Pour ce nouveau post de la série GT, qui propose d’illustrer au travers de réalisations simples les différents types des graphes présentés par Jonathan Schwadish dans ses vidéos one chart at a time, nous nous allons revenir sur les diagrammes unitaires et leurs déclinaisons. Nous avions déjà traité d’un de ces graphes dans le post consacré aux dots plots (avec le diagramme de Wilkinson). Leur principe est simple. Il s’agit de mobiliser des formes (ou des symboles) pour figurer les observations ou des groupes d’observations. Le lecteur compte les formes (/symboles) pour inférer les valeurs représentées. Les graphes unitaires ont l’avantage d’être moins abstraits que les graphes classiques.
Dans le diagramme de Wilkinson, la distribution d’une variable est figurée par des empilements de disques. Leur nombre sur une valeur, ou sur un intervalle, informe sur l’effectif associé à cette valeur ou intervalle. Dans les graphes que nous allons travailler, les choses sont différentes. Nous nous focaliserons sur la représentation des parties d’un tout. A la manière d’un camembert (pie chart) où l’angle d’une part rend compte de l’importance d’une catégorie sur l’ensemble, les graphes unitaires que nous allons réaliser indiquent l’importance d’une catégorie par le nombre d’items de même forme et/ou de même couleur qui s’y rattache par rapport au nombre total d’items du graphe qui représente l’ensemble. Cette alternative apparaît plus rigoureuse que les camemberts. Elle ne souffre pas de la dissonance angle/surface typique de ces derniers. Nous en considérons de deux types les diagrammes en gauffre (Waffle chart) et les diagrammes isotypes. Pour les diagrammes en gaufre, les formes retenues sont des carrés articulés/empilés. Pour les diagrammes isotypes, ce sont des icones issues du système éponyme (international system of typographic pictures for education).
La principale règle de ces graphes est simple si une icône/un carré représente un individu alors deux icônes/carrés représente deux individus. Il n’est pas question ici de jouer sur la taille de ces éléments. Pour exprimer un nombre plus grand, on utilise un plus grand nombre de items. Ceux-ci doivent être choisi avec attention pour ne pas induire d’erreurs d’interprétation. Quand les quantités à représenter sont grandes un symbole peut représenter un grand nombre d’individus.
Pour illustrer l’utilisation de ces graphes, nous allons travailler sur le mix énergétique de la France pour l’année 2020. Les données sont extraites du site Our World in Data.
Commençons par charger les packages que nous allons utiliser. On y retrouve les classiques (tidyverse…), mais aussi un package particulier qu’il sera nécessaire d’installer à partir d’un répertoire différent du CRAN: le package waffle. Pour avoir la version la plus récente, exécuter la commande suivante:
install.packages("waffle",repos="https://cinc.rud.is")Vérifiez que la version installée est suffisamment avancée avec packcageVersion().
packageVersion("waffle")## [1] '1.0.1'Elle doit être supérieure à 1.0, ce qui est le cas ici.
library(readr)
library(tidyverse)
library(ggtext)
library(waffle)
library(showtext)Ceci fait, chargeons les données dans R. Nous avons au préalable déposé le fichier .csv correspondant charger à partir de Our World in Data dans le dossier de travail.
dat <- read_csv("energy-consumption-by-source-and-region.csv")## Rows: 5264 Columns: 12
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): Entity, Code
## dbl (10): Year, Biofuels Consumption - TWh - Total (zero filled), Solar Cons...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.glimpse(dat)## Rows: 5,264
## Columns: 12
## $ Entity <chr> "Africa", "Africa",…
## $ Code <chr> NA, NA, NA, NA, NA,…
## $ Year <dbl> 1965, 1966, 1967, 1…
## $ `Biofuels Consumption - TWh - Total (zero filled)` <dbl> 0, 0, 0, 0, 0, 0, 0…
## $ `Solar Consumption - TWh (zero filled)` <dbl> 0, 0, 0, 0, 0, 0, 0…
## $ `Wind Consumption - TWh (zero filled)` <dbl> 0, 0, 0, 0, 0, 0, 0…
## $ `Hydro Consumption - TWh (zero filled)` <dbl> 38.62676, 43.08334,…
## $ `Nuclear Consumption - TWh (zero filled)` <dbl> 0.00000, 0.00000, 0…
## $ `Gas Consumption - TWh (zero filled)` <dbl> 9.543754, 10.669916…
## $ `Coal Consumption - TWh (zero filled)` <dbl> 323.4961, 323.1222,…
## $ `Oil Consumption - TWh (zero filled)` <dbl> 327.3332, 358.1327,…
## $ `Geo Biomass Other - TWh (zero filled)` <dbl> 0.000, 0.000, 0.000…La base est très large. Limitons-la aux seules données que nous utiliserons.
dat <- dat %>% filter(Year==2020&Entity=='France') %>%
select(-Entity,-Code,-Year)Intégrons des noms de variables plus faciles à manipuler.
names(dat)<-c('Bio_carburant','Solaire','Eolienne','Hydro',
'Nucléaire','Gaz','Charbon','Pétrole','autre_biomass')Restructurons le base pour l’organiser en longueur et créons la variable gr reprenant les différents types d’énergie en regroupant au sein d’une seule catégorie les énergies renouvelables.
dat <- dat %>% pivot_longer(cols=names(dat),
names_to='Energie',
values_to='TW_h') %>%
mutate(gr=ifelse(Energie%in%c('Bio_carburant','Solaire',
'Eolienne','Hydro',
'autre_biomass'),
'Renouvelable',Energie)) Pour finaliser le travail de préparation des données, établissons la part des différentes énergies (gr) dans le mix.
dat_red <- dat %>% group_by(gr) %>%
summarise(TW_h_c=sum(TW_h)) %>%
ungroup() %>%
mutate(part=round(TW_h_c/sum(TW_h_c)*100,digits=2))
dat_red## # A tibble: 5 × 3
## gr TW_h_c part
## <chr> <dbl> <dbl>
## 1 Charbon 53.8 2.24
## 2 Gaz 407. 16.9
## 3 Nucléaire 873. 36.3
## 4 Pétrole 744. 31.0
## 5 Renouvelable 325. 13.5Maintenant que les données sont prêtes, nous pouvons travailler sur nos graphes. Commençons par un diagramme en gaufre classique. Pour cela, utilisons le geom_waffle() avec deux esthétiques les valeurs représentées (part) et les différentes énergies (gr) pour l’application des couleurs.
ggplot(data=dat_red,aes(values=part,fill=gr))+
geom_waffle()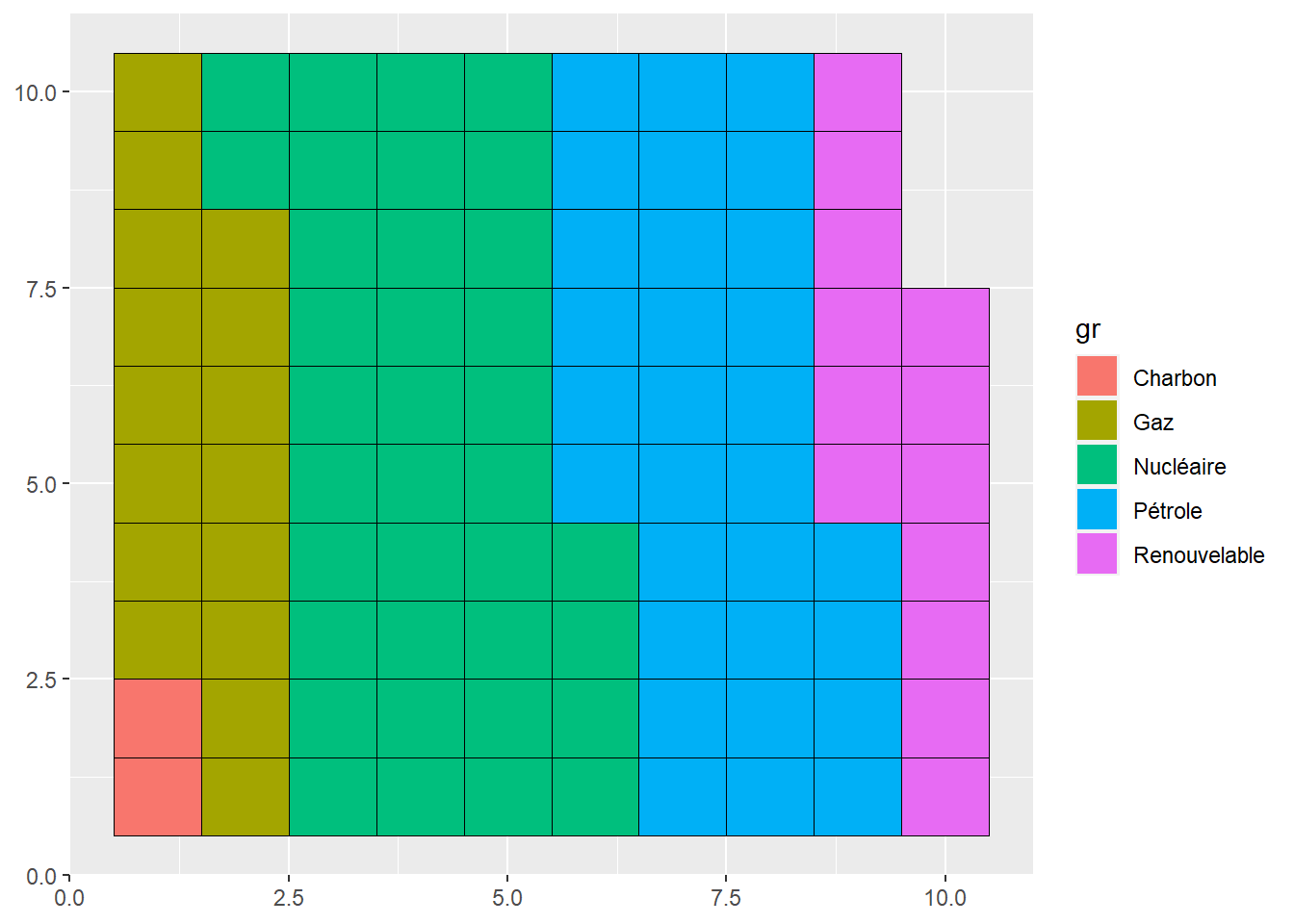
Le résultat de base peut être facilement amélioré en s’assurant que les éléments représentés prennent bien la forme de carrés et en adoptant un thème plus léger.
ggplot(data=dat_red,aes(values=part,fill=gr))+
geom_waffle()+
coord_equal()+
theme_void()
Pour rendre l’ensemble encore plus lisible, limitons le nombre de carrés par lignes à un maximum de 8, basculons le repère pour avoir le carré seul en haut, marquons la séparation entre les carrés par une ligne blanche assez épaisse et intégrons un léger arrondi sur les angles.
ggplot(data=dat_red,aes(values=part,fill=gr))+
geom_waffle(n_rows=8,flip=TRUE,colour='white',size=0.5,
radius=unit(3,'pt'))+
coord_equal()+
theme_void()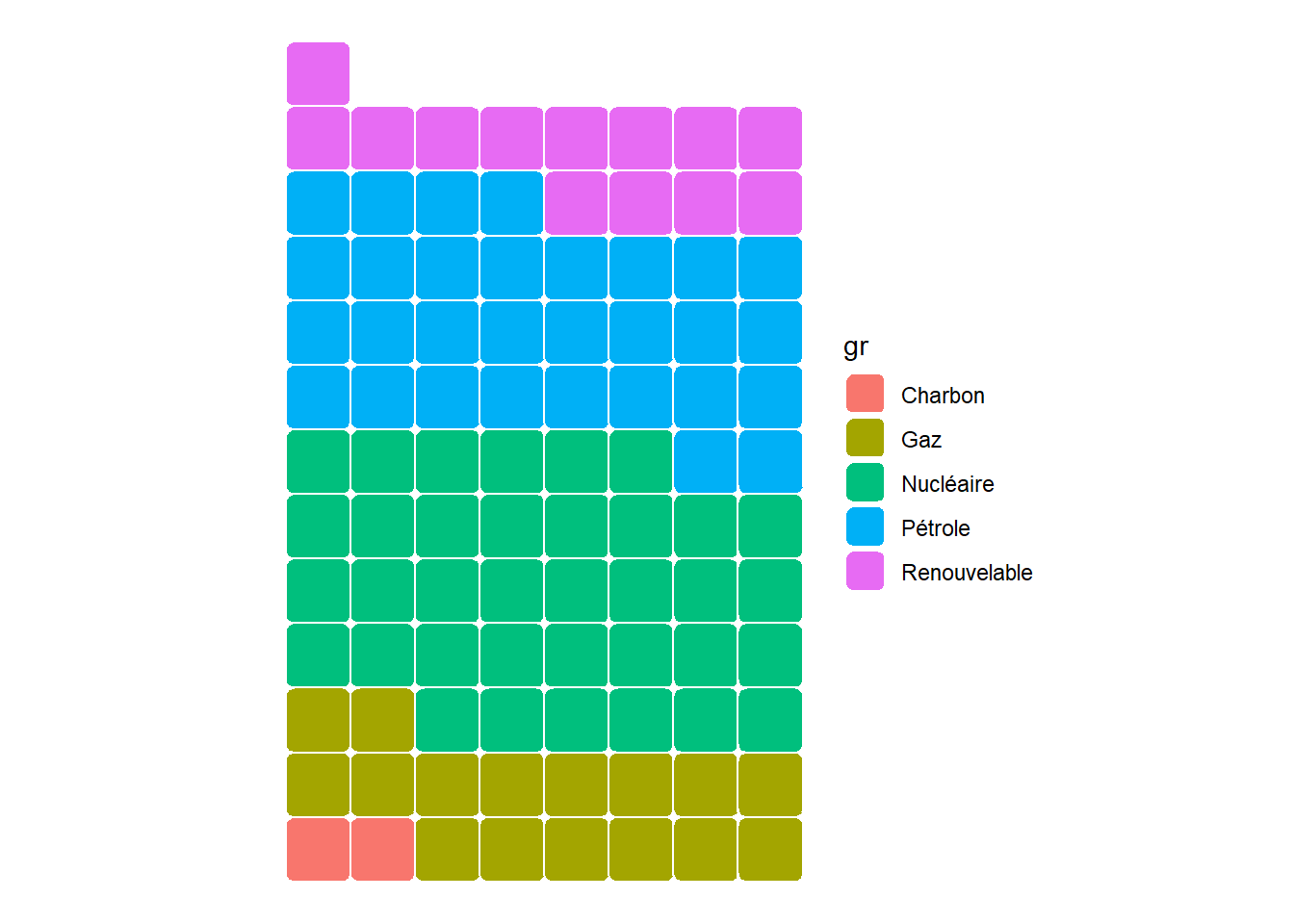
Ajoutons des éléments textuels pour expliciter l’ensemble: un titre, un sous-titre (indiquant la quantité totale d’énergie représenté en TWH et la quantité représentée par un carré), le titre de la légende. Procédons à une mise en forme pour renforcer les points importants et utilisons la police de caractère Montserrat proposée par google font.
font_add_google("Montserrat","Montserrat")
showtext_auto()
ggplot(data=dat_red,aes(values=part,fill=gr))+
geom_waffle(n_rows=8,flip=TRUE,colour='white',size=0.5,
radius=unit(3,'pt'))+
labs(title = "Mix énergétique en *2020* pour **France** <img src='drapeau.png',
width='10'/>",
subtitle = "(Total de *2 402,24 TWh* - un carré représente *24,76 TWh*)",
caption = "Source: Statistical Review of World Energy via Our World in Data",
fill='Energie')+
coord_equal()+
theme_void()+
theme(text=element_text(family = "Montserrat"),
plot.title = element_markdown(size=24),
plot.subtitle = element_markdown(size=14),
plot.caption = element_text(face = 'italic',hjust=1,size=12),
legend.title = element_text(size=14),
legend.text = element_text(size=12))
Les couleurs attribuées par défaut paraissent ici assez inadéquate. On a du vert pour le gaz et le nucléaire et du violet pour les énergies renouvelables. Changeons cela pour avoir du gris foncé pour le charbon, du gris plus clair pour le gaz, du jaune pour le nucléaire, du bleu foncé pour le pétrole et du vert pour les renouvelables. Pour ce faire, utilisons scale_fill_manual().
ggplot(data=dat_red,aes(values=part,fill=gr))+
geom_waffle(n_rows=8,flip=TRUE,colour='white',size=0.5,
radius=unit(3,'pt'))+
labs(title = "Mix énergétique en *2020* pour **France** <img src='drapeau.png',
width='10'/>",
subtitle = "(Total de *2 402,24 TWh* - un carré représente *24,76 TWh*)",
caption = "Source: Statistical Review of World Energy via Our World in Data",
fill='Energie')+
scale_fill_manual(values=c('DimGray','grey','Gold','MidnightBlue',
'MediumSpringGreen'))+
coord_equal()+
theme_void()+
theme(text=element_text(family = "Montserrat"),
plot.title = element_markdown(size=24),
plot.subtitle = element_markdown(size=14),
plot.caption = element_text(face = 'italic',hjust=1,size=12),
legend.title = element_text(size=14),
legend.text = element_text(size=12))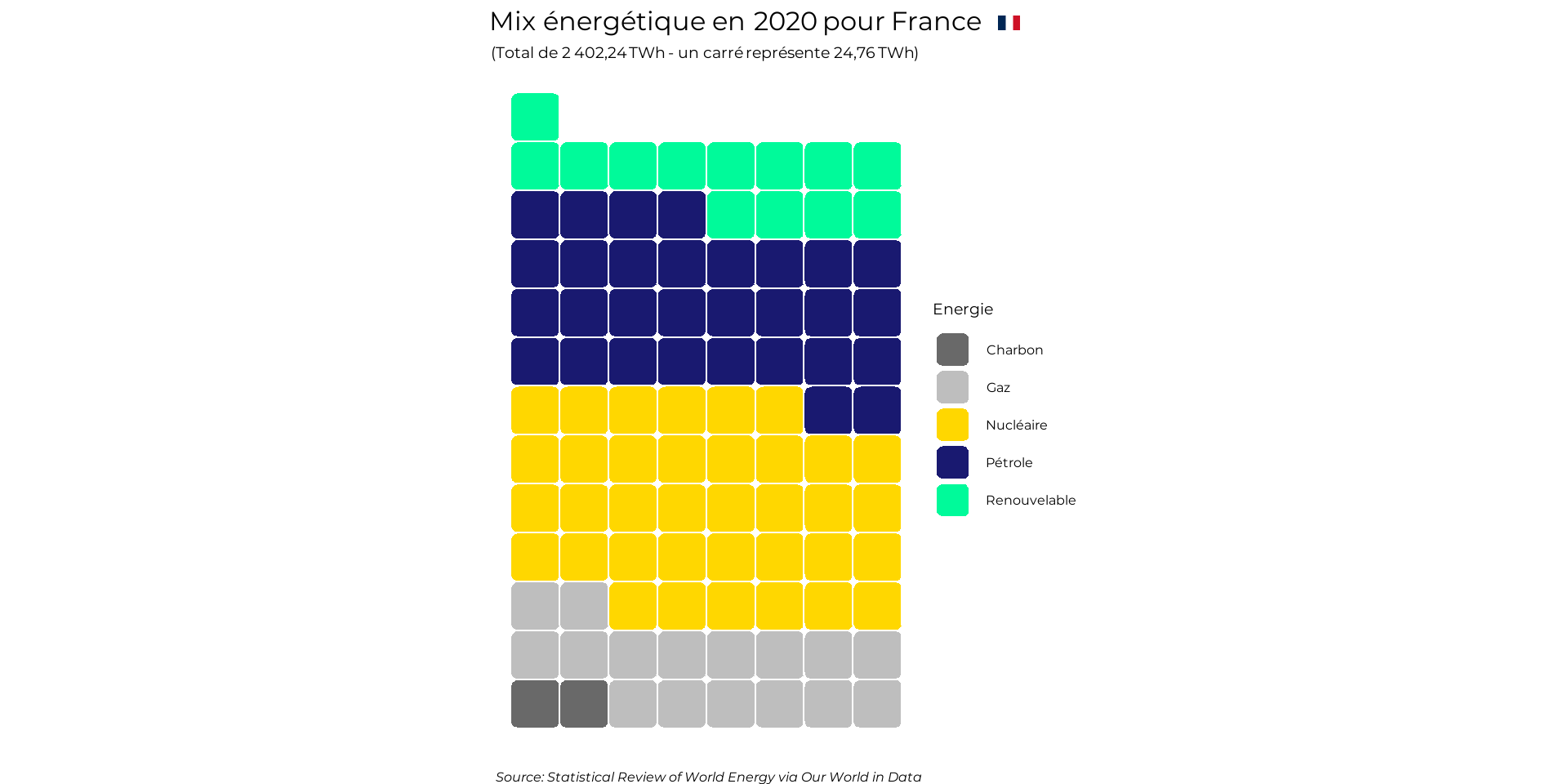
Cela nous donne un diagramme simple est expressif. L’empilement des carrés permet d’avoir à la fois l’information sur le total de l’énergie consommée et le détail par type d’énergie.
On peut sur le même modèle envisager de présenter les groupes de carrés sous une forme non empilée en utilisant la commande facet_wap(). Mettons les sur une ligne et assurons-nous que l’étiquette des catégories soit sous les blocs. Faisons également sauter la légende qui ne sert plus à rien.
ggplot(data=dat_red,aes(values=part,fill=gr))+
geom_waffle(n_rows=8,flip=TRUE,colour='white',size=0.5,
radius=unit(3,'pt'))+
facet_wrap(~gr,nrow = 1,strip.position = 'bottom')+
labs(title = "Mix énergétique en *2020* pour **France** <img src='drapeau.png',
width='10'/>",
subtitle = "(Total de *2 402,24 TWh* - un carré représente *24,76 TWh*)",
caption = "Source: Statistical Review of World Energy via Our World in Data")+
scale_fill_manual(values=c('DimGray','grey','Gold','MidnightBlue',
'MediumSpringGreen'))+
coord_equal()+
theme_void()+
theme(text=element_text(family = "Montserrat"),
plot.title = element_markdown(size=24),
plot.subtitle = element_markdown(size=18),
plot.caption = element_text(face = 'italic',hjust=1,size=14),
legend.position='none',
strip.text=element_text(size=14))
Une autre alternative à notre diagramme en gaufres empilés consiste à utiliser des icones à la place des carrés. Le graphe devient alors isotype. Pour ce faire, il est nécessaire au préalable de télécharger une série de polices d’écriture complémentaires. Il s’agit des polices Awesome qui sont gérées par le package waffle. Vous les trouverez en suivant les liens suivant:
Une fois charger, appelons-les dans notre environnement de travail. Profitons-en pour en faire autant avec une nouvelle police google, la police Nunito.
font_add_google("Nunito","Nunito")
font_add(family="FontAwesome5Free-Solid",
regular='fa-solid-900.ttf')
font_add(family="FontAwesome5Free-Regular",
regular='fa-regular-400.ttf')
font_add(family="FontAwesome5Brands-Regular",
regular='fa-brands-400.ttf')
showtext_auto()Vous pouvez chercher les icônes à retenir en utilisant l’applet associée. Celle-ci est mobilisée en saisissant fa_list() dans la console. Nous retenons ici une montagne pour le charbon (cela rappel les terriles), une flamme pour gaz, un symbole radiation pour le nucléaire, une pompe à essence pour le pétrole, et un arbre pour les énergies renouvelables. Elles sont introduites par le geom_pictogram() et les esthétiques label et color. Leur liste est précisée dans une échelle dédiée scale_label_pictogram().
ggplot(data=dat_red,aes(values=part,label=gr,color=gr))+
geom_pictogram(n_rows=8,flip=TRUE)+
labs(title = "Mix énergétique en *2020* pour **France** <img src='drapeau.png',
width='10'/>",
subtitle = "(Total de *2 402,24 TWh* - un carré représente *24,76 TWh*)",
caption = "Source: Statistical Review of World Energy via Our World in Data",
label='Energie',color='Energie')+
scale_label_pictogram(values=c('mountain','fire-alt','radiation',
'gas-pump','tree'))+
scale_color_manual(values=c('DimGray','grey','Gold','MidnightBlue',
'MediumSpringGreen'))+
coord_equal()+
theme_void()+
theme(text=element_text(family = "Nunito"),
plot.title = element_markdown(size=24),
plot.subtitle = element_markdown(size=14),
plot.caption = element_text(face = 'italic',hjust=1,size=12),
legend.title = element_text(size=14),
legend.text = element_text(size=12))
Ce nouveau graphe est, je pense, le plus parlant des trois. De nombreuses variations peuvent être envisagées en jouant sur les icônes, leurs couleurs, leur nombre sur une ligne, leur empilement ou non, etc. Utiliser des éléments autres que les formes classiques (points, courbes, lignes, barres) ouvre un champs d’outils de communications importants. Ils faudra néanmoins veiller à rester rigoureux pour ne pas déformer l’information transmisse par le graphe.