Jusqu’à maintenant, nous nous sommes concentré sur des diagrammes reposant sur l’exploitation d’un même type de formes géométriques: les barres (ou les bâtons). Dans ce nouveau post de la série GT, nous allons continuer à nous intéresser à la représentation de variables qualitatives dans un but de description ou de comparaison, mais cette fois nous mobiliserons une autre forme: le point. En anglais, on parlera de dot plot.
Le premier a avoir été utilisé est très proche du simple diagramme à bâtons. Il s’agit d’un empilement de points servant à matérialiser les effectifs des différentes valeurs d’une variable (discrète ou continue découpée en intervalles). Il permet d’avoir une image rapide et possiblement élégante de la distribution de cette dernière. Ce type de représentation doit néanmoins être réservé à des bases comprenant un nombre d’observation relativement réduite pour ne pas apparaître illisible.
Pour illustrer, l’ensemble de ces considérations, prenant un ensemble de données portant sur le tabagisme dans les différents pays composant l’OCDE en 2019. Celles-ci sont téléchargeables à l’adresse suivante: https://doi.org/10.1787/888934015277. Mais avant d’aller plus loin, chargeons les différents packages que nous utiliserons par la suite.
library(tidyverse)
library(readxl)
library(ggtext)
library(showtext)Ceci fait, Chargeons les données et pratiquons quelques opérations de mise en forme (traduisons en français le nom des pays et marquons ceux appartenant à l’OCDE). Puis, jetons un œil à l’ensemble.
dat<- read_excel("ELS-2019-5047-EN-G049.XLSX", skip = 25, n_max = 45) %>%
rename(country=...1)
pays<-c('Costa Rica','Mexique','Islande','Brésil','Suède','Etats Unis',
'Inde','Norvège','Canada','Australie','Colombie','Nouvelle-Zélande',
'Finlande','Luxembourg','Portugal','Pays-Bas','Danemark','Israel',
'Irlande','Royaume-Uni','Estonie','Corée du Sud','Japon','OCDE (36)',
'République Tchéque','Allemagne','Belgique','Slovénie','Afrique du Sud',
'Suisse','Italie','Lituanie','Espagne','Pologne','République Slovaque',
'Lettonie','Autriche','Chili','Chine','France','Hongrie','Turquie',
'Grèce','Russie','Indonésie')
OCDE<-c(1,1,1,0,1,1,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,NA,1,1,1,1,0,1,1,1,1,1,1,1,1,1,
0,1,1,1,1,0,0)
dat<-data.frame(dat,pays,OCDE)
head(dat)## country ...2 Total Men Women pays OCDE
## 1 Costa Rica NA 4.73297 6.1862 3.21346 Costa Rica 1
## 2 Mexico NA 7.60000 12.0000 3.60000 Mexique 1
## 3 Iceland 2018 8.60000 8.1000 9.10000 Islande 1
## 4 Brazil NA 10.10000 13.2000 7.50000 Brésil 0
## 5 Sweden NA 10.40000 10.5000 10.30000 Suède 1
## 6 United States NA 10.50000 11.5000 9.50000 Etats Unis 1Maintenant que nous avons des données, établissons un graphe en points pour décrire la distribution de la proportion de fumeur.ses dans les différents pays de la base (la variable Total). Pour cela, utilisons le geom_dotplot().
ggplot(filter(dat,is.na(OCDE)==FALSE),aes(x = Total)) +
geom_dotplot()## Bin width defaults to 1/30 of the range of the data. Pick better value with
## `binwidth`.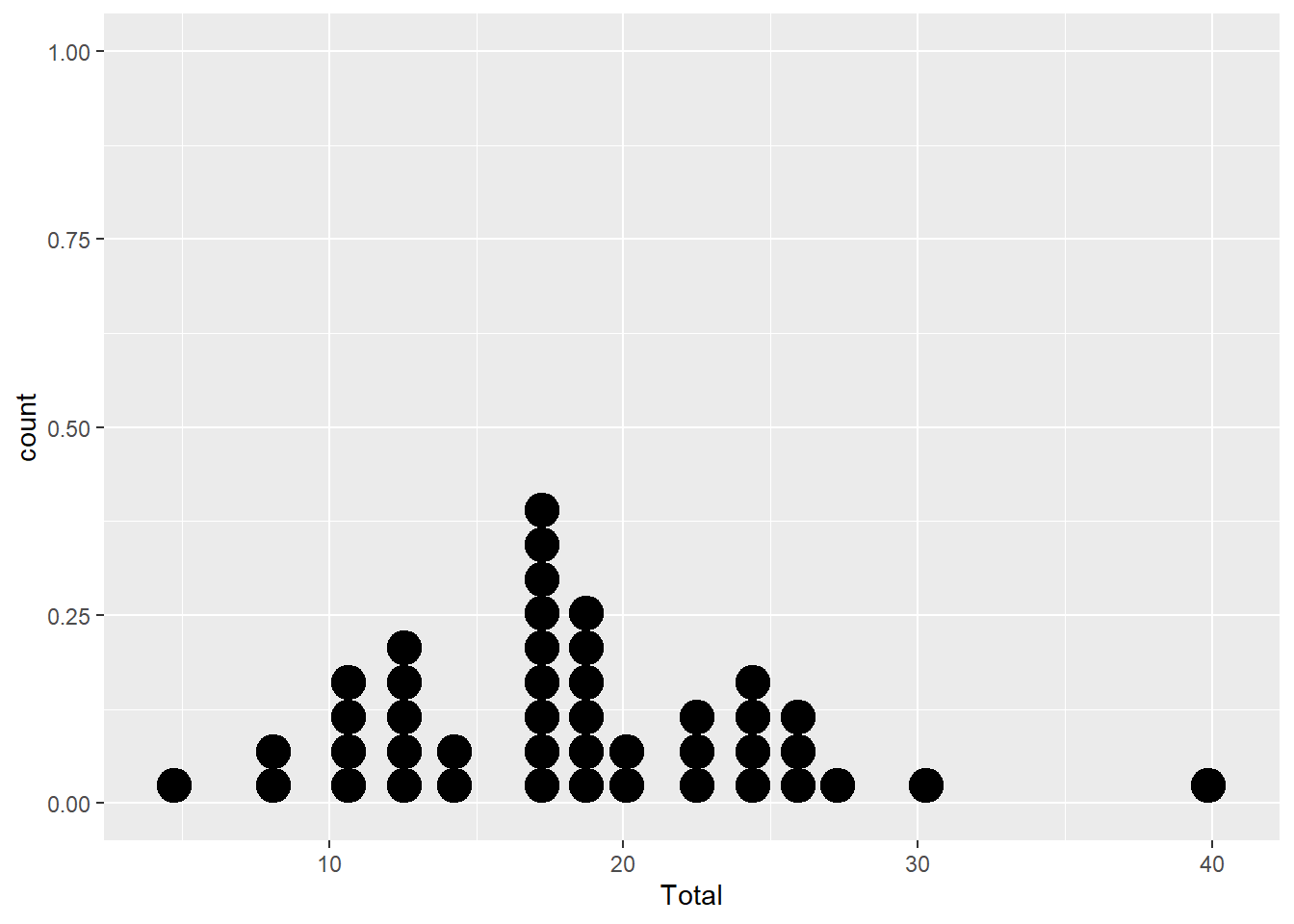 Nous avons exclu de la représentation la moyenne de l’OCDE pour ne garder que les pays. La graphe obtenu est très proche d’un simple diagramme à bâtons. Il permet néanmoins de compter le nombre de pays (de points) regroupés dans les différentes catégories (regroupement en classe de ici le nombre de classe a été fixé arbitrairement à 30 cela peut être modifier par l’option binwidth).
Nous avons exclu de la représentation la moyenne de l’OCDE pour ne garder que les pays. La graphe obtenu est très proche d’un simple diagramme à bâtons. Il permet néanmoins de compter le nombre de pays (de points) regroupés dans les différentes catégories (regroupement en classe de ici le nombre de classe a été fixé arbitrairement à 30 cela peut être modifier par l’option binwidth).
Essayons d’améliorer le résultat obtenu à l’aide de quelques mise en forme. Supprimons l’axe des ordonnées qui ne sert pas à grand chose. Remettons en forme celui des abscisses en en changeant le titre pour quelque chose de plus signifiant et en en revoyant la gradation. Choisissons un thème plus discret et effaçons le quadrillage à l’arrière. Ajoutons un caption pour indiquer l’origine des données.
ggplot(filter(dat,is.na(OCDE)==FALSE),
aes(x = Total)) +
geom_dotplot()+
labs(x='Pourcentage de fumeur.ses <br> sur un échantillon de 44 pays <br> OCDE, Brésil, Inde, Afrique du Sud, Chine, Russie, Indonésie',
caption="Source: OCDE données de santé 2019")+
scale_x_continuous(breaks=seq(5,40,5))+
theme_minimal()+
theme(axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.title.x = element_markdown(),
panel.grid = element_blank(),
plot.caption = element_text(face='italic'))## Bin width defaults to 1/30 of the range of the data. Pick better value with
## `binwidth`.
On rendre l’ensemble plus informatif en jouant sur les couleurs par exemple de manière à mettre en relief un ou plusieurs groupes (de points). Ici, contentons-nous, sur les pays et distinguons ceux qui font ou non partie de l’OCDE. Mettons en vert (#E72689) les points correspondants à des pays de l’OCDE et en rose (#A5D57F) ceux qui n’en font pas partie. Profitons-en pour réarranger l’ensemble pour obtenir un résultat plus esthétique.
ggplot(filter(dat,is.na(OCDE)==FALSE),
aes(x = Total,fill = factor(OCDE))) +
geom_dotplot(color='dark grey')+
labs(title = "Pourcentage de fumeur.ses <br> sur un échantillon de 44 pays <br> <br> <span style=color:'#E72689'>**OCDE**</span> ,<span style=color:'#A5D57F'> **Brésil**</span>,<span style=color:'#A5D57F'> **Inde**</span>,<span style=color:'#A5D57F'> **Afrique du Sud**</span>, <span style=color:'#A5D57F'> **Chine**</span>, <span style=color:'#A5D57F'> **Russie**</span>, <span style=color:'#A5D57F'> **Indonésie**</span>",caption="Source: OCDE données de santé 2019")+
scale_fill_manual(values=c('#E72689','#A5D57F'),
labels=c("pays hors OCDE","pays de l'OCDE"))+
scale_x_continuous(breaks=seq(5,40,5))+
theme_minimal()+
theme(axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.title.x = element_blank(),
panel.grid = element_blank(),
plot.title = element_markdown(hjust=0.5),
plot.caption = element_text(face='italic'),
legend.position='none')## Bin width defaults to 1/30 of the range of the data. Pick better value with
## `binwidth`.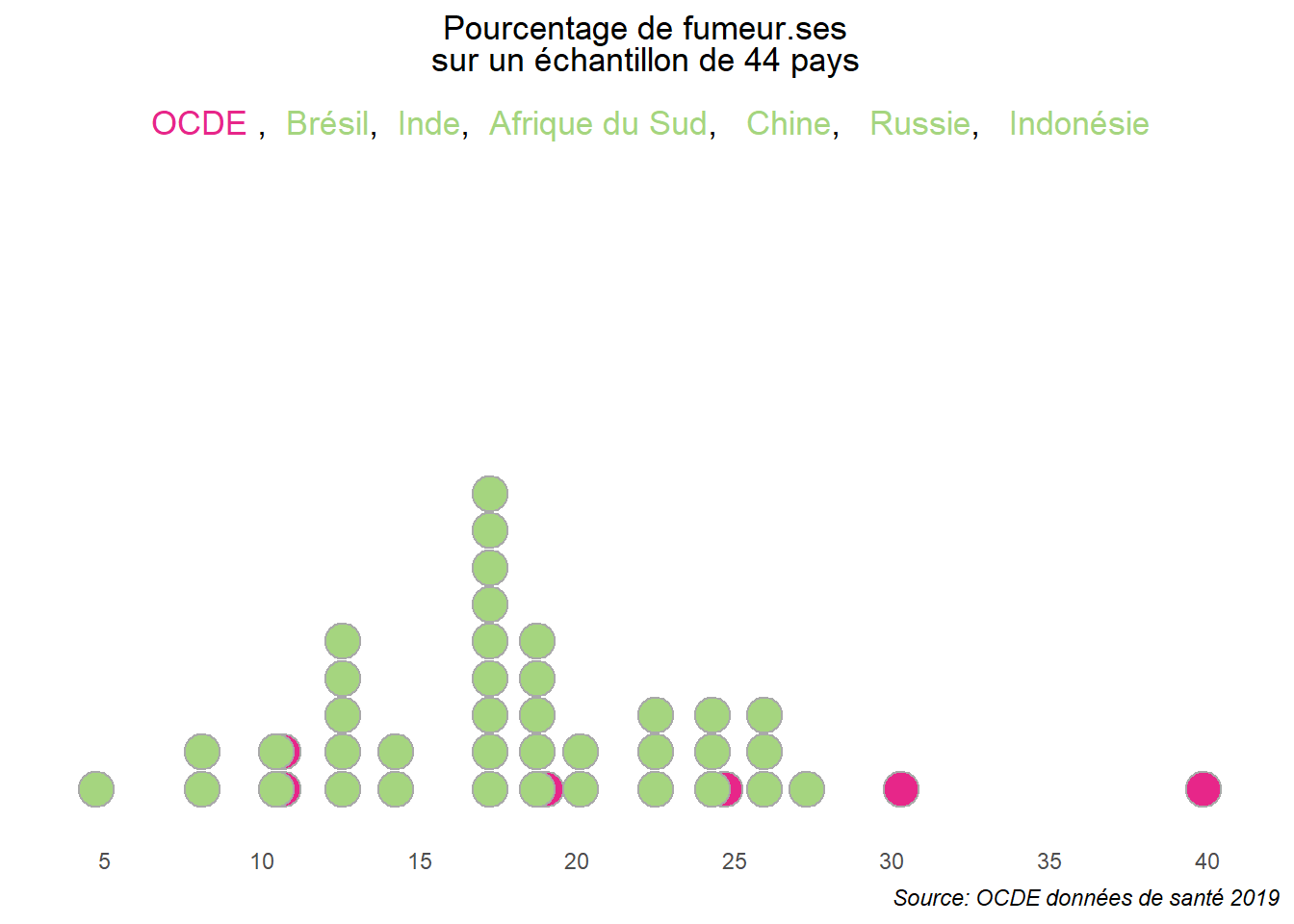
Ces graphes permettant de présenter les distributions à l’aide de points sont souvent désigné comme des diagrammes de Wilkinson (Wilkison dot plot). Ils peuvent connaître de nombreuses déclinaisons sur lesquels nous reviendrons à l’occasion.
Mais attardons-nous, sur une des plus populaires en ce moment : le diagramme en points de Cleveland (Cleveland dot plot). Il s’agit simplement d’une série de points dont la position correspond à l’extrémité des barres d’un diagramme à bâtons et dans lesquels sont indiqués les valeurs représentées.
Prenons un exemple rapide pour illustrer ce nouveau graphe. Représentons la proportion de fumeur dans les pays de l’échantillon ne faisant pas partie de l’OCDE et ka proportion moyenne dans les pays de l’OCDE. Préparons les données.
red<-filter(dat,is.na(OCDE)==FALSE) %>%
mutate(de=ifelse(OCDE==1,"OCDE",pays)) %>%
group_by(de) %>%
summarise(fum=mean(Total)) %>%
mutate(ocd=de=='OCDE') Commençons par établir le classique diagramme à bâtons (avec quelques mise en forme).
ggplot(red)+
aes(x=de,y=fum,fill=ocd)+
geom_bar(stat='identity',width=0.25)+
labs(y='%',
caption="Source: OCDE données de santé 2019")+
coord_cartesian(ylim=c(0,50))+
theme_minimal()+
theme(axis.title.x = element_blank(),
axis.title.y = element_text(angle=180,vjust=0.5),
panel.grid = element_blank(),
plot.caption = element_text(face='italic'),
legend.position = 'none')
Comparons-le avec un diagramme de Cleveland construit à partir des mêmes données. Pour cela, utilisons cette fois le geom_point() couplé avec le geom_text(). Dimensionnons le points de manière à ce qu’ils puissent contenir un texte lisible. Jouons légèrement sur leur transparence (alpha) pour rendre les couleurs plus pastelles.
ggplot(red)+
aes(x=de,y=fum,color=ocd)+
geom_point(size=15,alpha=0.5)+
geom_text(aes(label=round(fum)),color='black')+
labs(y='%',
caption="Source: OCDE données de santé 2019")+
coord_cartesian(ylim=c(0,50))+
theme_minimal()+
theme(axis.title.x = element_blank(),
axis.title.y = element_text(angle=180,vjust=0.5),
panel.grid = element_blank(),
plot.caption = element_text(face='italic'),
legend.position = 'none')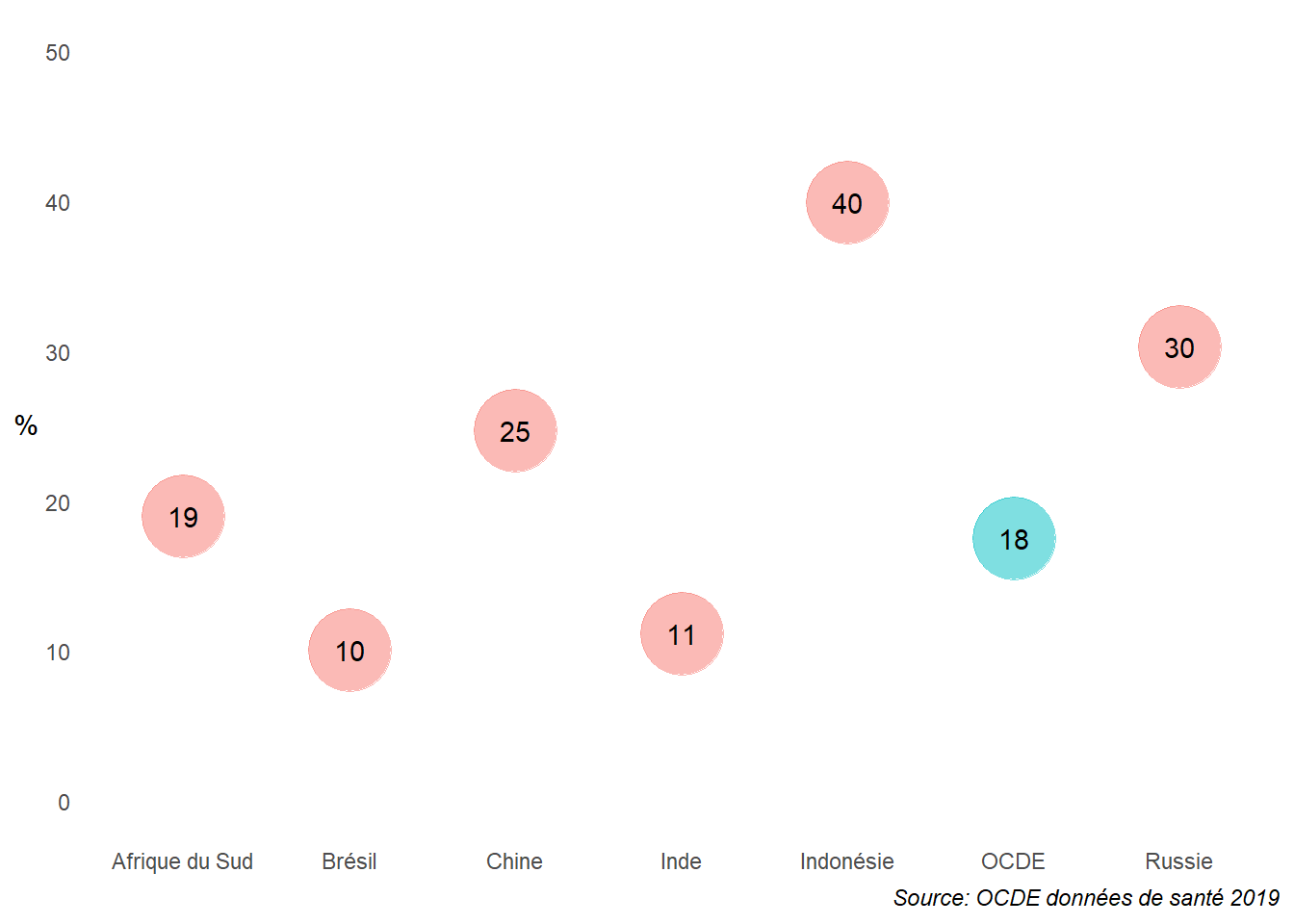
On a notre diagramme de Cleveland. Mais, il peut encore être améliorer. Avec les valeurs étant indiquées dans les points, nous n’avons pas réellement besoin de l’axe des ordonnées. Supprimons-le. Profitons-en pour ajouter une ligne verticale pour chaque pays de manière à rendre la lecture plus facile.
ggplot(red)+
aes(x=de,y=fum,color=ocd)+
geom_point(size=15,alpha=0.5)+
geom_text(aes(label=round(fum)),color='black')+
labs(caption="Source: OCDE données de santé 2019")+
coord_cartesian(ylim=c(0,50))+
theme_minimal()+
theme(axis.title = element_blank(),
axis.text.y = element_blank(),
panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_blank(),
plot.caption = element_text(face='italic'),
legend.position = 'none')
Ce type de graphe permet de comparer les valeurs des différentes modalités d’une variable de manière assez élégante. Les points peuvent également être mobilisés pour des graphes plus complexes permettant les comparaisons des valeurs des modalités d’une variables sur deux groupes à l’image du diagramme en bâtons divergents, empilés ou pairés.
Établissons-en un permettant de positionner les différents pays en fonction de leur différence en terme de proportion de fumeur par rapport à la moyenne de l’OCDE. Pour bien voir la différence avec un diagramme à bâtons commençons par en réaliser un divergeant avant de travailler avec des points. Calculons donc cette différence et marquons les cas où elle est négative. Assurons-nous également que les pays soient présentés dans l’ordre décroissant de leur proportion de fumeurs (Total).
dat$dif<-dat$Total-dat$Total[dat$pays=='OCDE (36)']
dat$psne<-dat$dif<0
dat$pays_f<-fct_rev(fct_reorder(factor(dat$pays),dat$Total))Profitons-en pour trouver une police de caractère plus jolie dans les google fonts (grâce au package showtext).
font_add_google("Montserrat", "Montserrat")
showtext_auto()Celle-ci fait allons-y pour le diagramme divergeant (avec quelque mise en forme quand même).
ggplot(dat)+aes(x=dif,y=pays_f,fill=psne)+
geom_bar(stat='identity')+
geom_richtext(aes(x=10,y='OCDE (36)'),
label="la proportion moyenne de <br> fumeur.ses dans l'OCDE est de 18%",
fill='white')+
labs(x="Différence en points de pourcentage par rapport à la moyenne de l'OCDE",
y="pays",
caption="Source: OCDE données de santé 2019")+
coord_cartesian(xlim=c(-22,22))+
theme_minimal()+
theme(text=element_text(family = "Montserrat"),
axis.title.y=element_text(angle=360,vjust = 1),
axis.text.y = element_text(hjust=0),
panel.grid = element_blank(),
plot.caption = element_text(face='italic'),
legend.position = 'none')## Warning in geom_richtext(aes(x = 10, y = "OCDE (36)"), label = "la proportion moyenne de <br> fumeur.ses dans l'OCDE est de 18%", : All aesthetics have length 1, but the data has 45 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.
Réalisons le même mais à partir de points et non de barres. Marquons la moyenne de l’OCDE par une droite verticale de couleur rouge et un texte rapide comme dans la diagramme précédent.
ggplot(dat)+aes(x=Total,y=pays_f,color=psne)+
geom_point()+
geom_vline(xintercept=dat$Total[pays=='OCDE (36)'],
col='red')+
geom_point(aes(x=Total[pays=='OCDE (36)'],
y='OCDE (36)'),col='red')+
geom_richtext(aes(x=30,y='OCDE (36)'),
label="la proportion moyenne de <br> fumeur.ses dans l'OCDE est de 18%",
fill='white',color='black')+
labs(x="Pourcentage de fumeur.ses dans les pays l'OCDE",
y="Pays",
caption="Source: OCDE données de santé 2019")+
theme_minimal()+
theme(text=element_text(family = "Montserrat"),
axis.title.y=element_text(angle=360,vjust = 1),
panel.grid = element_blank(),
plot.caption = element_text(face='italic'),
legend.position = 'none')## Warning in geom_point(aes(x = Total[pays == "OCDE (36)"], y = "OCDE (36)"), : All aesthetics have length 1, but the data has 45 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.## Warning in geom_richtext(aes(x = 30, y = "OCDE (36)"), label = "la proportion moyenne de <br> fumeur.ses dans l'OCDE est de 18%", : All aesthetics have length 1, but the data has 45 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.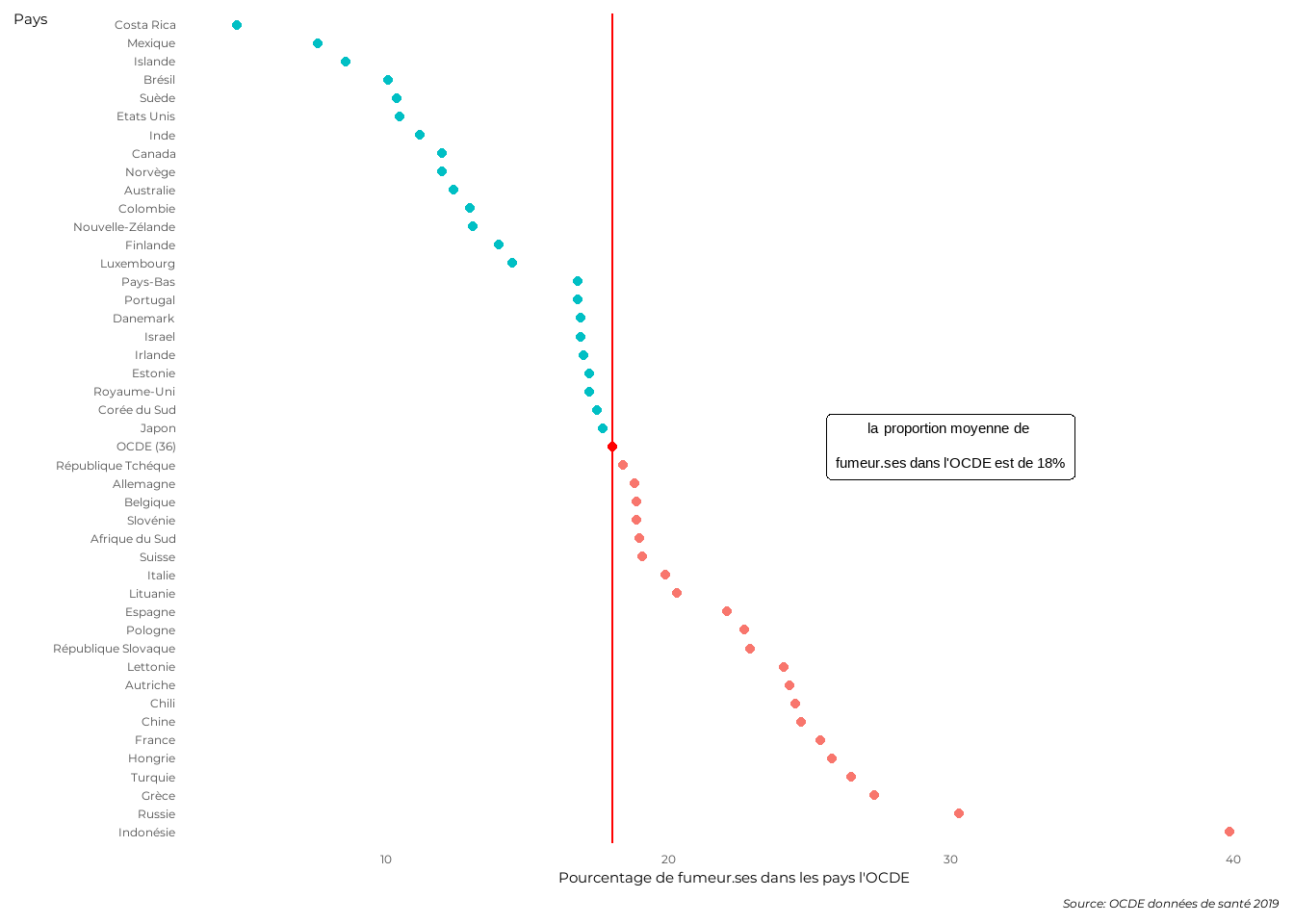
On obtient quelque chose de très comparable au graphe précédent, mais de beaucoup plus aéré. Par ailleurs, la modification d’échelle n’est pas ici nécessaire ce qui rend les choses plus simples (oui, nous aurions pu modifier l’axe des abscisses dans le diagramme à bâtons divergeant mais bon…).
Une alternative efficace pour représenter des groupes plus marqués (non issue de la variable centrale) est d’utiliser un diagramme en points connectés (connected dots plot). Voyons ce qu’il en est à partir de la proportion de fumeurs hommes et la proportion de fumeurs femmes. Classons les pays représentés en fonction de la différence hommes/femmes (de la plus petite différence à la plus grande). Reproduisons un graphe proposé par Anne M. Dzikowska. Allons progressivement.Utilisons des points orange pour les femmes et noir pour les hommes.
dat$dif_h_f<-dat$Men-dat$Women
dat$pays_h_f<-fct_rev(fct_reorder(factor(dat$pays),dat$dif_h_f))
ggplot(dat)+aes(y=pays_h_f)+
geom_point(aes(x=Women),color='orange')+
geom_point(aes(x=Men),color='black')+
labs(x="Pourcentage de fumeur.ses dans les pays l'OCDE",
y="Pays",
caption="*Source: OCDE données de santé 2019 <br>
Adapté d'un graphe d'Anne M. Dzikowska*")+
theme_minimal()+
theme(text=element_text(family = "Montserrat"),
plot.caption = element_markdown(),
axis.title.y=element_text(angle=360,vjust = 1),
panel.grid = element_blank())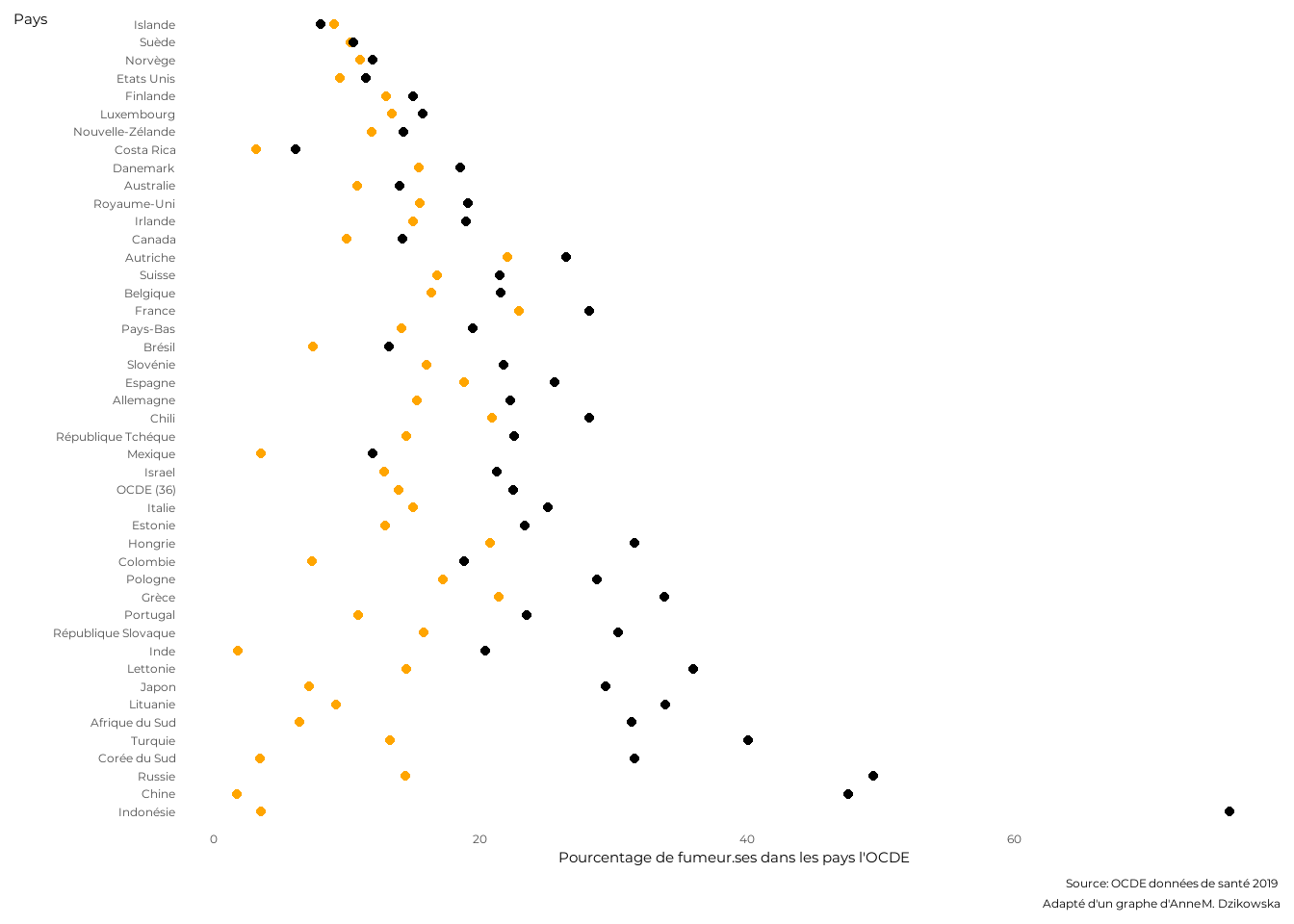
Les points sont un peu gros et on a du mal à les relier entre eux par pays. Réduisons leur taille et relions-les deux à deux par pays avec par des segments gris foncés.
ggplot(dat)+aes(y=pays_h_f)+
geom_segment(aes(x=Men,xend=Women,y=pays_h_f,yend=pays_h_f),
size=0.5,color='dark grey')+
geom_point(aes(x=Women),color='orange',size=0.5)+
geom_point(aes(x=Men),color='black',size=0.5)+
labs(x="Pourcentage de fumeur.ses dans les pays l'OCDE",
y="Pays",
caption="*Source: OCDE données de santé 2019 <br>
Adapté d'un graphe d'Anne M. Dzikowska*")+
theme_minimal()+
theme(text=element_text(family = "Montserrat"),
plot.caption = element_markdown(),
axis.title.y=element_text(angle=360,vjust = 1),
panel.grid = element_blank())## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
L’ensemble est élégant mais il manque un élément de légende permettant de poser que les points oranges concernent les femmes et les points noirs les hommes. Intégrons cette information sous la forme d’un commentaire portant sur deux pays particulier l’Islande et la Suède où les femmes fument plus que les hommes (très légèrement pour la Suède). Passons le fond du graphe en gris claire pour faire ressortir les couleurs.
ggplot(dat)+aes(y=pays_h_f)+
geom_segment(aes(x=Men,xend=Women,y=pays_h_f,yend=pays_h_f),
size=0.5,color='dark grey')+
geom_point(aes(x=Women),color='orange',size=0.5)+
geom_point(aes(x=Men),color='black',size=0.5)+
labs(title="En Islande et en Suéde, il y a plus de <span style=color:'orange'>**femmes**</span> de 15 ans et plus qui fument que d'**hommes**",
caption="*Source: OCDE données de santé 2019 <br>
Adapté d'un graphe d'Anne M. Dzikowska*",
x="Pourcentage de fumeur.ses dans les pays l'OCDE",
y="Pays")+
theme_minimal()+
theme(text=element_text(family = "Montserrat",size=12),
plot.title = element_markdown(),
plot.caption = element_markdown(),
axis.title.y=element_text(angle=360,vjust = 1),
plot.background = element_rect(fill='#EBEAE5'),
panel.grid = element_blank())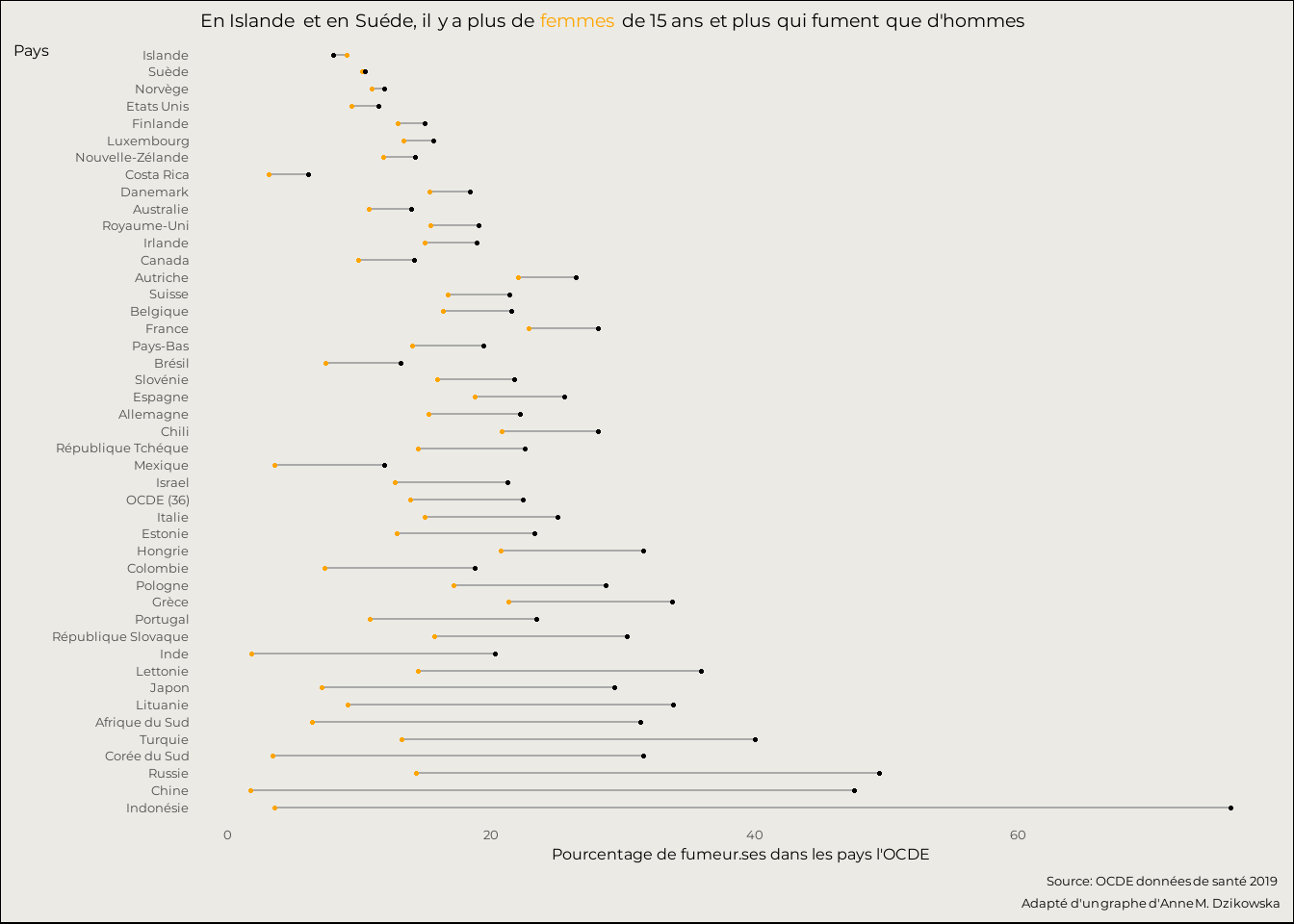
Voilà. Les possibilités d’exploiter le points (reliés ou non) à la place des barres (ou bâtons, pairés, empilés ou divergeant) pour illustrer des comparaisons entre catégorie sont multiples. Ce post n’en donne qu’un aperçu. Ces graphes présentent généralement l’avantage d’être plus aérés ce qui autorise pas mal de choses avant de submerger le lecteur de détails.