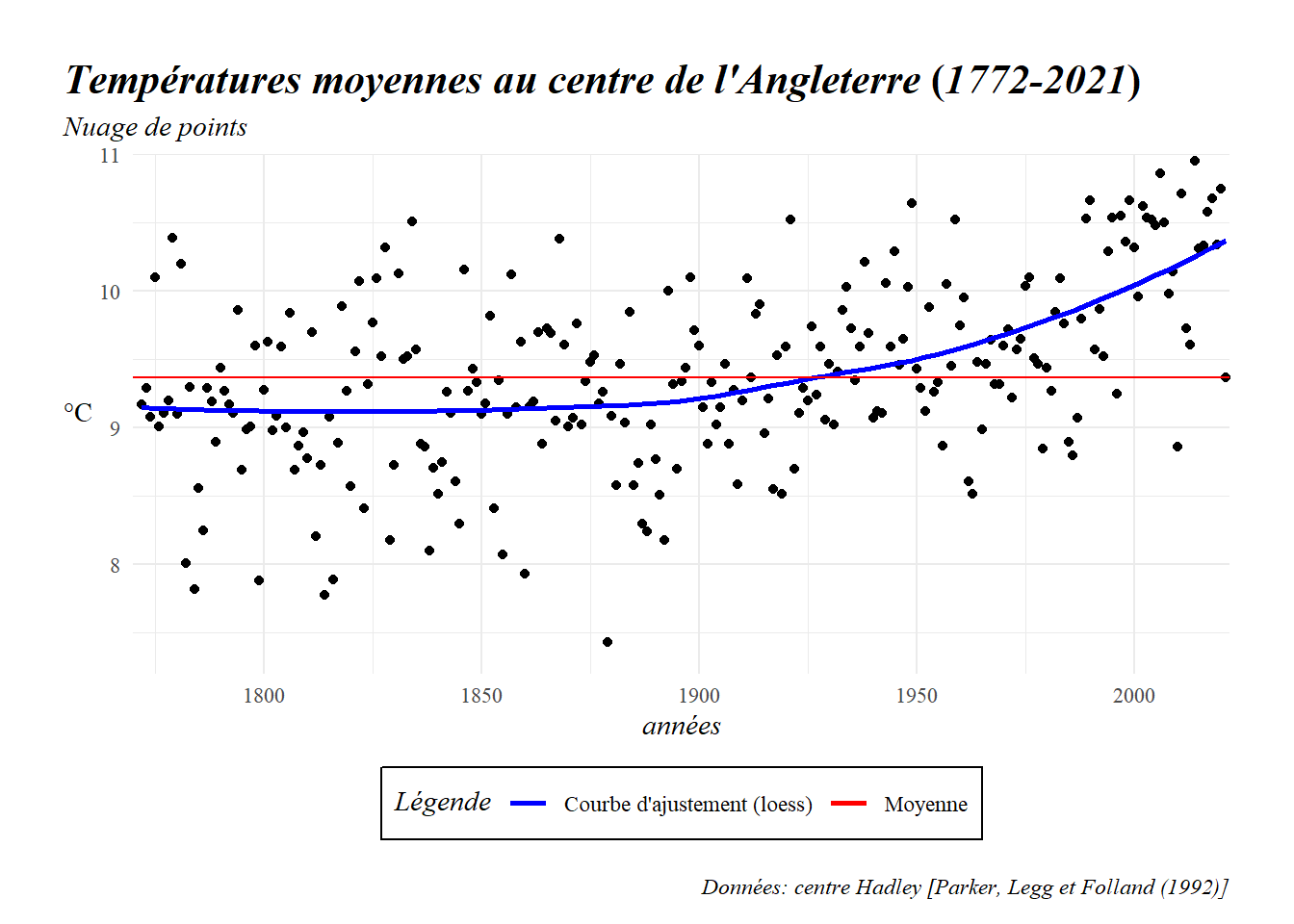
Je pense que l’on pourrait s’arrêter là. Mais,encore une fois, on aller un peu plus loin en essayant de mettre sur la même figure les nuages de points correspondant aux différents découpages temporels retenus (jours, mois, années). On pourrait même envisager d’établir une échelle commune qui faciliterait la comparaison pour bien voir de quelle manière la moyenne (en synthétisant les données) écrase les variations. On également mettre en avant notre dernier graphe dans la mesure où il est le mieux à même de rendre compte du réchauffement constaté. Pour cela, nous allons faire appel à un nouveau package venant compléter GGPLOT2, patchwork. Celui-ci propose une syntaxe simple pour articuler les graphes au sien d’une même figure. Par exemple, si vous voulez juxtaposer les graphes g1 et g2, il vous suffira d’indiquer g1+g2. Si vous voulez les superposer, indiquez g1/g2… Le package permet également d’ajouter des annotations à la figure globale et de travailler le thème qui sera appliqué à l’ensemble.
Commençons donc par créer quatre graphes reprenant nos différentes analyses en version simplifiée : g_j, pour les jours, g_m, pour les mois, g_an, pour les années et g_an_f, pour sa version améliorée. Retenons pour les trois premiers une échelle des ordonnées allant de -12°C à 25°C ce qui permet de ne rien perdre des données journalières. Puis, articulons les graphes de manière à avoir les trois premiers alignés en tête de figure et le quatrième en queue de figure. Cela donne dans patchwork l’expression suivante: (g_j+g_m+g_an)/g_an_f. Procédons à un peu d’habillage et voyons le résultat.
library(patchwork)
g_j<-ggplot(dat_,aes(x=date,y=degre_C))+geom_point()+
geom_smooth(se=FALSE)+
geom_hline(yintercept=mean(dat_$degre_C),color='red')+
labs(x='**jours**',y='**°C**')+
coord_cartesian(ylim=c(-12,25))+
theme_minimal()
g_m<-ggplot(d_m,aes(x=dd,y=deg_C))+geom_point()+
geom_smooth(se=FALSE)+
geom_hline(yintercept=mean(d_m$deg_C),color='red')+
labs(x='**mois**',y='')+
coord_cartesian(ylim=c(-12,25))+
theme_minimal()
g_an<-ggplot(d_y,aes(x=dd,y=deg_C))+geom_point()+
geom_smooth(se=FALSE)+
geom_hline(yintercept=mean(d_y$deg_C),color='red')+
labs(x='**années**',y='')+
coord_cartesian(ylim=c(-12,25))+
theme_minimal()
g_an_f<-ggplot(d_y,aes(x=dd,y=deg_C))+geom_point()+
geom_smooth(se=FALSE,aes(colour="Tendance (loess regression)"))+
geom_hline(aes(yintercept=mean(d_m$deg_C),colour="Moyenne"))+
labs(x='**années**',y='**°C**')+
scale_colour_manual(name="*Légende*", values=c("red", "blue"))+
coord_cartesian(xlim=c(1770,2022),ylim=c(7.2,11),expand = FALSE)+
theme_minimal()
(g_j+g_m+g_an)/g_an_f+
plot_annotation(title ="Températures moyennes au centre de l'Angleterre (*1772-2021*)",
caption="*Données: Hadley Center [Parker, Legg et Folland (1992)]*")+
theme_minimal()&
theme(text=element_text('serif'),
plot.title=element_markdown(hjust=0.5,face='bold'),
plot.caption = element_markdown(margin=margin(t=15)),
axis.title.x = element_markdown(),
axis.title.y = element_markdown(angle = 0, vjust = 0.5),
legend.title = element_markdown(),
legend.background = element_rect(size=0.5, linetype="solid"),
legend.position = "bottom")## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'
## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
## `geom_smooth()` using method = 'loess' and formula 'y ~ x'
Je suis assez content de la figure obtenue et je pense, que pour une rapide introduction, pas mal de choses ont été abordées.
Dans les futurs billets associés à la préparation de ce cours, j’aborderais d’autres types de figures, d’autres types de données, mais aussi des points moins techniques, plus théoriques, sur les différentes types de représentations. Ce sera l’occasion de porter un regard critique sur certaines d’entre-elles, de voir comment les moins bonnes auraient pu être améliorée et pourquoi les meilleures sont si pertinentes. A chaque fois, j’essaierai (si je trouve les informations nécessaires) de les reproduire avec GGPLOT2 et les packages associés.