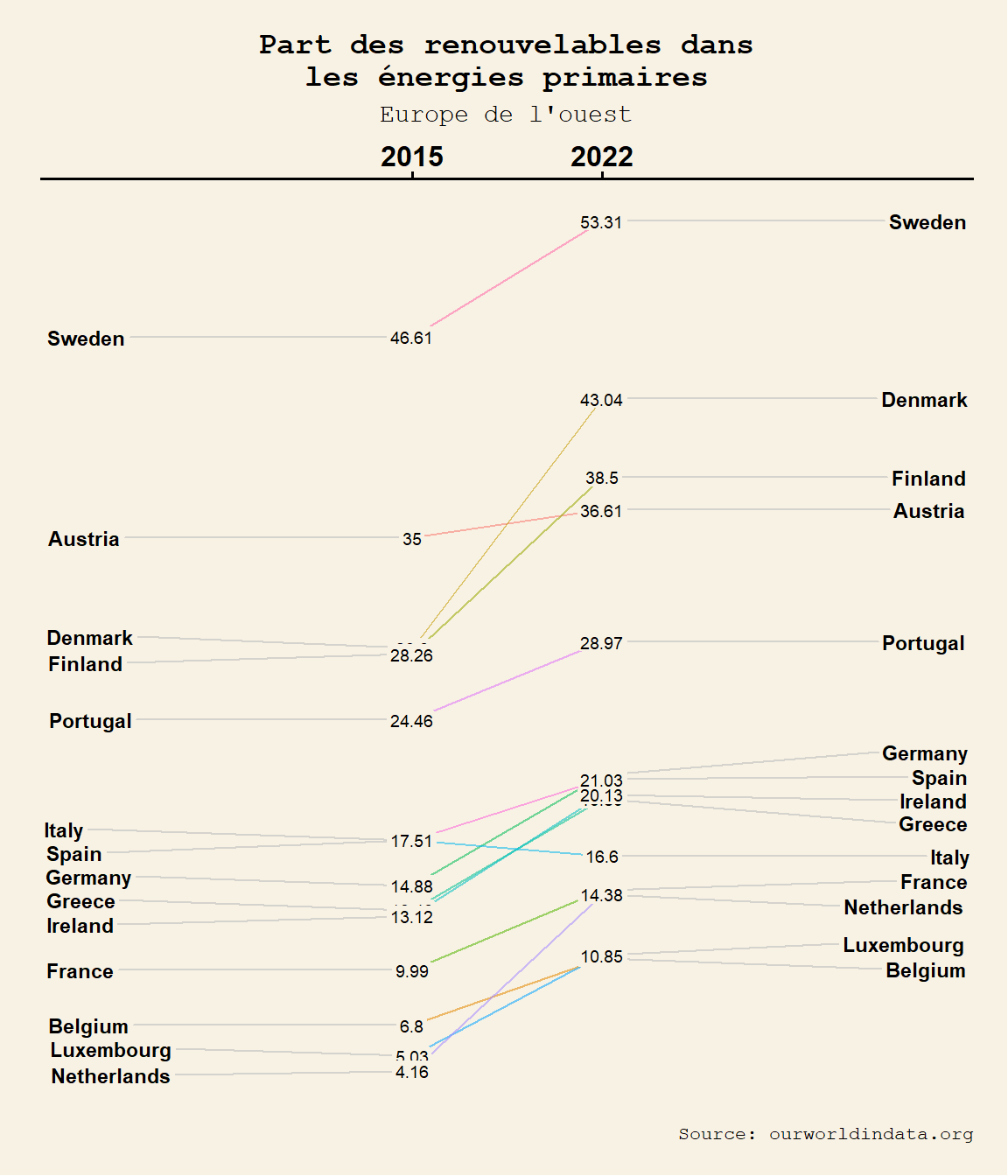
Dans ce dernier post consacré aux graphes destinés à illustrer l’évolution d’une ou plusieurs variables dans le temps, nous allons nous intéresser aux diagrammes de pentes ou slope charts. Il s’agit de la combinaison de lignes horizontales dont le degré d’inclinaison représente l’évolution d’une variable quantitative entre deux dates pour différents individus ou groupes, et de points marquant les valeurs de départ et d’arrivé de manière à mettre en avant des proximités (clustering) et des éloignements (outliers). Ce type de représentation est particulièrement indiqué lorsqu’il s’agit de mettre en avant des tendances. On est ici à la fois sur une forme simplifiée de graphique linéaire (lines chart), de bump chart (avec une seule période) et de graphe à coordonnées parallèles (où le temps est traité comme une variable catégorielle).
Sans aller plus avant sur ces proximité, voyons comment construire notre premier slope chart. Pour cela, en préalable, chargeons les packages nécessaires pour la suite. Ici, nous en utiliserons que quatre: le classique tidyverse, qui pourrait se suffire à lui même; et CGPfunction, qui propose une fonction dédiée à a réalisation de diagramme de pentes en configuration ggplot2, mais aussi, pour la mise en forme, les packages scales (pour les axes ) et viridis (pour la palette de couleurs).
library(tidyverse)
library(CGPfunctions)
library(viridis)
library(scales)Concernant les données que nous allons illustrer, nous nous intéresserons sur la part des énergies renouvelables dans les mix d’énergies primaires des Etats d’Europe de l’ouest (hors Royaume unis). Nous comparerons l’évolution de cette part entre 2015, l’année des accords de Paris, et 2022. Elles sont issues du site ourworldindata.org. Vous les trouverez ici. Chargeons-les dans notre dossier de travail. Puis, importons-les dans R. Ceci fait, limitons les informations aux seuls pays qui nous intéressent (Allemagne, Belgique, France, Italie, Luxembourg, Pays-Bas, Danemark, Irlande, Grèce, Espagne, Portugal, Autriche, Finlande, Suède) et aux variables que nous mobiliserons sur les années retenues. Profitons-en pour renommer la variables d’intérêt le pourcentage d’énergie renouvelables pour une version plus courte plus facile à gérer pour la suite.
dat<-read_csv("renewable-share-energy.csv") %>%
filter(Entity %in% c('Germany','Belgium','France','Italy',
'Luxembourg','Netherlands','Denmark',
'Ireland','Greece','Spain','Portugal',
'Austria','Finland','Sweden')) %>%
filter(Year==2015|Year==2022) %>%
select(-Code) %>%
rename(perc_ren=`Renewables (% equivalent primary energy)`)
head(dat)## # A tibble: 6 × 3
## Entity Year perc_ren
## <chr> <dbl> <dbl>
## 1 Austria 2015 35.0
## 2 Austria 2022 36.6
## 3 Belgium 2015 6.80
## 4 Belgium 2022 10.7
## 5 Denmark 2015 28.6
## 6 Denmark 2022 43.0Maintenant que nous avons les données de base nous pouvons les mettre en forme pour réaliser notre premier slope chart. Celui-ci sera d’abord réalisé directement sous ggplot.
Pour cela, la base doit être légèrement adaptée. Passons les informations indéxées par année en variable donnant l’information pour l’année considérée (Passons d’une base longue à une base large…).
dat_lim_1<-dat %>%
pivot_wider(names_from = Year,
names_prefix = "an_",
values_from = perc_ren)
head(dat_lim_1)## # A tibble: 6 × 3
## Entity an_2015 an_2022
## <chr> <dbl> <dbl>
## 1 Austria 35.0 36.6
## 2 Belgium 6.80 10.7
## 3 Denmark 28.6 43.0
## 4 Finland 28.3 38.5
## 5 France 9.99 14.6
## 6 Germany 14.9 21.3Ceci fait, établissons notre graphe de base. Pour cela, nous allons utiliser deux geom particuliers: le geom_segment(), qui va nous servir à établir le l’évolution le part des énergies renouvelables entre les deux dates retenues 2015-2022 pour chaque pays, et le geom_point(), qui va nous servir à marquer pour les points d’arriver et de départ pour chaque pays.
Concernant les segments les points de départ sont 2015 en abscisse et la part des énergies renouvelables en 2015 (an_2015) en ordonnée, et les points d’arrivé sont 2022 en abscisse et la part des énergies renouvelables en 2022 (an_2022) en ordonnée.
Concernant les points l’abscisse est l’année de départ (2015) ou d’arrivée (2022) et l’ordonnée la part d’énergies renouvelables respectivement l’année de départ (an_2015) et l’année d’arrivée (an_2022).
ggplot(data=dat_lim_1)+
geom_segment(aes(x='2015',xend='2022',y=an_2015,yend=an_2022,
color=Entity))+
geom_point(aes(x='2015',y=an_2015,color=Entity))+
geom_point(aes(x='2022',y=an_2022,color=Entity))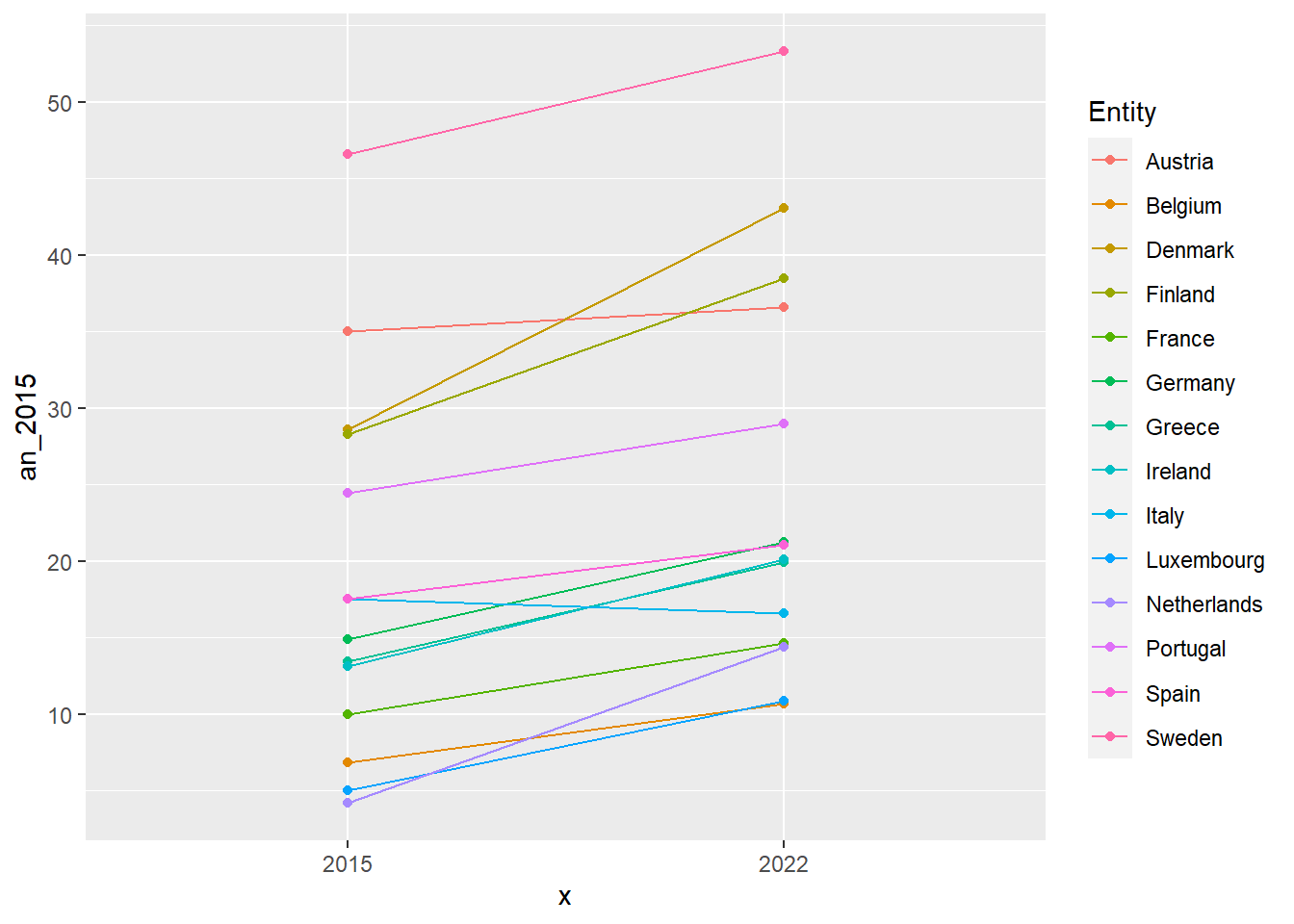
On obtient bien un slope chart mais qui reste difficile à lire. Procédons à quelques mise en forme pour améliorer les choses.
Commençons par passer au theme minimal, ajouter un titre, un sous-titre et un cation et procéder à quelques mises en formes des axes.
ggplot(data=dat_lim_1)+
geom_segment(aes(x='2015',xend='2022',y=an_2015,yend=an_2022,
color=Entity))+
geom_point(aes(x='2015',y=an_2015,color=Entity))+
geom_point(aes(x='2022',y=an_2022,color=Entity))+
labs(title = "Part des renouvellables dans les énergies primaires",
subtitle = "Europe de l'ouest",
caption = "Source: ourworldindata.org")+
scale_y_continuous(labels=label_percent())+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face='bold'),
plot.subtitle = element_text(hjust=0.5,face='italic'),
plot.caption = element_text(hjust=1,face='italic'),
axis.title = element_blank())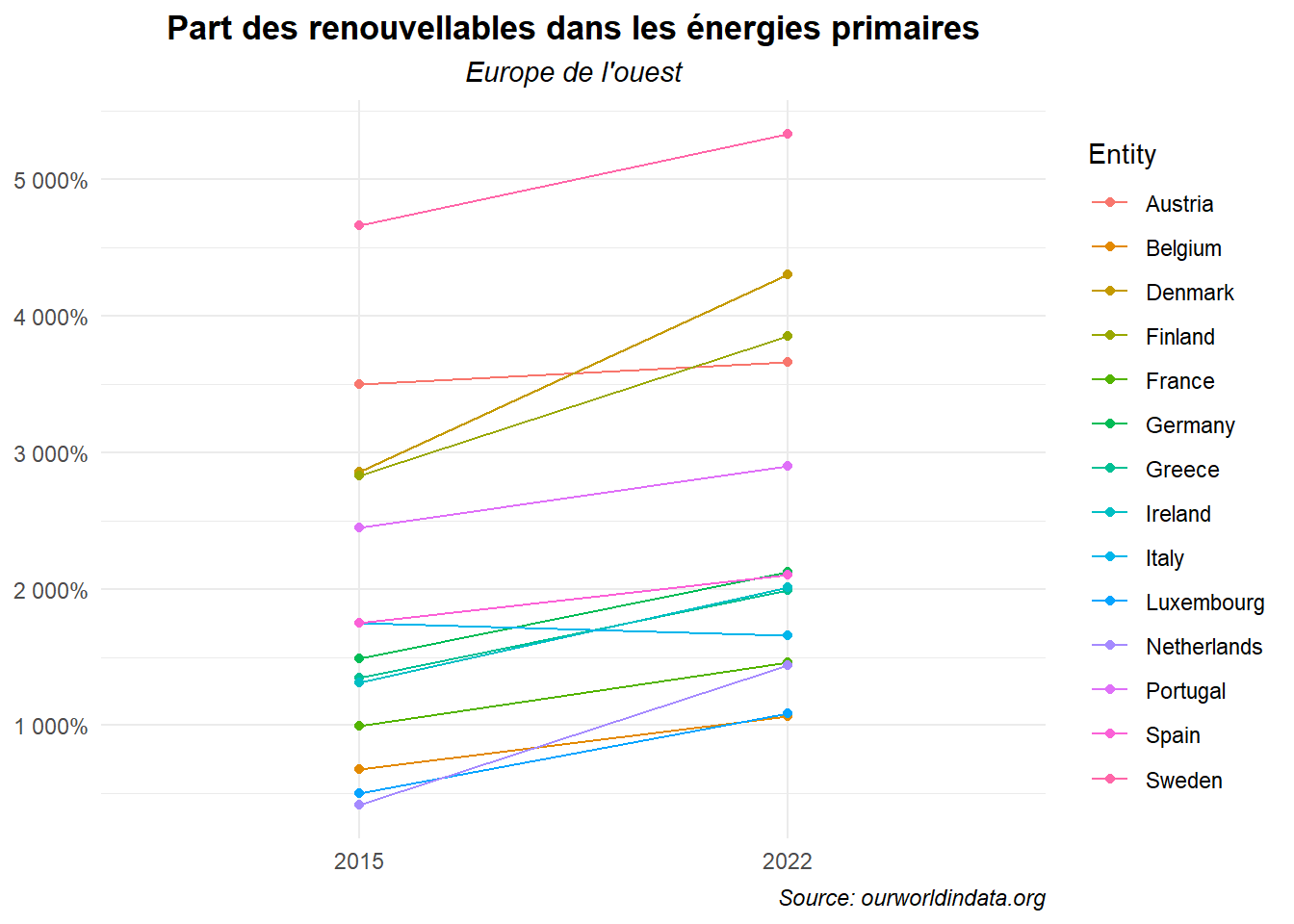
Le passage des axes en pourcentage n’est pas optimal. Voyons comment régler le problème. Pour cela, utilisons l’option scale de la fonction label_percent(). Passons de la valeur par défaut 100 à la valeur 1.
ggplot(data=dat_lim_1)+
geom_segment(aes(x='2015',xend='2022',y=an_2015,yend=an_2022,
color=Entity))+
geom_point(aes(x='2015',y=an_2015,color=Entity))+
geom_point(aes(x='2022',y=an_2022,color=Entity))+
labs(title = "Part des renouvellables dans les énergies primaires",
subtitle = "Europe de l'ouest",
caption = "Source: ourworldindata.org")+
scale_y_continuous(labels=label_percent(scale=1))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face='bold'),
plot.subtitle = element_text(hjust=0.5,face='italic'),
plot.caption = element_text(hjust=1,face='italic'),
axis.title = element_blank())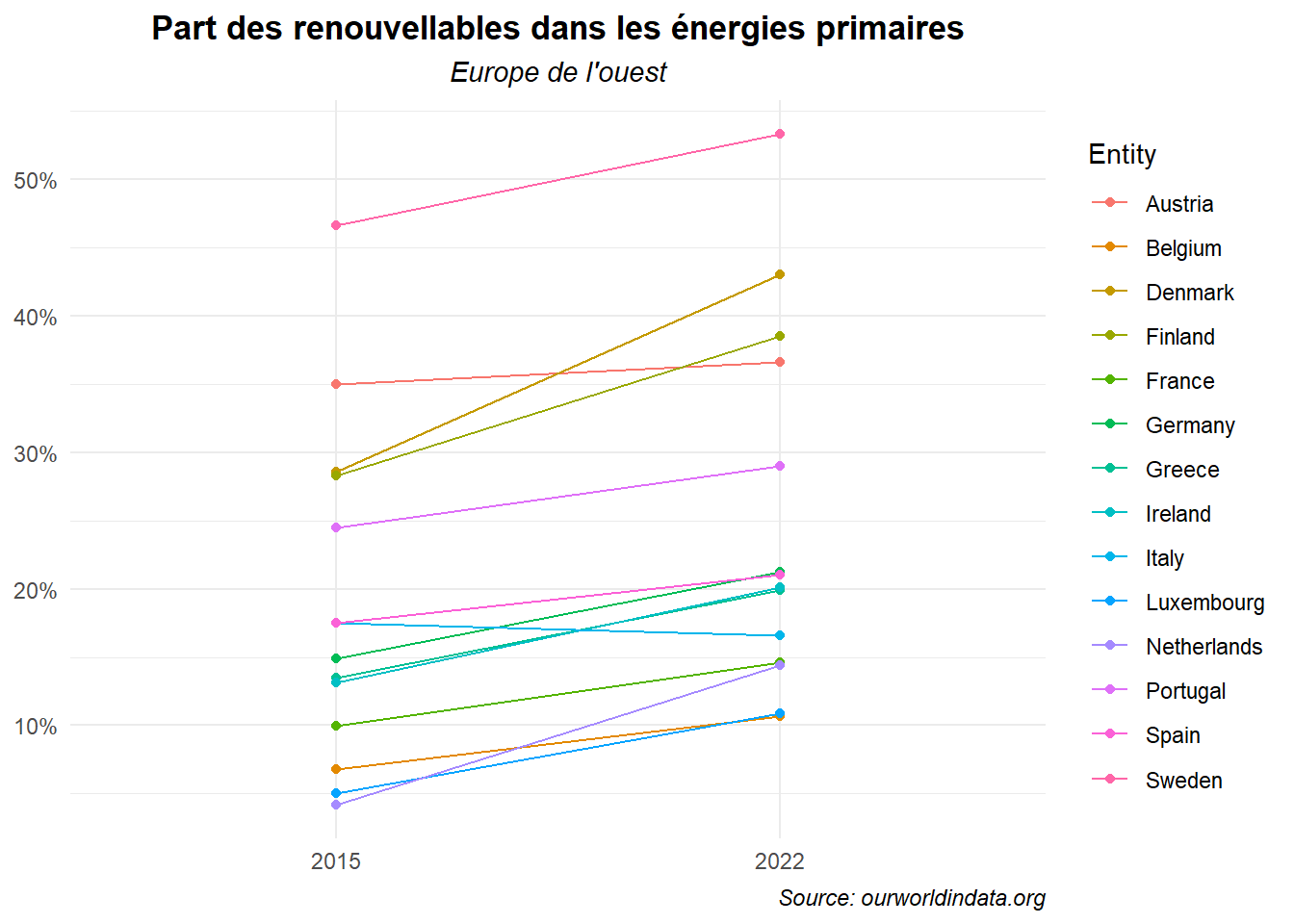
Le problème d’échelle est réglé. Voyons maintenant comment nous passer de la légende qui reste difficile à lire. Intégrons dans la figure les noms des pays en utilisant le geom_text().
ggplot(data=dat_lim_1)+
geom_segment(aes(x='2015',xend='2022',y=an_2015,yend=an_2022,
color=Entity))+
geom_point(aes(x='2015',y=an_2015,color=Entity))+
geom_point(aes(x='2022',y=an_2022,color=Entity))+
geom_text(aes(label=Entity,x='2015',y=an_2015,color=Entity))+
labs(title = "Part des renouvellables dans les énergies primaires",
subtitle = "Europe de l'ouest",
caption = "Source: ourworldindata.org")+
scale_y_continuous(labels=label_percent(scale=1))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face='bold'),
plot.subtitle = element_text(hjust=0.5,face='italic'),
plot.caption = element_text(hjust=1,face='italic'),
axis.title = element_blank(),
legend.position = 'none')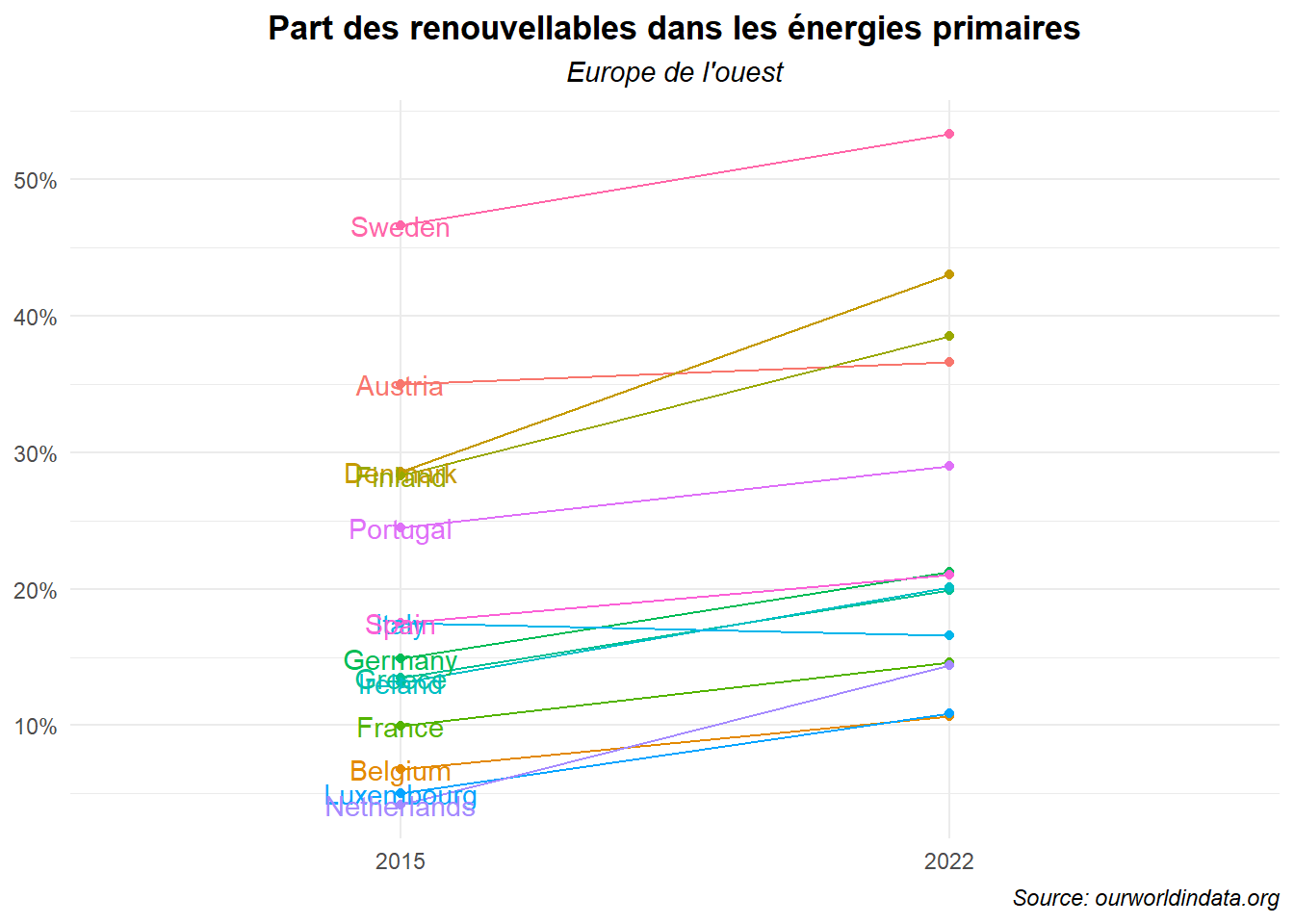
Ce n’est pas très convainquant. Déplaçons les noms sur la gauche et réduisons la taille des lettres.
ggplot(data=dat_lim_1)+
geom_segment(aes(x='2015',xend='2022',y=an_2015,yend=an_2022,
color=Entity))+
geom_point(aes(x='2015',y=an_2015,color=Entity))+
geom_point(aes(x='2022',y=an_2022,color=Entity))+
geom_text(aes(label=Entity,x='2015',y=an_2015,color=Entity),
hjust="outward",vjust="outward",size=3)+
labs(title = "Part des renouvellables dans les énergies primaires",
subtitle = "Europe de l'ouest",
caption = "Source: ourworldindata.org")+
scale_y_continuous(labels=label_percent(scale=1))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face='bold'),
plot.subtitle = element_text(hjust=0.5,face='italic'),
plot.caption = element_text(hjust=1,face='italic'),
axis.title = element_blank(),
legend.position = 'none')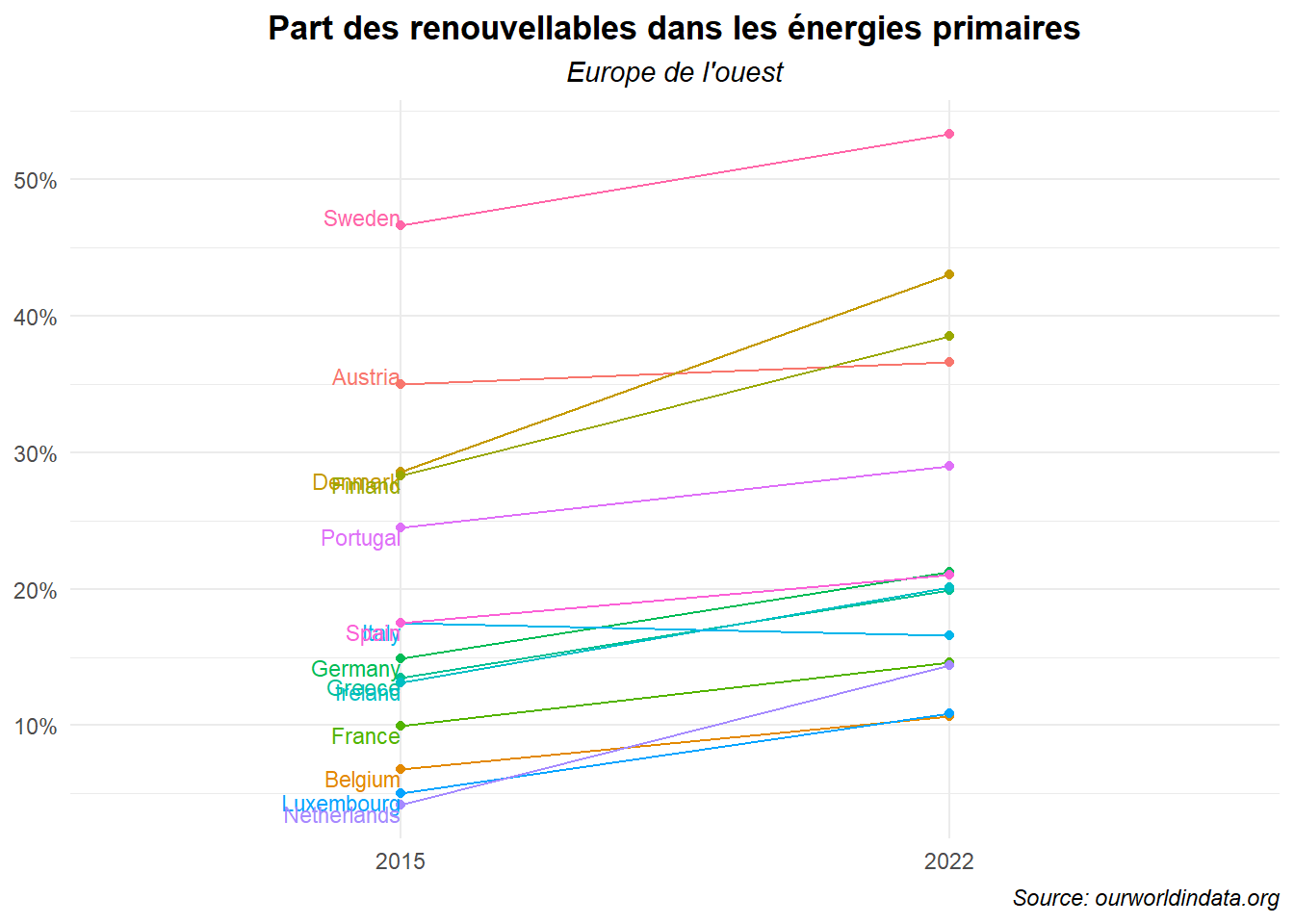
Ce n’est toujours pas clair. On a beaucoup de noms qui se chevauchent. Essayons de les placer alternativement d’un côte puis de l’autre. Pour cela, nous devons créer deux variables supplémentaires une pour l’année (an_af) et une pour la part des énergies renouvelables cette année là (pos_af). L’articulation des valeurs se fait sur la base d’une indexation des valeurs paires/impaires.
dat_lim_1<-dat_lim_1 %>%
arrange(an_2015) %>%
mutate(nrow=1:n(),
an_af=if_else(nrow %% 2==0,'2015','2022'),
pos_af=if_else(nrow %% 2==0,an_2015,an_2022))
head(dat_lim_1)## # A tibble: 6 × 6
## Entity an_2015 an_2022 nrow an_af pos_af
## <chr> <dbl> <dbl> <int> <chr> <dbl>
## 1 Netherlands 4.16 14.4 1 2022 14.4
## 2 Luxembourg 5.03 10.9 2 2015 5.03
## 3 Belgium 6.80 10.7 3 2022 10.7
## 4 France 9.99 14.6 4 2015 9.99
## 5 Ireland 13.1 20.1 5 2022 20.1
## 6 Greece 13.5 19.9 6 2015 13.5Utilisons ces variables comme coordonnés pour les éléments de textes.
ggplot(data=dat_lim_1)+
geom_segment(aes(x='2015',xend='2022',y=an_2015,yend=an_2022,
color=Entity))+
geom_point(aes(x='2015',y=an_2015,color=Entity))+
geom_point(aes(x='2022',y=an_2022,color=Entity))+
geom_text(aes(label=Entity,x=an_af,y=pos_af,color=Entity),
hjust="outward",vjust="outward",size=3)+
labs(title = "Part des renouvellables dans les énergies primaires",
subtitle = "Europe de l'ouest",
caption = "Source: ourworldindata.org")+
scale_y_continuous(labels=label_percent(scale=1))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face='bold'),
plot.subtitle = element_text(hjust=0.5,face='italic'),
plot.caption = element_text(hjust=1,face='italic'),
axis.title = element_blank(),
legend.position = 'none')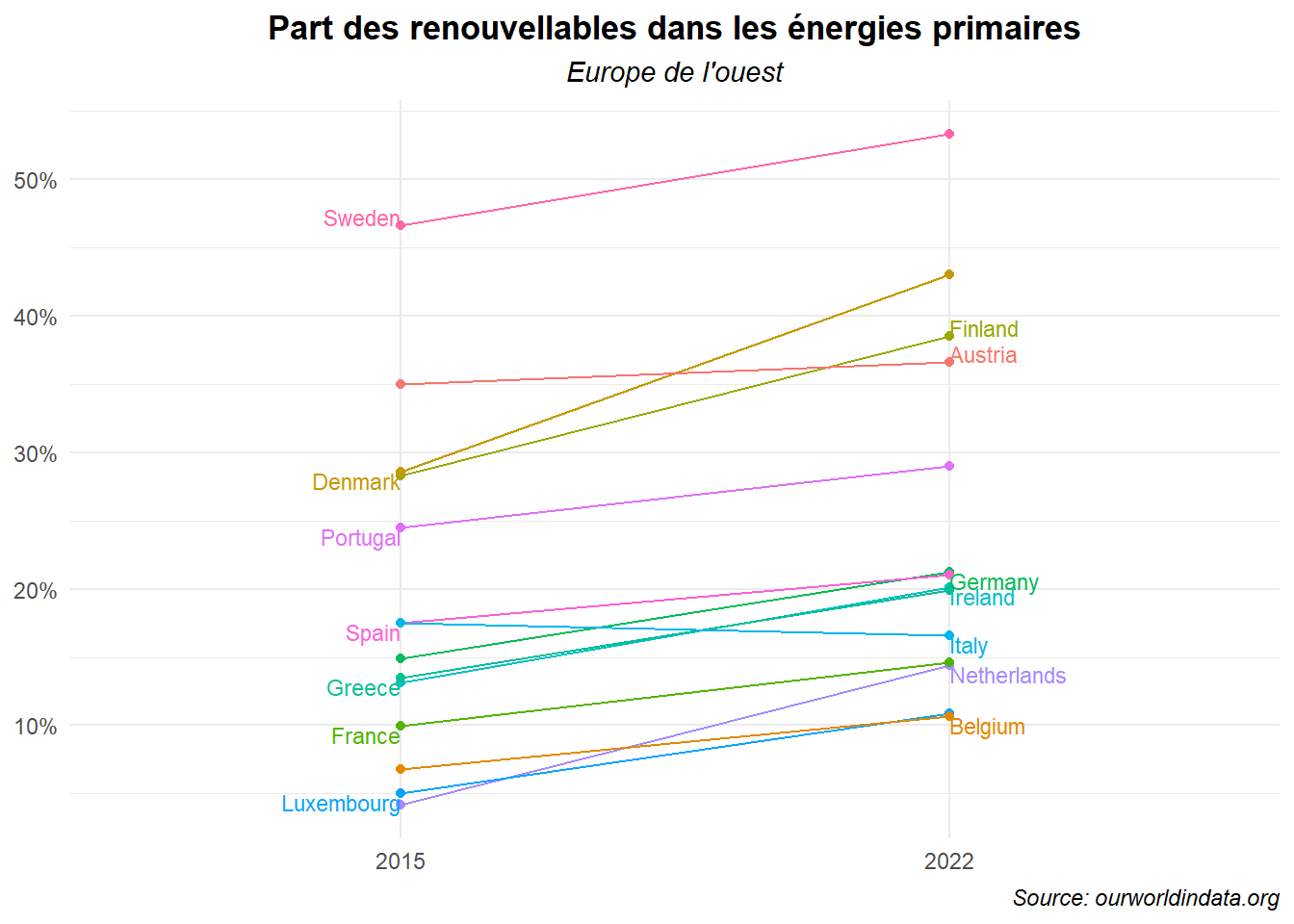
Des noms de pays se chevauchent et ils sont globalement tous trop prêt des points marquant les valeurs. Utilisons les options nudge_x et nudge_y du geom_text() pour créer les décalages adéquates. Ces décalages doivent être gérés au cas par cas aussi établissons-nous des variables pour les indiquer.
dat_lim_1<-dat_lim_1 %>%
mutate(nudge_y=case_when(Entity=="Austria"~-1,
Entity=="Finland"~+0,
Entity=="Ireland"~+1,
Entity=="Italy"~+2,
Entity=="Netherlands"~+1,
Entity=="Germany"~+2,
Entity=="Belgium"~+1,
Entity=="Denmark"~+0.5, Entity=="Portugal"~+1,
Entity=="Spain"~+2,
Entity=="Greece"~+1,
Entity=="France"~+1,
Entity=="Luxembourg"~+1,TRUE~0),
nudge_x=case_when(Entity=="Finland"~+0.02,
Entity=="Austria"~+0.02,
Entity=="Sweden"~-0.02,
Entity=="Germany"~+0.02,
Entity=="Ireland"~+0.02,
Entity=="Italy"~+0.02,
Entity=="Netherlands"~+0.02,
Entity=="Belgium"~+0.02,
Entity=="Denmark"~-0.02,
Entity=="Portugal"~-0.02,
Entity=="Spain"~-0.02,
Entity=="Greece"~-0.02,
Entity=="France"~-0.02,
Entity=="Luxembourg"~-0.02,
TRUE~0))
head(dat_lim_1)## # A tibble: 6 × 8
## Entity an_2015 an_2022 nrow an_af pos_af nudge_y nudge_x
## <chr> <dbl> <dbl> <int> <chr> <dbl> <dbl> <dbl>
## 1 Netherlands 4.16 14.4 1 2022 14.4 1 0.02
## 2 Luxembourg 5.03 10.9 2 2015 5.03 1 -0.02
## 3 Belgium 6.80 10.7 3 2022 10.7 1 0.02
## 4 France 9.99 14.6 4 2015 9.99 1 -0.02
## 5 Ireland 13.1 20.1 5 2022 20.1 1 0.02
## 6 Greece 13.5 19.9 6 2015 13.5 1 -0.02Utilisons les variables créées pour alimenter les options nudge_x et nudge_y du geom_text(). Profitons-en pour travailler les couleurs du graphe pour le rendre plus lisible. Mobilisons viridis qui propose des palettes adaptées aux daltoniens. Nous choisissons la palette turbo et passons le fond en gris pour forcer le contraste.
ggplot(data=dat_lim_1)+
geom_segment(aes(x='2015',xend='2022',y=an_2015,yend=an_2022,
color=Entity))+
geom_point(aes(x='2015',y=an_2015,color=Entity))+
geom_point(aes(x='2022',y=an_2022,color=Entity))+
geom_text(aes(label=Entity,x=an_af,y=pos_af,color=Entity),
hjust="outward",vjust="outward",size=3,
nudge_y = dat_lim_1$nudge_y,
nudge_x = dat_lim_1$nudge_x)+
labs(title = "Part des renouvellables dans les énergies primaires",
subtitle = "Europe de l'ouest",
caption = "Source: ourworldindata.org")+
scale_y_continuous(labels=label_percent(scale=1))+
scale_color_viridis(discrete = TRUE,option = "H") +
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5,face='bold'),
plot.subtitle = element_text(hjust=0.5,face='italic'),
plot.caption = element_text(hjust=1,face='italic'),
axis.title = element_blank(),
panel.background = element_rect(fill='#F2F3F4'),
legend.position = 'none')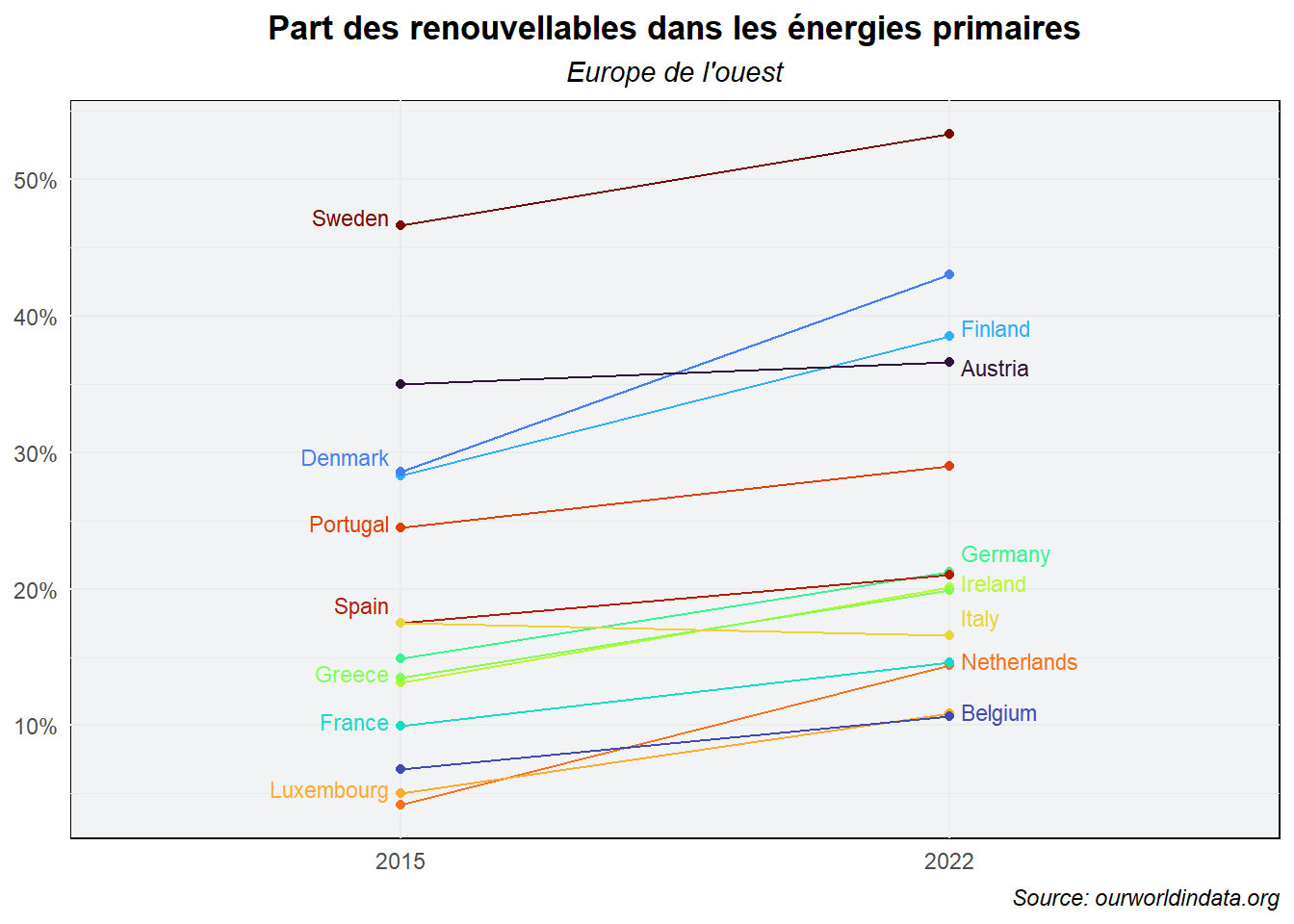
Le graphe obtenu m’apparaît satisfaisant. Voyons ce que l’on obtient en utilisant le package GGPfunction et plus précisément la fonction newggslopegraph(). Pour cela, revenons à des données au format long (avec une variable plus la mesure et une variable pour l’année de mesure).
dat_lim_2<-dat %>% filter(Year==2015|Year==2022) %>%
mutate(Year_=as.character(Year),
perc_ren=round(perc_ren,digits=2))
head(dat_lim_2)## # A tibble: 6 × 4
## Entity Year perc_ren Year_
## <chr> <dbl> <dbl> <chr>
## 1 Austria 2015 35 2015
## 2 Austria 2022 36.6 2022
## 3 Belgium 2015 6.8 2015
## 4 Belgium 2022 10.7 2022
## 5 Denmark 2015 28.6 2015
## 6 Denmark 2022 43.0 2022Commençons par une version simple. Indiquons uniquement la source des données et les variables représentées.
newggslopegraph(dataframe = dat_lim_2,
Times = Year_,
Measurement = perc_ren,
Grouping = Entity)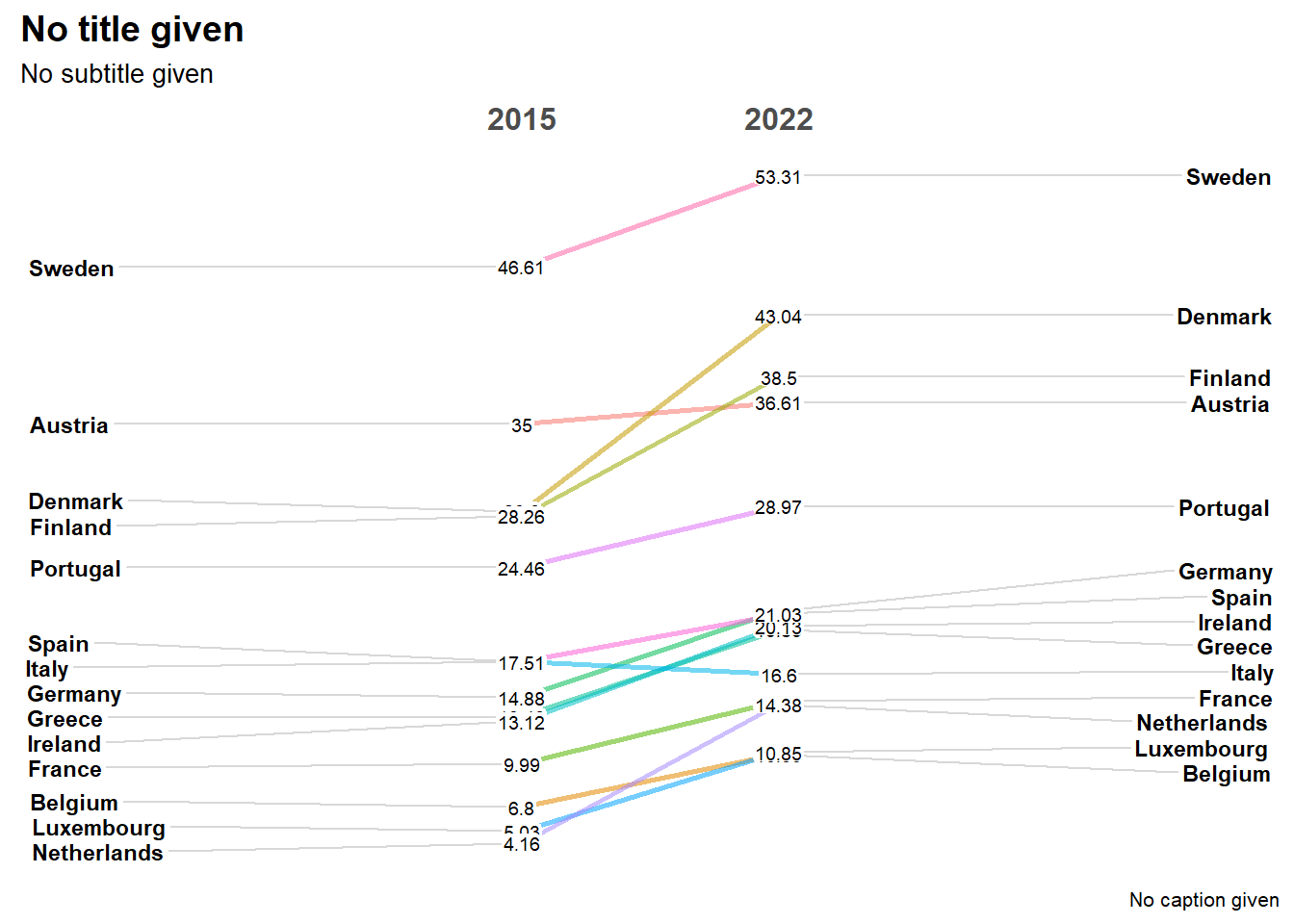
Le graphe obtenu est intéressant mais il y a chevauchement de certaines valeurs. Voyons comment y remédier et profitons-en pour ajouter des éléments d’informations complémentaires (titres, sous-tires, caption).
Réduisons la taille des caractères des données (2) et l’épaisseur des étiquettes (0.5).
newggslopegraph(dataframe = dat_lim_2,
Times = Year_,
Measurement = perc_ren,
Grouping = Entity,
Title = "Part des renouvelables dans
les énergies primaires",
SubTitle="Europe de l'ouest",
Caption = "Source: ourworldindata.org",
TitleJustify='C',
SubTitleJustify='C',
DataTextSize=2,
LineThickness=0.5,
DataLabelPadding=0)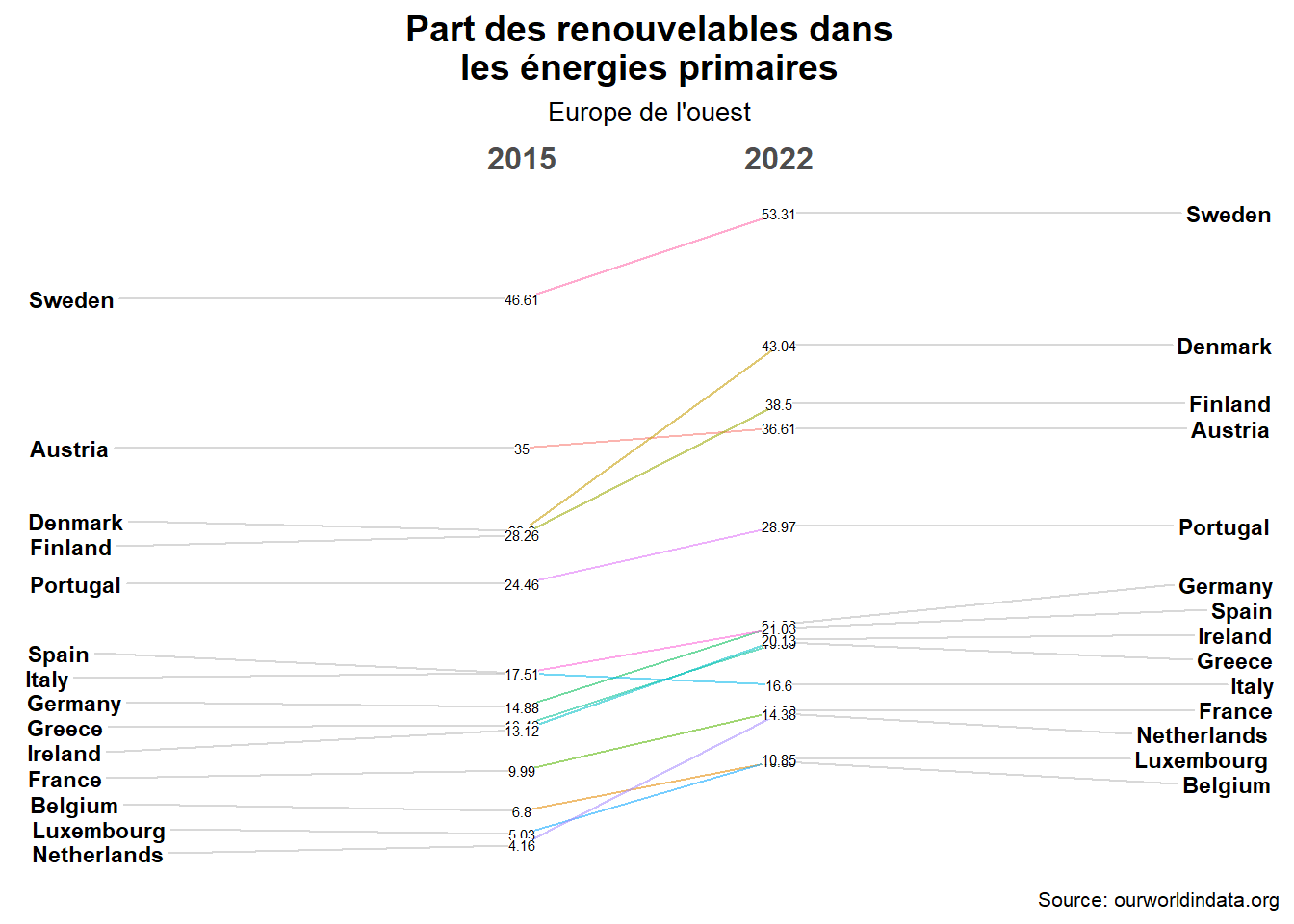
On a encore de la superposition. Élargissons la figure passons à un format 7 sur 6. Passons également à un thème particulier. Choisissons celui répliquant le style Wall Street journal (wsj).
newggslopegraph(dataframe = dat_lim_2,
Times = Year_,
Measurement = perc_ren,
Grouping = Entity,
Title = "Part des renouvelables dans
les énergies primaires",
SubTitle="Europe de l'ouest",
Caption = "Source: ourworldindata.org",
TitleJustify='C',
SubTitleJustify='C',
DataTextSize=2.5,
LineThickness=0.4,
ThemeChoice='wsj',
DataLabelPadding=0.1)