Revenons sur nos graphes présentant des séries temporelles. Leur représentation la plus classique, nous l’avons vu, consiste à établir une courbe associant en ordonnées les valeurs aux dates de mesure en abscisses. Cela permet d’obtenir une vision claire des tendances mais laisse généralement peu de place à la mise en valeur des effets cumulés des évolutions. Une possibilité pour remédier à cette relative faiblesse est de mettre en avant l’aire sous la courbe. Pour cela, on peut utiliser un area chart (une graphe d’aire). Voyons cela dans ce nouveau poste.
Commençons par charger quelques packages utiles pour la suite.
library(tidyverse)
library(scales)
library(viridis)Ceci fait, il nous faut des données pour les besoins de l’illustration. J’ai choisi de reprendre ici les mêmes que celle utilisée par Jon Swabish dans son livre ‘Better Data Visualizations’, les morts par overdoses aux Etats-Unis par type de substance. Je les ai trouver sur ourworldindata.org. Le premier jeu utilisé peut-être obtenu ici. Chargeons-le dans notre dossier de travail puis dans R.
dat <- read_csv("deaths-drug-overdoses.csv")## Rows: 6840 Columns: 7
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): Entity, Code
## dbl (5): Year, Deaths - Opioid use disorders - Sex: Both - Age: All Ages (Nu...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Le jeu de données comprend plus d’information que nécessaire. Limitons-le aux seules informations concernant les Etats-Unis à partir de l’année 2000. Profitons-en également pour renommer les variables pour avoir quelque chose de plus opérationnelle.
dat_<-dat %>% filter(Entity=='United States'&Year>1999) %>%
select(-Entity,-Code) %>%
rename(Opioide="Deaths - Opioid use disorders - Sex: Both - Age: All Ages (Number)",
Cocaine="Deaths - Cocaine use disorders - Sex: Both - Age: All Ages (Number)",
Autre="Deaths - Other drug use disorders - Sex: Both - Age: All Ages (Number)",
Amphetamine="Deaths - Amphetamine use disorders - Sex: Both - Age: All Ages (Number)")Commençons par établir la courbe des morts par overdose d’opioïdes sur la période. Procédons directement à une série de mise en forme pour rendre le graphe attractif (titre, soustritre captions…).
ggplot(dat_,aes(x=Year,y=Opioide))+
geom_line(color='red',linewidth=1)+
labs(title = "Nombre de décès par overdose d'Opioïde",
subtitle = "(par an aux Etats-Unis)",
caption = "Source: OurWorldinData.org")+
scale_x_continuous(breaks = 2000:2019,labels=c("2000",paste0("'",1:18),"2019"))+
scale_y_continuous(labels=label_number_auto())+
coord_cartesian(expand=FALSE,xlim=c(2000,2019.2),ylim=c(0,50000))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(face='italic',hjust=0.5),
plot.caption = element_text(face='italic',hjust=1),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank()
)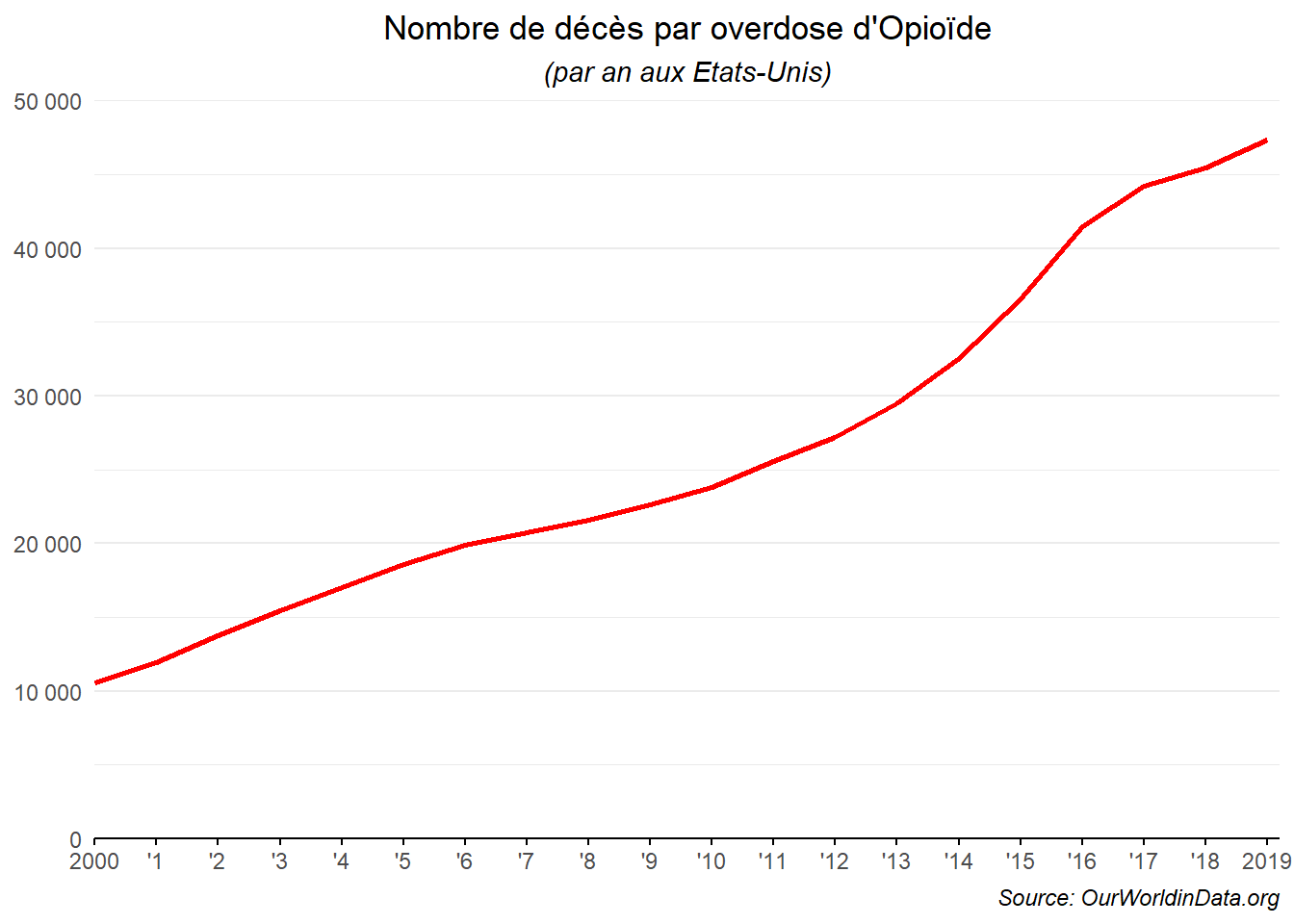
La courbe permet bien de rendre compte de l’évolution croissante du nombre de décès. Néanmoins, elle ne met pas en valeur le cumul de ceux-ci dans le temps. Sur la période, 525 910 individus sont morts d’overdose. Il s’agit simplement de la somme des distances entre le sommet de la courbe chaque année et l’axe des abscisses. Cette valeur est proportionnelle à l’aire sous la courbe. Celui-ci peut être mise ne évidence en utilisant le geom_aera().
ggplot(dat_,aes(x=Year,y=Opioide))+
geom_area(fill='red')+
labs(title = "Il y a eu 525 910 décès par overdose d'Opioïde entre 2000 et 2019.",
subtitle = "(par an aux Etats-Unis)",
caption = "Source: OurWorldinData.org")+
scale_y_continuous(labels=label_number_auto())+
scale_x_continuous(breaks = 2000:2019,labels=c("2000",paste0("'",1:18),"2019"))+
coord_cartesian(expand=FALSE,xlim=c(2000,2019.2))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(face='italic',hjust=0.5),
plot.caption = element_text(face='italic',hjust=1),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank()
)
Ici, faire commencer l’axe des ordonnées à 0 apparaît important (comme dans le cadre des diagrammes à bâtons). Cela permet de pleinement visualiser l’importance du phénomène illustré.
Le même type de graphe peut être mobilisé pour représenter la part de chaque type de substance (Opioïdes, Cocaïne, Amphétamines, Autres) dans le total des décès et son évolution au travers le temps. Il suffit de superposer les différentes surfaces correspondant aux décès générés par les différentes substances en veillant à ce que cette superposition ne cache aucune valeur si possible. Pour cela, nous commencerons par la substance la plus létale et finirons par la moins.
ggplot(dat_,aes(x=Year))+
geom_area(aes(y=Opioide,fill='Opioïdes'))+
geom_area(aes(y=Cocaine,fill='Cocaïnes'))+
geom_area(aes(y=Autre,fill='Autres'))+
geom_area(aes(y=Amphetamine,fill='Amphétamines'))+
labs(title = "715 201 personnes sont mortes d'overdose aux Etats-Unis
entre 2000 et 2019",
caption = "Source: OurWorldinData.org")+
scale_y_continuous(labels=label_number_auto())+
scale_x_continuous(breaks = 2000:2019,labels=c("2000",paste0("'",1:18),"2019"))+
scale_fill_manual(breaks = c("Opioïdes","Cocaïnes","Amphétamines","Autres"),
values = c( "red","blue","yellow","Magenta"))+
coord_cartesian(expand=FALSE,xlim=c(2000,2019.5))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.caption = element_text(face='italic',hjust=1),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.position = 'top',
legend.title = element_blank(),
legend.key.size = unit(5,"pt")
)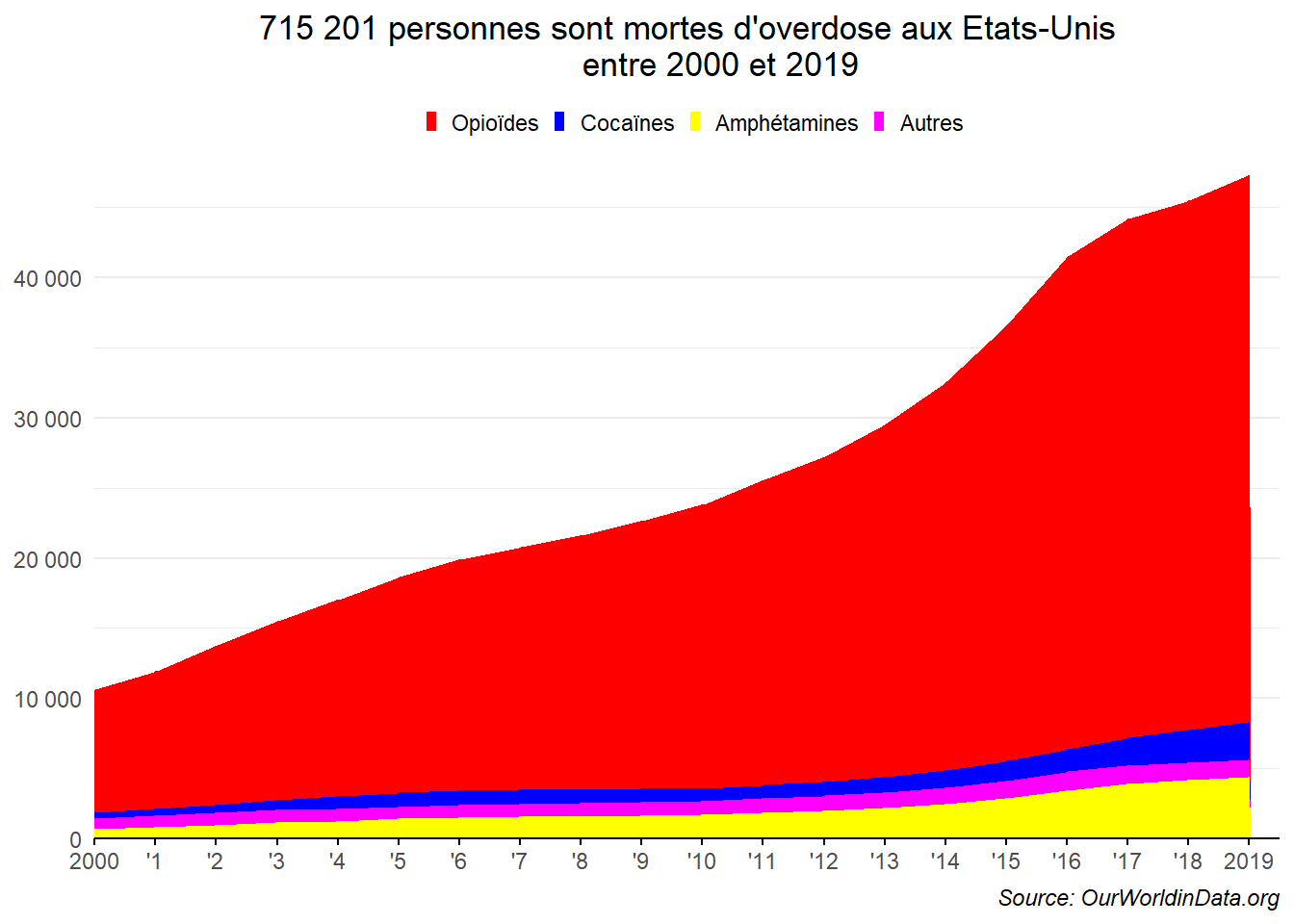
Le graphe est l’équivalent de celui que l’on aurait pour réaliser en utilisant les seules courbes. Néanmoins, cela met moins en avant le total des décès par overdose.
ggplot(dat_,aes(x=Year))+
geom_line(aes(y=Opioide,color='Opioïdes'),linewidth=1,show.legend = TRUE)+
geom_line(aes(y=Cocaine,color='Cocaïnes'),linewidth=1)+
geom_line(aes(y=Autre,color='Autres'),linewidth=1)+
geom_line(aes(y=Amphetamine,color='Amphétamines'),linewidth=1)+
labs(title = "715 201 personnes sont mortes d'overdose aux Etats-Unis
entre 2000 et 2019",
caption = "Source: OurWorldinData.org")+
scale_color_manual("",breaks = c("Opioïdes","Cocaïnes","Amphétamines","Autres"),
values = c( "red","blue","yellow","Magenta")) +
scale_y_continuous(labels=label_number_auto())+
scale_x_continuous(breaks = 2000:2019,labels=c("2000",paste0("'",1:18),"2019"))+
coord_cartesian(expand=FALSE,xlim=c(2000,2019.5),ylim=c(0,50000))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.caption = element_text(face='italic',hjust=1),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.position = 'top'
)
Cette représentation trouve ces limites lorsque les courbes délimitant le sommet des aires illustrant les valeurs.
Pour l’illustrer, prenons un nouveau jeu de données qui cette fois est centré sur l’importance des différents types d’opioïdes dans les overdoses entraînant la mort et celle de la cocaïne (toujours aux Etats-Unis sur la même période). Ce jeu est à nouveau tiré de OurWoldinData. Vous les trouverez ici. Chargeons-les dans le dossier de travail et importons les dans R.
dat2 <- read_csv("drug-overdose-death-rates.csv")## Rows: 22 Columns: 8
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): Entity, Code
## dbl (6): Year, Any opioid death rates (CDC WONDER), Cocaine overdose death r...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Procédons à un peu de mise en forme de la data frame.
dat2<-dat2 %>% select(-Entity,-Code) %>%
rename(Opioide="Any opioid death rates (CDC WONDER)",
Cocaine="Cocaine overdose death rates (CDC WONDER)",
Heroine="Heroin overdose death rates (CDC WONDER)",
Synth_Opioide="Synthetic opioids death rates (CDC WONDER)",
Opioide_presc="Prescription Opioids death rates (US CDC WONDER)") %>%
filter(Year>1999)Notez qu’ici l’unité est différente des graphes précédents. On a des nombre de morts par centaines de milliers d’individus.Limitons-nous à une comparaison entre les ravages de la cocaïne et celle de l’héroïne. Commençons par illustrer les séries au travers de courbes.
ggplot(data=dat2,aes(x=Year))+
geom_line(aes(y=Cocaine,colour="Cocaïne"))+
geom_line(aes(y=Heroine,colour="Heroïne"))+
labs(title = "Décés par overdose aux Etats-Unis",
subtitle = "(nombre de morts pour 100 mille individus)",
caption = "Source: OurWorldinData.org")+
scale_x_continuous(breaks = 2000:2020,labels=c("2000",paste0("'",1:19),"2020"))+
scale_colour_manual(breaks = c("Cocaïne", "Heroïne"),
values = c("blue", "red")) +
coord_cartesian(expand=FALSE,xlim=c(2000,2020.2),ylim=c(0,6))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(face='italic',hjust=0.5),
plot.caption = element_text(face='italic',hjust=1),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.position = 'top',
legend.title = element_blank(),
)
On note un tendance globale à la hausse sur les deux séries. Néanmoins, on a trois périodes distinctes qui se dessinent : entre 2000 et 2010 la cocaïne tue plus que l’héroïne, puis à partir de 2010 on a le schéma inverse, et pour finir, à partir de 2018 on revient à l’équilibre précédent. Si on passe l’ensemble en aires, on perd une partie de l’information.
ggplot(data=dat2,aes(x=Year))+
geom_area(aes(y=Cocaine,fill="Cocaine"))+
geom_area(aes(y=Heroine,fill="Heroine"))+
labs(title = "Décès par overdose aux Etats-Unis",
subtitle = "(nombre de morts pour 100 mille individus)")+
scale_x_continuous(breaks = 2000:2020,labels=c("2000",paste0("'",1:19),"2020"))+
scale_fill_manual(breaks = c("Cocaine", "Heroine"),
values = c("blue", "red")) +
coord_cartesian(expand=FALSE,xlim=c(2000,2020.2))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(face='italic',hjust=0.5),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.position = 'top',
legend.title = element_blank(),
legend.key.size = unit(5,"pt")
) 
Le niveau des décès associés à la cocaïne est caché par celui associé à l’héroïne entre 2011 et 2018. On peut y remédier en introduisant de la transparence dans les couleurs en utilisant l’option alpha.
ggplot(data=dat2,aes(x=Year))+
geom_area(aes(y=Cocaine,fill="Cocaine"),alpha=0.5)+
geom_area(aes(y=Heroine,fill="Heroine"),alpha=0.5)+
labs(title = "Morts par overdose aux Etats-Unis",
subtitle = "(nombre de morts pour 100 mille individus)")+
scale_x_continuous(breaks = 2000:2020,labels=c("2000",paste0("'",1:19),"2020"))+
scale_fill_manual(breaks = c("Cocaine", "Heroine"),
values = c("blue", "red")) +
coord_cartesian(expand=FALSE,xlim=c(2000,2020.3))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(face='italic',hjust=0.5),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.position = 'top',
legend.title = element_blank(),
legend.key.size = unit(5,"pt")
) 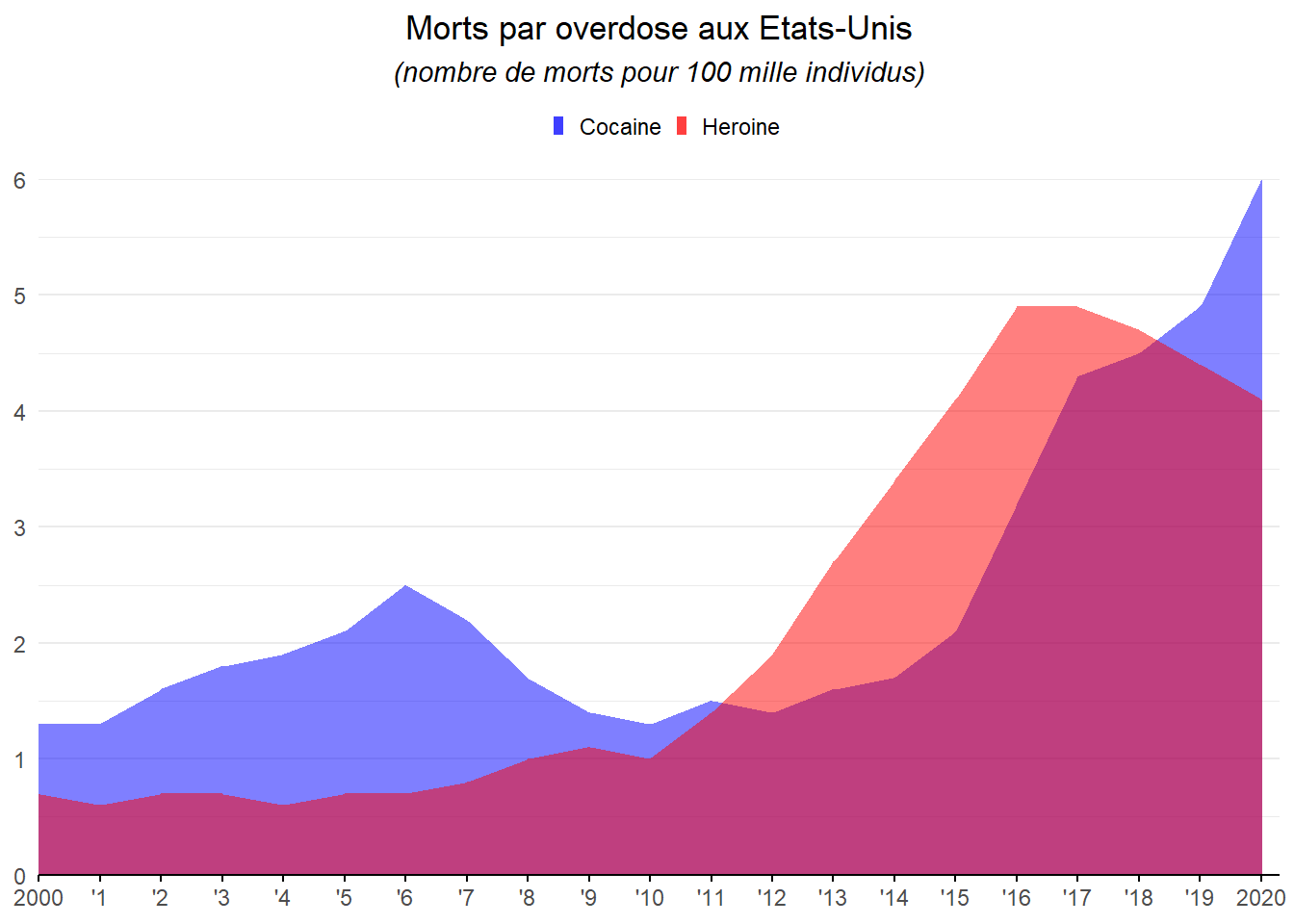
On retrouve l’information et la superposition des couleurs permet la mise en avant de cette période particulière.
Une autre application des graphes en aires consiste à empiler les données à la manière d’un diagramme à bâtons empilés. On peut le pratiquer comme nous l’avons fait avec les valeurs classiques ou de manière à remplir le repaire pour marquer les 100%.
Pour illustrer cela, reprenons notre premier jeu de données. Passons les valeurs en pourcentages du nombre de décès par overdose par an.
dat_s<-dat_ %>%
mutate(tot=Opioide+Cocaine+Autre+Amphetamine,
perc_Op=Opioide/tot,
perc_Coc=Cocaine/tot,
perc_Aut=Autre/tot,
perc_Amph=Amphetamine/tot)Commençons par empiler les valeurs indépendamment à la manière de ce que l’on a fait avec les valeurs brutes.
ggplot(data=dat_s,aes(x = Year))+
geom_area(aes(y=perc_Op,fill="Opioïdes"))+
geom_area(aes(y=perc_Coc,fill="Cocaïnes"))+
geom_area(aes(y=perc_Aut,fill="Autres"))+
geom_area(aes(y=perc_Amph,fill="Amphétamines"))+
labs(title = "Décès par overdose aux Etats-Unis")+
scale_x_continuous(breaks = 2000:2019,labels=c("2000",paste0("'",1:18),"2019"))+
scale_y_continuous(labels=label_percent())+
scale_fill_manual(breaks = c("Opioïdes","Cocaïnes","Amphétamines","Autres"),
values = c( "red","blue","yellow","Magenta")) +
coord_cartesian(expand=FALSE,xlim=c(2000,2019.3))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(face='italic',hjust=0.5),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.position = 'top',
legend.title = element_blank(),
legend.key.size = unit(5,"pt")
) 
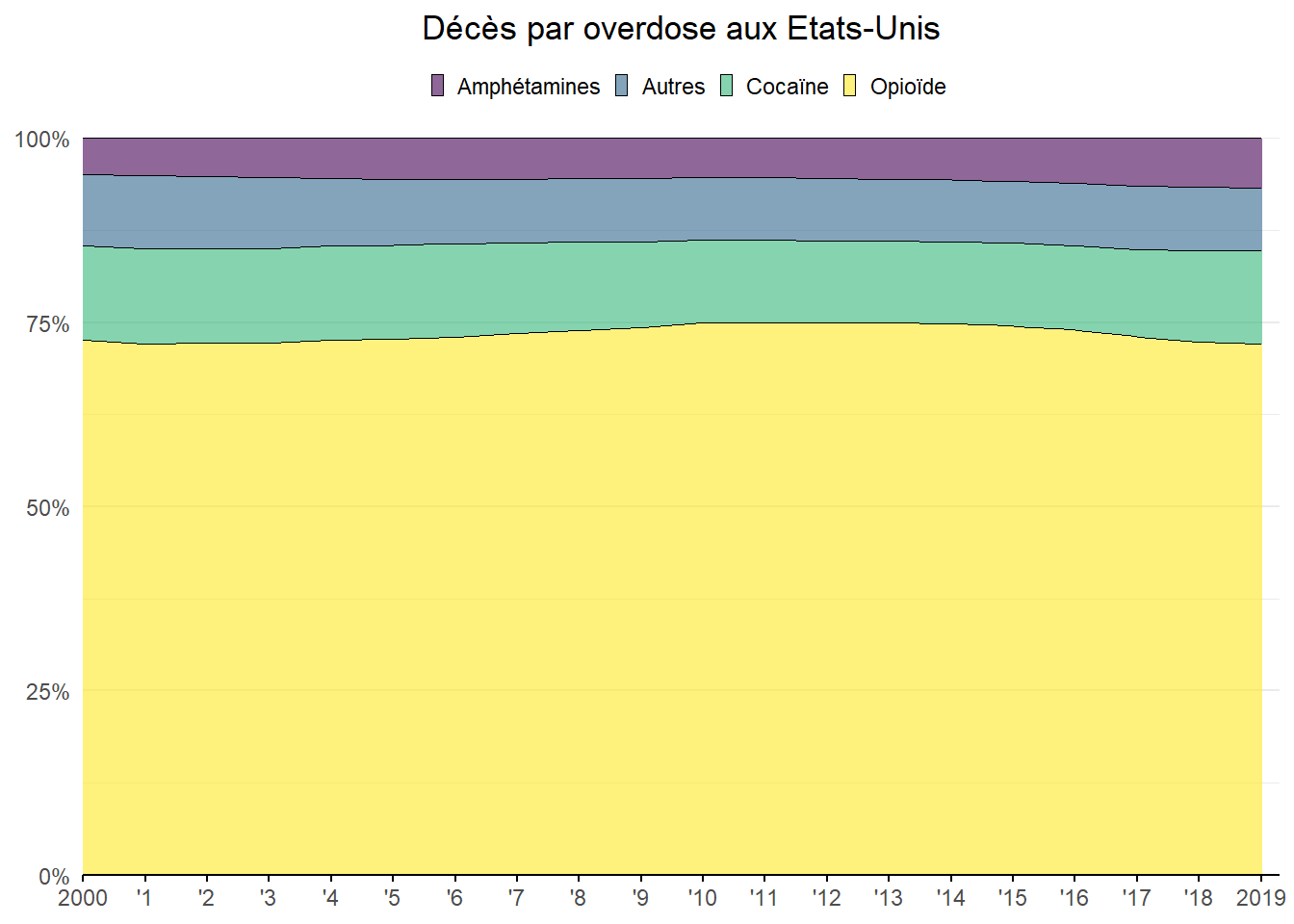
Le graphe obtenu permet bien de lire les proportions mais on peut faire mieux pour établir les comparaison en les empilant pour obtenir un total annuel égal à 100%. Pour cela, transformons notre base en utilisant la fonction pivot_longer(). L’idée est d’obtenir une variable indiquant la catégorie de substance considérée et une autre contenu les pourcentages associés et ceux pour chaque observation annuelle.
dat_s_<-dat_s %>% pivot_longer(cols=c(perc_Op,perc_Coc,perc_Aut,perc_Amph),
names_to = 'group',
values_to = 'pers') Une fois les données mises en forme, il suffit d’indiquer en esthétique (eas()) la variable définissant les groupes en couleur de remplissage (fill) et celle indiquant les pourcentage en ordonnées (y).
ggplot(dat_s_, aes(x=Year, y=pers, fill=group)) +
geom_area(alpha=0.6 , linewidth=0.2, colour="black")+
labs(title = "Décès par overdose aux Etats-Unis")+
scale_x_continuous(breaks = 2000:2019,labels=c("2000",paste0("'",1:18),"2019"))+
scale_y_continuous(labels=label_percent())+
scale_fill_manual(values = c( "yellow","Magenta","blue","red"),
labels=c('Amphétamines','Autres','Cocaïne','Opioïde'))+
coord_cartesian(expand=FALSE,xlim=c(2000,2019.3))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(face='italic',hjust=0.5),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.position = 'top',
legend.title = element_blank(),
legend.key.size = unit(5,"pt"))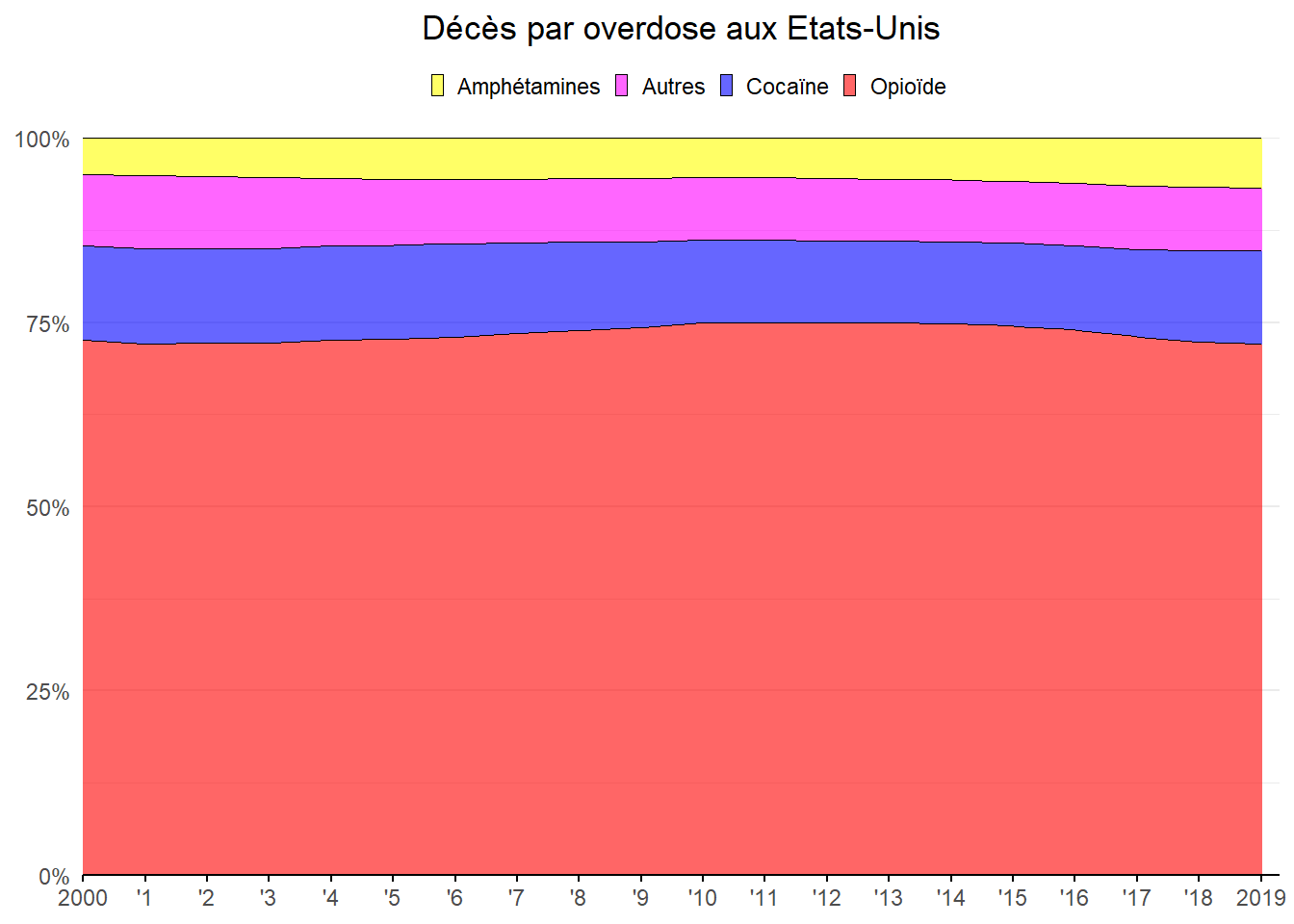
Le choix des couleurs pour les aires représenté peut un poser problème d’accessibilité pour les personnes daltoniennes. Pour y remédier, on peut utiliser un palette du packages viridis. Ici, la fonction utilisée est scale_fill_viridis_d() qui est la version discrète de la palette pour le remplissage.
ggplot(dat_s_, aes(x=Year, y=pers, fill=group)) +
geom_area(alpha=0.6 , linewidth=0.2, colour="black")+
labs(title = "Décès par overdose aux Etats-Unis")+
scale_x_continuous(breaks = 2000:2019,labels=c("2000",paste0("'",1:18),"2019"))+
scale_y_continuous(labels=label_percent())+
scale_fill_viridis_d(labels=c('Amphétamines','Autres','Cocaïne','Opioïde'))+
coord_cartesian(expand=FALSE,xlim=c(2000,2019.3))+
theme_minimal()+
theme(
plot.title = element_text(hjust=0.5),
plot.subtitle = element_text(face='italic',hjust=0.5),
axis.title = element_blank(),
axis.ticks.x.bottom = element_line(),
axis.line.x = element_line(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.position = 'top',
legend.title = element_blank(),
legend.key.size = unit(5,"pt"))